 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCustom: Unified Visual Conditioning for Multi-Reference Image Generation
May 13, 2026Multi-reference image generation aims to synthesize images from textual instructions while faithfully preserving subject identities from multiple reference images. Existing VLM-enhanced diffusion models commonly rely on decoupled visual conditioning: semantic ViT features are processed by the VLM for instruction understanding, whereas appearance-rich VAE features are injected later into the diffusion backbone. Despite its intuitive design, this separation makes it difficult for the model to associate each semantically grounded subject with visual details from the correct reference image. As a result, the model may recognize which subject is being referred to, but fail to preserve its identity and fine-grained appearance, leading to attribute leakage and cross-reference confusion in complex multi-reference settings. To address this issue, we propose UniCustom, a unified visual conditioning framework that fuses ViT and VAE features before VLM encoding. This early fusion exposes the VLM to both semantic cues and appearance-rich details, enabling its hidden states to jointly encode the referred subject and corresponding visual appearance with only a lightweight linear fusion layer. To learn such unified representations, we adopt a two-stage training strategy: reconstruction-oriented pretraining that preserves reference-specific appearance details in the fused hidden states, followed by supervised finetuning on single- and multi-reference generation tasks. We further introduce a slot-wise binding regularization that encourages each image slot to preserve low-level details of its corresponding reference, thereby reducing cross-reference entanglement. Experiments on two multi-reference generation benchmarks demonstrate that UniCustom consistently improves subject consistency, instruction following, and compositional fidelity over strong baselines.
NextAds: Towards Next-generation Personalized Video Advertising
Mar 02, 2026With the rapid growth of online video consumption, video advertising has become increasingly dominant in the digital advertising landscape. Yet diverse users and viewing contexts makes one-size-fits-all ad creatives insufficient for consistent effectiveness, underlining the importance of personalization. In practice, most personalized video advertising systems follow a retrieval-based paradigm, selecting the optimal one from a small set of professionally pre-produced creatives for each user. Such static and finite inventories limits both the granularity and the timeliness of personalization, and prevents the creatives from being continuously refined based on online user feedback. Recent advances in generative AI make it possible to move beyond retrieval toward optimizing video creatives in a continuous space at serving time. In this light, we propose NextAds, a generation-based paradigm for next-generation personalized video advertising, and conceptualize NextAds with four core components. To enable comparable research progress, we formulate two representative tasks: personalized creative generation and personalized creative integration, and introduce corresponding lightweight benchmarks. To assess feasibility, we instantiate end-to-end pipelines for both tasks and conduct initial exploratory experiments, demonstrating that GenAI can generate and integrate personalized creatives with encouraging performance. Moreover, we discuss the key challenges and opportunities under this paradigm, aiming to provide actionable insights for both researchers and practitioners and to catalyze progress in personalized video advertising.
Navigating Through Paper Flood: Advancing LLM-based Paper Evaluation through Domain-Aware Retrieval and Latent Reasoning
Aug 07, 2025With the rapid and continuous increase in academic publications, identifying high-quality research has become an increasingly pressing challenge. While recent methods leveraging Large Language Models (LLMs) for automated paper evaluation have shown great promise, they are often constrained by outdated domain knowledge and limited reasoning capabilities. In this work, we present PaperEval, a novel LLM-based framework for automated paper evaluation that addresses these limitations through two key components: 1) a domain-aware paper retrieval module that retrieves relevant concurrent work to support contextualized assessments of novelty and contributions, and 2) a latent reasoning mechanism that enables deep understanding of complex motivations and methodologies, along with comprehensive comparison against concurrently related work, to support more accurate and reliable evaluation. To guide the reasoning process, we introduce a progressive ranking optimization strategy that encourages the LLM to iteratively refine its predictions with an emphasis on relative comparison. Experiments on two datasets demonstrate that PaperEval consistently outperforms existing methods in both academic impact and paper quality evaluation. In addition, we deploy PaperEval in a real-world paper recommendation system for filtering high-quality papers, which has gained strong engagement on social media -- amassing over 8,000 subscribers and attracting over 10,000 views for many filtered high-quality papers -- demonstrating the practical effectiveness of PaperEval.
