 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritic-R: Improving Agentic Search using Instruction-tuned Retrievers with Natural Language Introspective Feedback
May 30, 2026Agentic search systems iteratively interact with retrieval models to answer complex queries. Despite substantial progress, optimizing retrievers for agentic search remains challenging, often requiring heavy co-training or gold-standard annotations that limit real-world applicability. We propose Critic-R, a framework that explicitly closes the feedback loop between the reasoning agent and the retrieval model during both inference and training. Critic-R introduces a critic model that evaluates the agent's introspective reasoning trace after consuming retrieved evidence to determine whether the retrieved context sufficiently supports the next reasoning step. Critic-R has two complementary mechanisms: Critic-R-Zero, an inference-time query refinement loop that iteratively rewrites queries and retrieval instructions, and Critic-Embed, an optimization approach for retrieval models that leverages successful and failed refinement trajectories as automatic supervision without requiring manual relevance annotation. We evaluate Critic-R on HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle. Results show that Critic-R significantly improves both retrieval quality and downstream answer accuracy.
GrepSeek: Training Search Agents for Direct Corpus Interaction
May 28, 2026Large Language Model (LLM) search agents have shown strong promise for knowledge-intensive language tasks through multiple rounds of reasoning and information retrieval. Most existing systems access information using a retriever that takes a keyword or natural language query and returns a ranked list of documents using an index of pre-computed document representations. In this work, we explore a complementary perspective in which the search agent treats the corpus itself as the search environment and finds evidence by issuing executable shell commands. We introduce GrepSeek, an optimized direct corpus interaction (DCI) search agent that trains a compact search agent to find, filter, and compose evidence from large text corpora. To address the instability of learning behavior directly with reinforcement learning on large corpora, we propose a two-stage training pipeline. First, we construct a cold-start dataset using an answer-aware Tutor and answer-blind Planner to generate verified, causally grounded search trajectories. Second, we refine the initialized policy with Group Relative Policy Optimization (GRPO), allowing the agent to improve its task-oriented search behavior through direct interaction with the corpus. To make DCI practical at scale, we further use a semantics-preserving sharded-parallel execution engine that accelerates shell-based retrieval by up to $7.6\times$ while preserving byte-exact equivalence with sequential execution of the shell command. Experiments across seven open-domain question answering benchmarks show that GrepSeek achieves the strongest overall token-level $F_1$ and Exact Match. Our analysis also highlights the limitations of purely lexical interaction on queries with substantial surface-form variation, suggesting DCI as a practical and competitive method for search agents that can complement existing retrieval paradigms in the real world.
Evaluation of Agents under Simulated AI Marketplace Dynamics
Apr 15, 2026Modern information access ecosystems consist of mixtures of systems, such as retrieval systems and large language models, and increasingly rely on marketplaces to mediate access to models, tools, and data, making competition between systems inherent to deployment. In such settings, outcomes are shaped not only by benchmark quality but also by competitive pressure, including user switching, routing decisions, and operational constraints. Yet evaluation is still largely conducted on static benchmarks with accuracy-focused measures that assume systems operate in isolation. This mismatch makes it difficult to predict post-deployment success and obscures competitive effects such as early-adoption advantages and market dominance. We introduce Marketplace Evaluation, a simulation-based paradigm that evaluates information access systems as participants in a competitive marketplace. By simulating repeated interactions and evolving user and agent preferences, the framework enables longitudinal evaluation and marketplace-level metrics, such as retention and market share, that complement and can extend beyond traditional accuracy-based metrics. We formalize the framework and outline a research agenda, motivated by business and economics, around marketplace simulation, metrics, optimization, and adoption in evaluation campaigns like TREC.
Learning to Reason for Multi-Step Retrieval of Personal Context in Personalized Question Answering
Feb 22, 2026Personalization in Question Answering (QA) requires answers that are both accurate and aligned with users' background, preferences, and historical context. Existing state-of-the-art methods primarily rely on retrieval-augmented generation (RAG) solutions that construct personal context by retrieving relevant items from the user's profile. Existing methods use the user's query directly to retrieve personal documents, and such strategies often lead to surface-level personalization. We propose PR2 (Personalized Retrieval-Augmented Reasoning), a reinforcement learning framework that integrates reasoning and retrieval from personal context for personalization. PR2 learns adaptive retrieval-reasoning policies, determining when to retrieve, what evidence to retrieve from user profiles, and how to incorporate it into intermediate reasoning steps. By optimizing multi-turn reasoning trajectories under a personalized reward function, the framework reinforces reasoning paths that better align with user-specific preferences and contextual signals reflected by the reward model. Extensive experiments on the LaMP-QA benchmark using three LLMs show that PR2 consistently outperforms strong baselines, achieving an average relative improvement of 8.8%-12% in personalized QA.
