 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVMDT: Decoding the Trustworthiness of Video Foundation Models
Nov 07, 2025As foundation models become more sophisticated, ensuring their trustworthiness becomes increasingly critical; yet, unlike text and image, the video modality still lacks comprehensive trustworthiness benchmarks. We introduce VMDT (Video-Modal DecodingTrust), the first unified platform for evaluating text-to-video (T2V) and video-to-text (V2T) models across five key trustworthiness dimensions: safety, hallucination, fairness, privacy, and adversarial robustness. Through our extensive evaluation of 7 T2V models and 19 V2T models using VMDT, we uncover several significant insights. For instance, all open-source T2V models evaluated fail to recognize harmful queries and often generate harmful videos, while exhibiting higher levels of unfairness compared to image modality models. In V2T models, unfairness and privacy risks rise with scale, whereas hallucination and adversarial robustness improve -- though overall performance remains low. Uniquely, safety shows no correlation with model size, implying that factors other than scale govern current safety levels. Our findings highlight the urgent need for developing more robust and trustworthy video foundation models, and VMDT provides a systematic framework for measuring and tracking progress toward this goal. The code is available at https://sunblaze-ucb.github.io/VMDT-page/.
RepIt: Representing Isolated Targets to Steer Language Models
Sep 16, 2025While activation steering in large language models (LLMs) is a growing area of research, methods can often incur broader effects than desired. This motivates isolation of purer concept vectors to enable targeted interventions and understand LLM behavior at a more granular level. We present RepIt, a simple and data-efficient framework for isolating concept-specific representations. Across five frontier LLMs, RepIt enables precise interventions: it selectively suppresses refusal on targeted concepts while preserving refusal elsewhere, producing models that answer WMD-related questions while still scoring as safe on standard benchmarks. We further show that the corrective signal localizes to just 100-200 neurons and that robust target representations can be extracted from as few as a dozen examples on a single A6000. This efficiency raises a dual concern: manipulations can be performed with modest compute and data to extend to underrepresented data-scarce topics while evading existing benchmarks. By disentangling refusal vectors with RepIt, this work demonstrates that targeted interventions can counteract overgeneralization, laying the foundation for more granular control of model behavior.
MLAN: Language-Based Instruction Tuning Improves Zero-Shot Generalization of Multimodal Large Language Models
Nov 19, 2024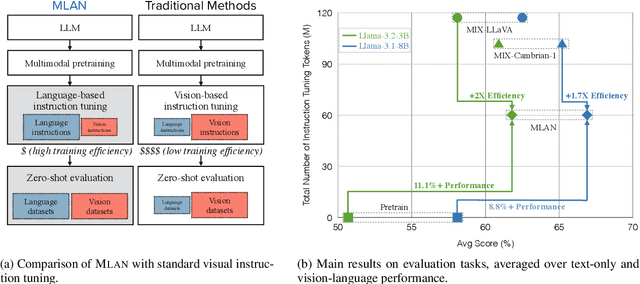
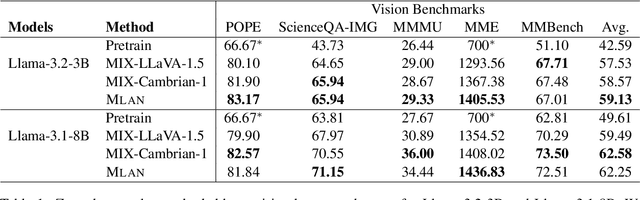
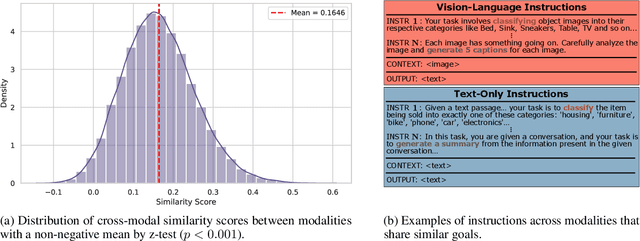
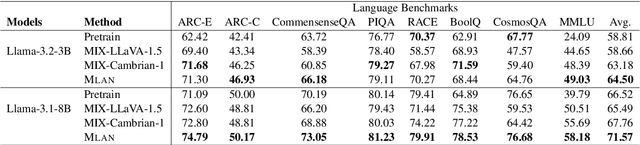
We present a novel instruction tuning recipe to improve the zero-shot task generalization of multimodal large language models. In contrast to existing instruction tuning mechanisms that heavily rely on visual instructions, our approach focuses on language-based instruction tuning, offering a distinct and more training efficient path for multimodal instruction tuning. We evaluate the performance of the proposed approach on 9 unseen datasets across both language and vision modalities. Our results show that our language-only instruction tuning is able to significantly improve the performance of two pretrained multimodal models based on Llama 2 and Vicuna on those unseen datasets. Interestingly, the language instruction following ability also helps unlock the models to follow vision instructions without explicit training. Compared to the state of the art multimodal instruction tuning approaches that are mainly based on visual instructions, our language-based method not only achieves superior performance but also significantly enhances training efficiency. For instance, the language-only instruction tuning produces competitive average performance across the evaluated datasets (with even better performance on language datasets) with significant training efficiency improvements (on average 4x), thanks to the striking reduction in the need for vision data. With a small number of visual instructions, this emerging language instruction following ability transfers well to the unseen vision datasets, outperforming the state of the art with greater training efficiency.
Agent Instructs Large Language Models to be General Zero-Shot Reasoners
Oct 05, 2023We introduce a method to improve the zero-shot reasoning abilities of large language models on general language understanding tasks. Specifically, we build an autonomous agent to instruct the reasoning process of large language models. We show this approach further unleashes the zero-shot reasoning abilities of large language models to more tasks. We study the performance of our method on a wide set of datasets spanning generation, classification, and reasoning. We show that our method generalizes to most tasks and obtains state-of-the-art zero-shot performance on 20 of the 29 datasets that we evaluate. For instance, our method boosts the performance of state-of-the-art large language models by a large margin, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%). Compared to zero-shot chain of thought, our improvement in reasoning is striking, with an average increase of 10.5%. With our method, Llama-2-70b-chat outperforms zero-shot GPT-3.5 Turbo by 10.2%.