 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Embedding Dimension in Information Retrieval
Feb 04, 2026Dense retrieval, which encodes queries and documents into a single dense vector, has become the dominant neural retrieval approach due to its simplicity and compatibility with fast approximate nearest neighbor algorithms. As the tasks dense retrieval performs grow in complexity, the fundamental limitations of the underlying data structure and similarity metric -- namely vectors and inner-products -- become more apparent. Prior recent work has shown theoretical limitations inherent to single vectors and inner-products that are generally tied to the embedding dimension. Given the importance of embedding dimension for retrieval capacity, understanding how dense retrieval performance changes as embedding dimension is scaled is fundamental to building next generation retrieval models that balance effectiveness and efficiency. In this work, we conduct a comprehensive analysis of the relationship between embedding dimension and retrieval performance. Our experiments include two model families and a range of model sizes from each to construct a detailed picture of embedding scaling behavior. We find that the scaling behavior fits a power law, allowing us to derive scaling laws for performance given only embedding dimension, as well as a joint law accounting for embedding dimension and model size. Our analysis shows that for evaluation tasks aligned with the training task, performance continues to improve as embedding size increases, though with diminishing returns. For evaluation data that is less aligned with the training task, we find that performance is less predictable, with performance degrading with larger embedding dimensions for certain tasks. We hope our work provides additional insight into the limitations of embeddings and their behavior as well as offers a practical guide for selecting model and embedding dimension to achieve optimal performance with reduced storage and compute costs.
Benchmarking Information Retrieval Models on Complex Retrieval Tasks
Sep 08, 2025Large language models (LLMs) are incredible and versatile tools for text-based tasks that have enabled countless, previously unimaginable, applications. Retrieval models, in contrast, have not yet seen such capable general-purpose models emerge. To achieve this goal, retrieval models must be able to perform complex retrieval tasks, where queries contain multiple parts, constraints, or requirements in natural language. These tasks represent a natural progression from the simple, single-aspect queries that are used in the vast majority of existing, commonly used evaluation sets. Complex queries naturally arise as people expect search systems to handle more specific and often ambitious information requests, as is demonstrated by how people use LLM-based information systems. Despite the growing desire for retrieval models to expand their capabilities in complex retrieval tasks, there exist limited resources to assess the ability of retrieval models on a comprehensive set of diverse complex tasks. The few resources that do exist feature a limited scope and often lack realistic settings making it hard to know the true capabilities of retrieval models on complex real-world retrieval tasks. To address this shortcoming and spur innovation in next-generation retrieval models, we construct a diverse and realistic set of complex retrieval tasks and benchmark a representative set of state-of-the-art retrieval models. Additionally, we explore the impact of LLM-based query expansion and rewriting on retrieval quality. Our results show that even the best models struggle to produce high-quality retrieval results with the highest average nDCG@10 of only 0.346 and R@100 of only 0.587 across all tasks. Although LLM augmentation can help weaker models, the strongest model has decreased performance across all metrics with all rewriting techniques.
Scaling Sparse and Dense Retrieval in Decoder-Only LLMs
Feb 21, 2025Scaling large language models (LLMs) has shown great potential for improving retrieval model performance; however, previous studies have mainly focused on dense retrieval trained with contrastive loss (CL), neglecting the scaling behavior of other retrieval paradigms and optimization techniques, such as sparse retrieval and knowledge distillation (KD). In this work, we conduct a systematic comparative study on how different retrieval paradigms (sparse vs. dense) and fine-tuning objectives (CL vs. KD vs. their combination) affect retrieval performance across different model scales. Using MSMARCO passages as the training dataset, decoder-only LLMs (Llama-3 series: 1B, 3B, 8B), and a fixed compute budget, we evaluate various training configurations on both in-domain (MSMARCO, TREC DL) and out-of-domain (BEIR) benchmarks. Our key findings reveal that: (1) Scaling behaviors emerge clearly only with CL, where larger models achieve significant performance gains, whereas KD-trained models show minimal improvement, performing similarly across the 1B, 3B, and 8B scales. (2) Sparse retrieval models consistently outperform dense retrieval across both in-domain (MSMARCO, TREC DL) and out-of-domain (BEIR) benchmarks, and they demonstrate greater robustness to imperfect supervised signals. (3) We successfully scale sparse retrieval models with the combination of CL and KD losses at 8B scale, achieving state-of-the-art (SOTA) results in all evaluation sets.