DRC: Enhancing Personalized Image Generation via Disentangled Representation Composition
Apr 24, 2025Personalized image generation has emerged as a promising direction in multimodal content creation. It aims to synthesize images tailored to individual style preferences (e.g., color schemes, character appearances, layout) and semantic intentions (e.g., emotion, action, scene contexts) by leveraging user-interacted history images and multimodal instructions. Despite notable progress, existing methods -- whether based on diffusion models, large language models, or Large Multimodal Models (LMMs) -- struggle to accurately capture and fuse user style preferences and semantic intentions. In particular, the state-of-the-art LMM-based method suffers from the entanglement of visual features, leading to Guidance Collapse, where the generated images fail to preserve user-preferred styles or reflect the specified semantics. To address these limitations, we introduce DRC, a novel personalized image generation framework that enhances LMMs through Disentangled Representation Composition. DRC explicitly extracts user style preferences and semantic intentions from history images and the reference image, respectively, to form user-specific latent instructions that guide image generation within LMMs. Specifically, it involves two critical learning stages: 1) Disentanglement learning, which employs a dual-tower disentangler to explicitly separate style and semantic features, optimized via a reconstruction-driven paradigm with difficulty-aware importance sampling; and 2) Personalized modeling, which applies semantic-preserving augmentations to effectively adapt the disentangled representations for robust personalized generation. Extensive experiments on two benchmarks demonstrate that DRC shows competitive performance while effectively mitigating the guidance collapse issue, underscoring the importance of disentangled representation learning for controllable and effective personalized image generation.
Personalized Generation In Large Model Era: A Survey
Mar 04, 2025In the era of large models, content generation is gradually shifting to Personalized Generation (PGen), tailoring content to individual preferences and needs. This paper presents the first comprehensive survey on PGen, investigating existing research in this rapidly growing field. We conceptualize PGen from a unified perspective, systematically formalizing its key components, core objectives, and abstract workflows. Based on this unified perspective, we propose a multi-level taxonomy, offering an in-depth review of technical advancements, commonly used datasets, and evaluation metrics across multiple modalities, personalized contexts, and tasks. Moreover, we envision the potential applications of PGen and highlight open challenges and promising directions for future exploration. By bridging PGen research across multiple modalities, this survey serves as a valuable resource for fostering knowledge sharing and interdisciplinary collaboration, ultimately contributing to a more personalized digital landscape.
Personalized Image Generation with Large Multimodal Models
Oct 18, 2024



Personalized content filtering, such as recommender systems, has become a critical infrastructure to alleviate information overload. However, these systems merely filter existing content and are constrained by its limited diversity, making it difficult to meet users' varied content needs. To address this limitation, personalized content generation has emerged as a promising direction with broad applications. Nevertheless, most existing research focuses on personalized text generation, with relatively little attention given to personalized image generation. The limited work in personalized image generation faces challenges in accurately capturing users' visual preferences and needs from noisy user-interacted images and complex multimodal instructions. Worse still, there is a lack of supervised data for training personalized image generation models. To overcome the challenges, we propose a Personalized Image Generation Framework named Pigeon, which adopts exceptional large multimodal models with three dedicated modules to capture users' visual preferences and needs from noisy user history and multimodal instructions. To alleviate the data scarcity, we introduce a two-stage preference alignment scheme, comprising masked preference reconstruction and pairwise preference alignment, to align Pigeon with the personalized image generation task. We apply Pigeon to personalized sticker and movie poster generation, where extensive quantitative results and human evaluation highlight its superiority over various generative baselines.
DiFashion: Towards Personalized Outfit Generation and Recommendation
Feb 29, 2024The evolution of Outfit Recommendation (OR) in the realm of fashion has progressed through two distinct phases: Pre-defined Outfit Recommendation and Personalized Outfit Composition. Despite these advancements, both phases face limitations imposed by existing fashion products, hindering their effectiveness in meeting users' diverse fashion needs. The emergence of AI-generated content has paved the way for OR to overcome these constraints, demonstrating the potential for personalized outfit generation. In pursuit of this, we introduce an innovative task named Generative Outfit Recommendation (GOR), with the goal of synthesizing a set of fashion images and assembling them to form visually harmonious outfits customized to individual users. The primary objectives of GOR revolve around achieving high fidelity, compatibility, and personalization of the generated outfits. To accomplish these, we propose DiFashion, a generative outfit recommender model that harnesses exceptional diffusion models for the simultaneous generation of multiple fashion images. To ensure the fulfillment of these objectives, three types of conditions are designed to guide the parallel generation process and Classifier-Free-Guidance are employed to enhance the alignment between generated images and conditions. DiFashion is applied to both personalized Fill-In-The-Blank and GOR tasks, and extensive experiments are conducted on the iFashion and Polyvore-U datasets. The results of quantitative and human-involved qualitative evaluations highlight the superiority of DiFashion over competitive baselines.