Improving User Privacy in Personalized Generation: Client-Side Retrieval-Augmented Modification of Server-Side Generated Speculations
Jan 24, 2026Personalization is crucial for aligning Large Language Model (LLM) outputs with individual user preferences and background knowledge. State-of-the-art solutions are based on retrieval augmentation, where relevant context from a user profile is retrieved for LLM consumption. These methods deal with a trade-off between exposing retrieved private data to cloud providers and relying on less capable local models. We introduce $P^3$, an interactive framework for high-quality personalization without revealing private profiles to server-side LLMs. In $P^3$, a large server-side model generates a sequence of $k$ draft tokens based solely on the user query, while a small client-side model, with retrieval access to the user's private profile, evaluates and modifies these drafts to better reflect user preferences. This process repeats until an end token is generated. Experiments on LaMP-QA, a recent benchmark consisting of three personalized question answering datasets, show that $P^3$ consistently outperforms both non-personalized server-side and personalized client-side baselines, achieving statistically significant improvements of $7.4%$ to $9%$ on average. Importantly, $P^3$ recovers $90.3%$ to $95.7%$ of the utility of a ``leaky'' upper-bound scenario in which the full profile is exposed to the large server-side model. Privacy analyses, including linkability and attribute inference attacks, indicate that $P^3$ preserves the privacy of a non-personalized server-side model, introducing only marginal additional leakage ($1.5%$--$3.5%$) compared to submitting a query without any personal context. Additionally, the framework is efficient for edge deployment, with the client-side model generating only $9.2%$ of the total tokens. These results demonstrate that $P^3$ provides a practical, effective solution for personalized generation with improved privacy.
Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs
Oct 31, 2025Evaluating the abilities of large language models (LLMs) for tasks that require long-term memory and thus long-context reasoning, for example in conversational settings, is hampered by the existing benchmarks, which often lack narrative coherence, cover narrow domains, and only test simple recall-oriented tasks. This paper introduces a comprehensive solution to these challenges. First, we present a novel framework for automatically generating long (up to 10M tokens), coherent, and topically diverse conversations, accompanied by probing questions targeting a wide range of memory abilities. From this, we construct BEAM, a new benchmark comprising 100 conversations and 2,000 validated questions. Second, to enhance model performance, we propose LIGHT-a framework inspired by human cognition that equips LLMs with three complementary memory systems: a long-term episodic memory, a short-term working memory, and a scratchpad for accumulating salient facts. Our experiments on BEAM reveal that even LLMs with 1M token context windows (with and without retrieval-augmentation) struggle as dialogues lengthen. In contrast, LIGHT consistently improves performance across various models, achieving an average improvement of 3.5%-12.69% over the strongest baselines, depending on the backbone LLM. An ablation study further confirms the contribution of each memory component.
CIIR@LiveRAG 2025: Optimizing Multi-Agent Retrieval Augmented Generation through Self-Training
Jun 12, 2025This paper presents mRAG, a multi-agent retrieval-augmented generation (RAG) framework composed of specialized agents for subtasks such as planning, searching, reasoning, and coordination. Our system uses a self-training paradigm with reward-guided trajectory sampling to optimize inter-agent collaboration and enhance response generation. Evaluated on DataMorgana-derived datasets during the SIGIR 2025 LiveRAG competition, mRAG outperforms conventional RAG baselines. We further analyze competition outcomes and showcase the framework's strengths with case studies, demonstrating its efficacy for complex, real-world RAG tasks.
Plan-and-Refine: Diverse and Comprehensive Retrieval-Augmented Generation
Apr 10, 2025This paper studies the limitations of (retrieval-augmented) large language models (LLMs) in generating diverse and comprehensive responses, and introduces the Plan-and-Refine (P&R) framework based on a two phase system design. In the global exploration phase, P&R generates a diverse set of plans for the given input, where each plan consists of a list of diverse query aspects with corresponding additional descriptions. This phase is followed by a local exploitation phase that generates a response proposal for the input query conditioned on each plan and iteratively refines the proposal for improving the proposal quality. Finally, a reward model is employed to select the proposal with the highest factuality and coverage. We conduct our experiments based on the ICAT evaluation methodology--a recent approach for answer factuality and comprehensiveness evaluation. Experiments on the two diverse information seeking benchmarks adopted from non-factoid question answering and TREC search result diversification tasks demonstrate that P&R significantly outperforms baselines, achieving up to a 13.1% improvement on the ANTIQUE dataset and a 15.41% improvement on the TREC dataset. Furthermore, a smaller scale user study confirms the substantial efficacy of the P&R framework.
