 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan QPP Choose the Right Query Variant? Evaluating Query Variant Selection for RAG Pipelines
Apr 24, 2026Large Language Models (LLMs) have made query reformulation ubiquitous in modern retrieval and Retrieval-Augmented Generation (RAG) pipelines, enabling the generation of multiple semantically equivalent query variants. However, executing the full pipeline for every reformulation is computationally expensive, motivating selective execution: can we identify the best query variant before incurring downstream retrieval and generation costs? We investigate Query Performance Prediction (QPP) as a mechanism for variant selection across ad-hoc retrieval and end-to-end RAG. Unlike traditional QPP, which estimates query difficulty across topics, we study intra-topic discrimination - selecting the optimal reformulation among competing variants of the same information need. Through large-scale experiments on TREC-RAG using both sparse and dense retrievers, we evaluate pre- and post-retrieval predictors under correlation- and decision-based metrics. Our results reveal a systematic divergence between retrieval and generation objectives: variants that maximize ranking metrics such as nDCG often fail to produce the best generated answers, exposing a "utility gap" between retrieval relevance and generation fidelity. Nevertheless, QPP can reliably identify variants that improve end-to-end quality over the original query. Notably, lightweight pre-retrieval predictors frequently match or outperform more expensive post-retrieval methods, offering a latency-efficient approach to robust RAG.
OfficeQA Pro: An Enterprise Benchmark for End-to-End Grounded Reasoning
Mar 09, 2026We introduce OfficeQA Pro, a benchmark for evaluating AI agents on grounded, multi-document reasoning over a large and heterogeneous document corpus. The corpus consists of U.S. Treasury Bulletins spanning nearly 100 years, comprising 89,000 pages and over 26 million numerical values. OfficeQA Pro consists of 133 questions that require precise document parsing, retrieval, and analytical reasoning across both unstructured text and tabular data. Frontier LLMs including Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro Preview achieve less than 5% accuracy on OfficeQA Pro when relying on parametric knowledge, and less than 12% with additional access to the web. When provided directly with the document corpus, frontier agents still struggle on over half of questions, scoring 34.1% on average. We find that providing agents with a structured document representation produced by Databricks' ai_parse_document yields a 16.1% average relative performance gain across agents. We conduct additional ablations to study the effects of model selection, table representation, retrieval strategy, and test-time scaling on performance. Despite these improvements, significant headroom remains before agents can be considered reliable at enterprise-grade grounded reasoning.
KARL: Knowledge Agents via Reinforcement Learning
Mar 05, 2026We present a system for training enterprise search agents via reinforcement learning that achieves state-of-the-art performance across a diverse suite of hard-to-verify agentic search tasks. Our work makes four core contributions. First, we introduce KARLBench, a multi-capability evaluation suite spanning six distinct search regimes, including constraint-driven entity search, cross-document report synthesis, tabular numerical reasoning, exhaustive entity retrieval, procedural reasoning over technical documentation, and fact aggregation over internal enterprise notes. Second, we show that models trained across heterogeneous search behaviors generalize substantially better than those optimized for any single benchmark. Third, we develop an agentic synthesis pipeline that employs long-horizon reasoning and tool use to generate diverse, grounded, and high-quality training data, with iterative bootstrapping from increasingly capable models. Fourth, we propose a new post-training paradigm based on iterative large-batch off-policy RL that is sample efficient, robust to train-inference engine discrepancies, and naturally extends to multi-task training with out-of-distribution generalization. Compared to Claude 4.6 and GPT 5.2, KARL is Pareto-optimal on KARLBench across cost-quality and latency-quality trade-offs, including tasks that were out-of-distribution during training. With sufficient test-time compute, it surpasses the strongest closed models. These results show that tailored synthetic data in combination with multi-task reinforcement learning enables cost-efficient and high-performing knowledge agents for grounded reasoning.
Refract ICL: Rethinking Example Selection in the Era of Million-Token Models
Jun 14, 2025The emergence of long-context large language models (LLMs) has enabled the use of hundreds, or even thousands, of demonstrations for in-context learning (ICL) - a previously impractical regime. This paper investigates whether traditional ICL selection strategies, which balance the similarity of ICL examples to the test input (using a text retriever) with diversity within the ICL set, remain effective when utilizing a large number of demonstrations. Our experiments demonstrate that, while longer contexts can accommodate more examples, simply increasing the number of demonstrations does not guarantee improved performance. Smart ICL selection remains crucial, even with thousands of demonstrations. To further enhance ICL in this setting, we introduce Refract ICL, a novel ICL selection algorithm specifically designed to focus LLM attention on challenging examples by strategically repeating them within the context and incorporating zero-shot predictions as error signals. Our results show that Refract ICL significantly improves the performance of extremely long-context models such as Gemini 1.5 Pro, particularly on tasks with a smaller number of output classes.