Hypencoder: Hypernetworks for Information Retrieval
Feb 07, 2025



The vast majority of retrieval models depend on vector inner products to produce a relevance score between a query and a document. This naturally limits the expressiveness of the relevance score that can be employed. We propose a new paradigm, instead of producing a vector to represent the query we produce a small neural network which acts as a learned relevance function. This small neural network takes in a representation of the document, in this paper we use a single vector, and produces a scalar relevance score. To produce the little neural network we use a hypernetwork, a network that produce the weights of other networks, as our query encoder or as we call it a Hypencoder. Experiments on in-domain search tasks show that Hypencoder is able to significantly outperform strong dense retrieval models and has higher metrics then reranking models and models an order of magnitude larger. Hypencoder is also shown to generalize well to out-of-domain search tasks. To assess the extent of Hypencoder's capabilities, we evaluate on a set of hard retrieval tasks including tip-of-the-tongue retrieval and instruction-following retrieval tasks and find that the performance gap widens substantially compared to standard retrieval tasks. Furthermore, to demonstrate the practicality of our method we implement an approximate search algorithm and show that our model is able to search 8.8M documents in under 60ms.
ExPerT: Effective and Explainable Evaluation of Personalized Long-Form Text Generation
Jan 24, 2025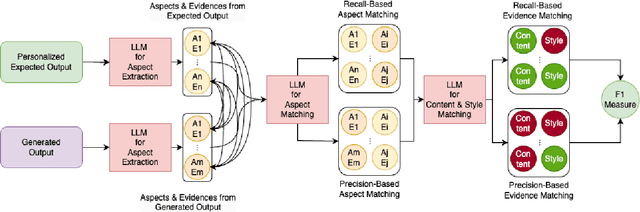
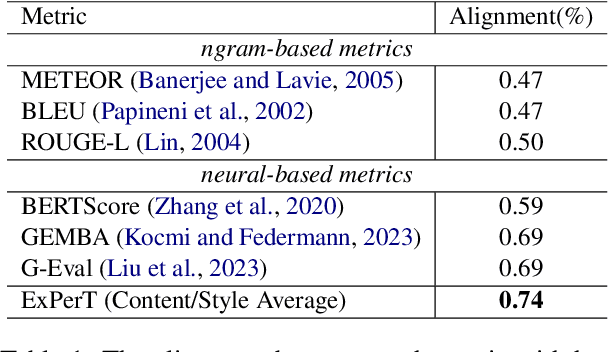
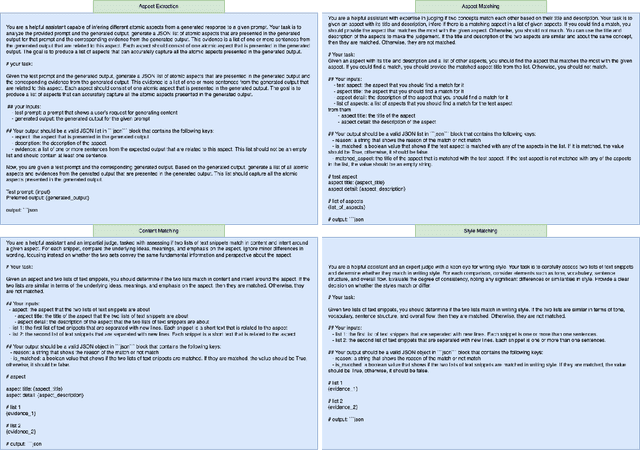

Evaluating personalized text generated by large language models (LLMs) is challenging, as only the LLM user, i.e., prompt author, can reliably assess the output, but re-engaging the same individuals across studies is infeasible. This paper addresses the challenge of evaluating personalized text generation by introducing ExPerT, an explainable reference-based evaluation framework. ExPerT leverages an LLM to extract atomic aspects and their evidence from the generated and reference texts, match the aspects, and evaluate their alignment based on content and writing style -- two key attributes in personalized text generation. Additionally, ExPerT generates detailed, fine-grained explanations for every step of the evaluation process, enhancing transparency and interpretability. Our experiments demonstrate that ExPerT achieves a 7.2% relative improvement in alignment with human judgments compared to the state-of-the-art text generation evaluation methods. Furthermore, human evaluators rated the usability of ExPerT's explanations at 4.7 out of 5, highlighting its effectiveness in making evaluation decisions more interpretable.
Simulating Task-Oriented Dialogues with State Transition Graphs and Large Language Models
Apr 23, 2024This paper explores SynTOD, a new synthetic data generation approach for developing end-to-end Task-Oriented Dialogue (TOD) Systems capable of handling complex tasks such as intent classification, slot filling, conversational question-answering, and retrieval-augmented response generation, without relying on crowdsourcing or real-world data. SynTOD utilizes a state transition graph to define the desired behavior of a TOD system and generates diverse, structured conversations through random walks and response simulation using large language models (LLMs). In our experiments, using graph-guided response simulations leads to significant improvements in intent classification, slot filling and response relevance compared to naive single-prompt simulated conversations. We also investigate the end-to-end TOD effectiveness of different base and instruction-tuned LLMs, with and without the constructed synthetic conversations. Finally, we explore how various LLMs can evaluate responses in a TOD system and how well they are correlated with human judgments. Our findings pave the path towards quick development and evaluation of domain-specific TOD systems. We release our datasets, models, and code for research purposes.