 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExPerT: Effective and Explainable Evaluation of Personalized Long-Form Text Generation
Paper and Code
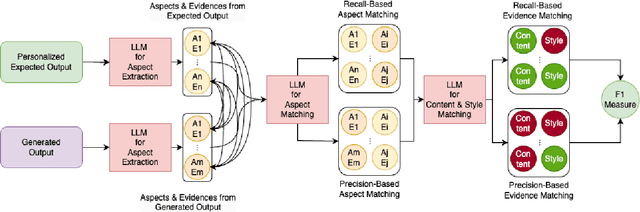
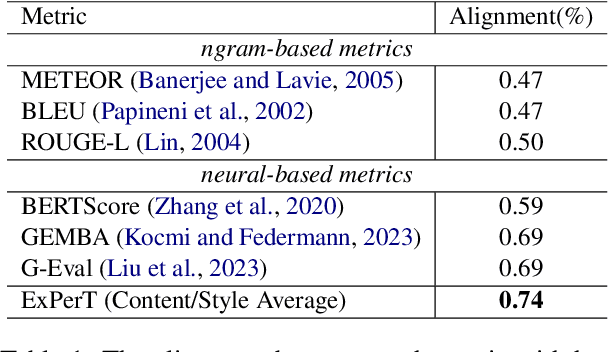
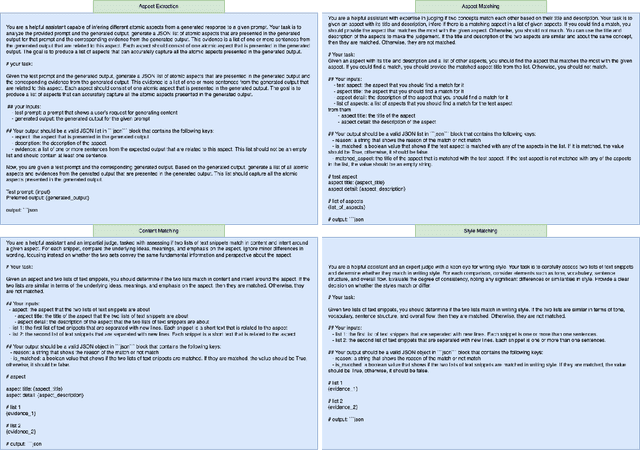

Evaluating personalized text generated by large language models (LLMs) is challenging, as only the LLM user, i.e., prompt author, can reliably assess the output, but re-engaging the same individuals across studies is infeasible. This paper addresses the challenge of evaluating personalized text generation by introducing ExPerT, an explainable reference-based evaluation framework. ExPerT leverages an LLM to extract atomic aspects and their evidence from the generated and reference texts, match the aspects, and evaluate their alignment based on content and writing style -- two key attributes in personalized text generation. Additionally, ExPerT generates detailed, fine-grained explanations for every step of the evaluation process, enhancing transparency and interpretability. Our experiments demonstrate that ExPerT achieves a 7.2% relative improvement in alignment with human judgments compared to the state-of-the-art text generation evaluation methods. Furthermore, human evaluators rated the usability of ExPerT's explanations at 4.7 out of 5, highlighting its effectiveness in making evaluation decisions more interpretable.