Reasoning-Enhanced Self-Training for Long-Form Personalized Text Generation
Jan 07, 2025Personalized text generation requires a unique ability of large language models (LLMs) to learn from context that they often do not encounter during their standard training. One way to encourage LLMs to better use personalized context for generating outputs that better align with the user's expectations is to instruct them to reason over the user's past preferences, background knowledge, or writing style. To achieve this, we propose Reasoning-Enhanced Self-Training for Personalized Text Generation (REST-PG), a framework that trains LLMs to reason over personal data during response generation. REST-PG first generates reasoning paths to train the LLM's reasoning abilities and then employs Expectation-Maximization Reinforced Self-Training to iteratively train the LLM based on its own high-reward outputs. We evaluate REST-PG on the LongLaMP benchmark, consisting of four diverse personalized long-form text generation tasks. Our experiments demonstrate that REST-PG achieves significant improvements over state-of-the-art baselines, with an average relative performance gain of 14.5% on the benchmark.
Searching Personal Collections
Dec 16, 2024This article describes the history of information retrieval on personal document collections.
MLAN: Language-Based Instruction Tuning Improves Zero-Shot Generalization of Multimodal Large Language Models
Nov 19, 2024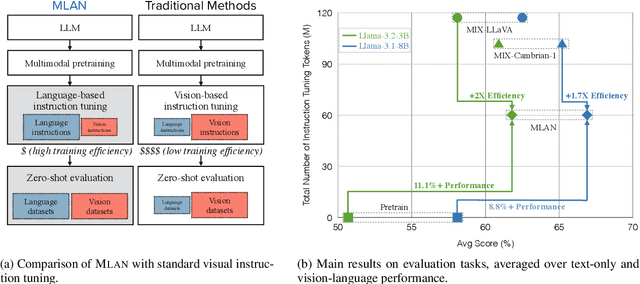
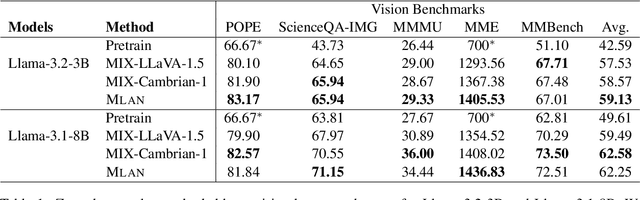
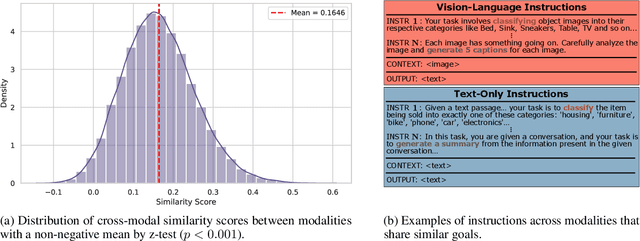
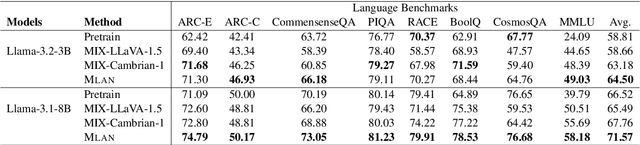
We present a novel instruction tuning recipe to improve the zero-shot task generalization of multimodal large language models. In contrast to existing instruction tuning mechanisms that heavily rely on visual instructions, our approach focuses on language-based instruction tuning, offering a distinct and more training efficient path for multimodal instruction tuning. We evaluate the performance of the proposed approach on 9 unseen datasets across both language and vision modalities. Our results show that our language-only instruction tuning is able to significantly improve the performance of two pretrained multimodal models based on Llama 2 and Vicuna on those unseen datasets. Interestingly, the language instruction following ability also helps unlock the models to follow vision instructions without explicit training. Compared to the state of the art multimodal instruction tuning approaches that are mainly based on visual instructions, our language-based method not only achieves superior performance but also significantly enhances training efficiency. For instance, the language-only instruction tuning produces competitive average performance across the evaluated datasets (with even better performance on language datasets) with significant training efficiency improvements (on average 4x), thanks to the striking reduction in the need for vision data. With a small number of visual instructions, this emerging language instruction following ability transfers well to the unseen vision datasets, outperforming the state of the art with greater training efficiency.