Personalized Generation In Large Model Era: A Survey
Mar 04, 2025In the era of large models, content generation is gradually shifting to Personalized Generation (PGen), tailoring content to individual preferences and needs. This paper presents the first comprehensive survey on PGen, investigating existing research in this rapidly growing field. We conceptualize PGen from a unified perspective, systematically formalizing its key components, core objectives, and abstract workflows. Based on this unified perspective, we propose a multi-level taxonomy, offering an in-depth review of technical advancements, commonly used datasets, and evaluation metrics across multiple modalities, personalized contexts, and tasks. Moreover, we envision the potential applications of PGen and highlight open challenges and promising directions for future exploration. By bridging PGen research across multiple modalities, this survey serves as a valuable resource for fostering knowledge sharing and interdisciplinary collaboration, ultimately contributing to a more personalized digital landscape.
ExPerT: Effective and Explainable Evaluation of Personalized Long-Form Text Generation
Jan 24, 2025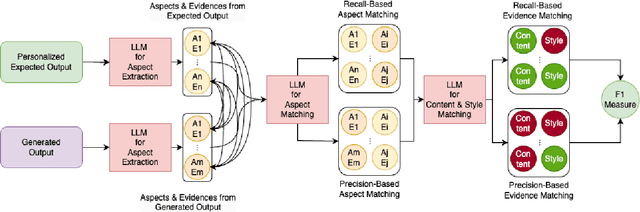
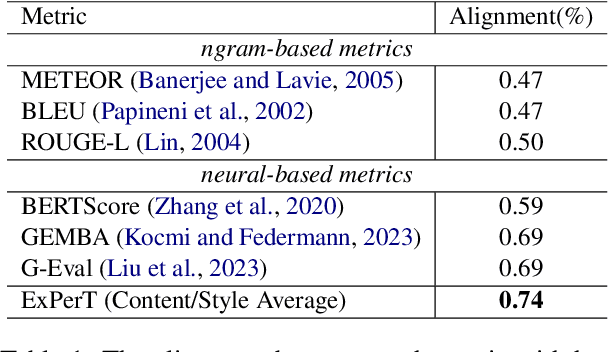
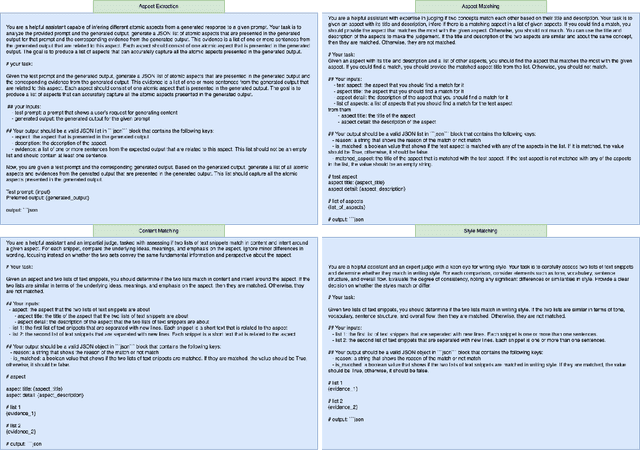

Evaluating personalized text generated by large language models (LLMs) is challenging, as only the LLM user, i.e., prompt author, can reliably assess the output, but re-engaging the same individuals across studies is infeasible. This paper addresses the challenge of evaluating personalized text generation by introducing ExPerT, an explainable reference-based evaluation framework. ExPerT leverages an LLM to extract atomic aspects and their evidence from the generated and reference texts, match the aspects, and evaluate their alignment based on content and writing style -- two key attributes in personalized text generation. Additionally, ExPerT generates detailed, fine-grained explanations for every step of the evaluation process, enhancing transparency and interpretability. Our experiments demonstrate that ExPerT achieves a 7.2% relative improvement in alignment with human judgments compared to the state-of-the-art text generation evaluation methods. Furthermore, human evaluators rated the usability of ExPerT's explanations at 4.7 out of 5, highlighting its effectiveness in making evaluation decisions more interpretable.