Integrating Planning into Single-Turn Long-Form Text Generation
Oct 08, 2024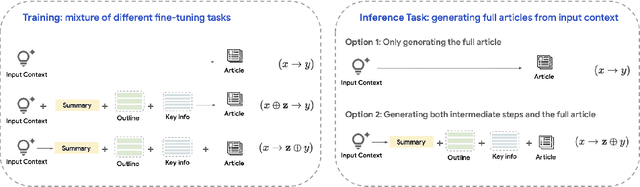

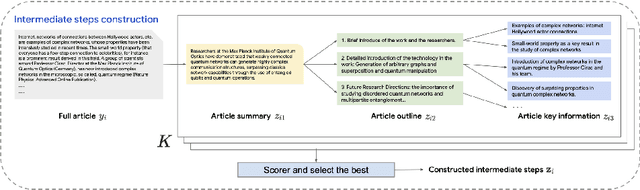
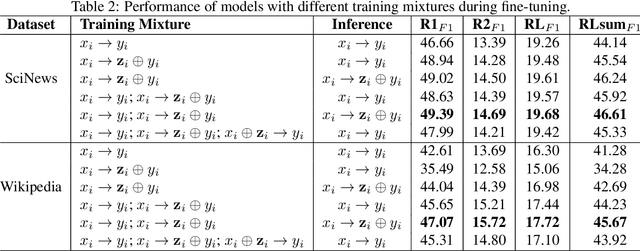
Generating high-quality, in-depth textual documents, such as academic papers, news articles, Wikipedia entries, and books, remains a significant challenge for Large Language Models (LLMs). In this paper, we propose to use planning to generate long form content. To achieve our goal, we generate intermediate steps via an auxiliary task that teaches the LLM to plan, reason and structure before generating the final text. Our main novelty lies in a single auxiliary task that does not require multiple rounds of prompting or planning. To overcome the scarcity of training data for these intermediate steps, we leverage LLMs to generate synthetic intermediate writing data such as outlines, key information and summaries from existing full articles. Our experiments demonstrate on two datasets from different domains, namely the scientific news dataset SciNews and Wikipedia datasets in KILT-Wiki and FreshWiki, that LLMs fine-tuned with the auxiliary task generate higher quality documents. We observed +2.5% improvement in ROUGE-Lsum, and a strong 3.60 overall win/loss ratio via human SxS evaluation, with clear wins in organization, relevance, and verifiability.
Inference Scaling for Long-Context Retrieval Augmented Generation
Oct 06, 2024



The scaling of inference computation has unlocked the potential of long-context large language models (LLMs) across diverse settings. For knowledge-intensive tasks, the increased compute is often allocated to incorporate more external knowledge. However, without effectively utilizing such knowledge, solely expanding context does not always enhance performance. In this work, we investigate inference scaling for retrieval augmented generation (RAG), exploring strategies beyond simply increasing the quantity of knowledge. We focus on two inference scaling strategies: in-context learning and iterative prompting. These strategies provide additional flexibility to scale test-time computation (e.g., by increasing retrieved documents or generation steps), thereby enhancing LLMs' ability to effectively acquire and utilize contextual information. We address two key questions: (1) How does RAG performance benefit from the scaling of inference computation when optimally configured? (2) Can we predict the optimal test-time compute allocation for a given budget by modeling the relationship between RAG performance and inference parameters? Our observations reveal that increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated, a relationship we describe as the inference scaling laws for RAG. Building on this, we further develop the computation allocation model to estimate RAG performance across different inference configurations. The model predicts optimal inference parameters under various computation constraints, which align closely with the experimental results. By applying these optimal configurations, we demonstrate that scaling inference compute on long-context LLMs achieves up to 58.9% gains on benchmark datasets compared to standard RAG.
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
Jul 23, 2024Retrieval Augmented Generation (RAG) has been a powerful tool for Large Language Models (LLMs) to efficiently process overly lengthy contexts. However, recent LLMs like Gemini-1.5 and GPT-4 show exceptional capabilities to understand long contexts directly. We conduct a comprehensive comparison between RAG and long-context (LC) LLMs, aiming to leverage the strengths of both. We benchmark RAG and LC across various public datasets using three latest LLMs. Results reveal that when resourced sufficiently, LC consistently outperforms RAG in terms of average performance. However, RAG's significantly lower cost remains a distinct advantage. Based on this observation, we propose Self-Route, a simple yet effective method that routes queries to RAG or LC based on model self-reflection. Self-Route significantly reduces the computation cost while maintaining a comparable performance to LC. Our findings provide a guideline for long-context applications of LLMs using RAG and LC.