Plug-In Diffusion Model for Embedding Denoising in Recommendation System
Jan 29, 2024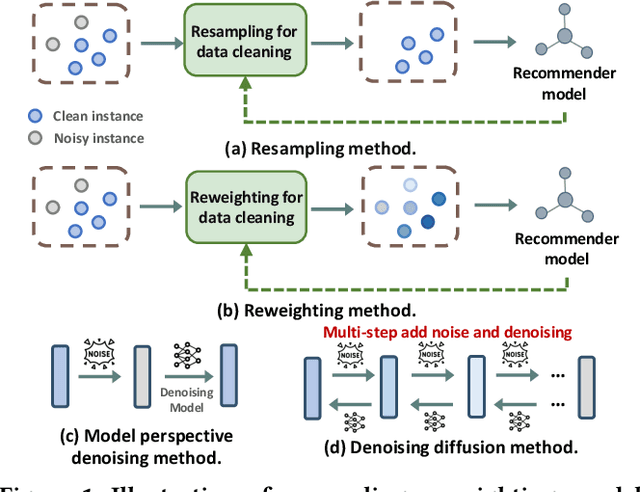

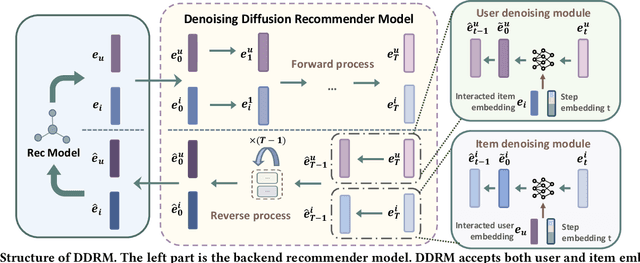
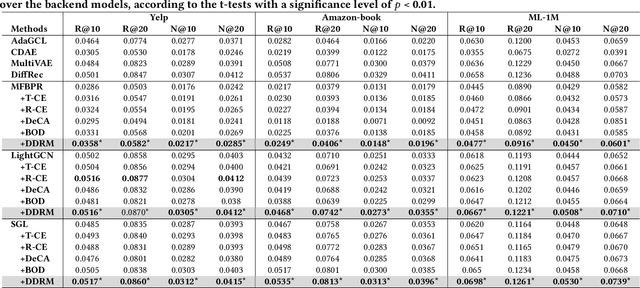
In the realm of recommender systems, handling noisy implicit feedback is a prevalent challenge. While most research efforts focus on mitigating noise through data cleaning methods like resampling and reweighting, these approaches often rely on heuristic assumptions. Alternatively, model perspective denoising strategies actively incorporate noise into user-item interactions, aiming to bolster the model's inherent denoising capabilities. Nonetheless, this type of denoising method presents substantial challenges to the capacity of the recommender model to accurately identify and represent noise patterns. To overcome these hurdles, we introduce a plug-in diffusion model for embedding denoising in recommendation system, which employs a multi-step denoising approach based on diffusion models to foster robust representation learning of embeddings. Our model operates by introducing controlled Gaussian noise into user and item embeddings derived from various recommender systems during the forward phase. Subsequently, it iteratively eliminates this noise in the reverse denoising phase, thereby augmenting the embeddings' resilience to noisy feedback. The primary challenge in this process is determining direction and an optimal starting point for the denoising process. To address this, we incorporate a specialized denoising module that utilizes collaborative data as a guide for the denoising process. Furthermore, during the inference phase, we employ the average of item embeddings previously favored by users as the starting point to facilitate ideal item generation. Our thorough evaluations across three datasets and in conjunction with three classic backend models confirm its superior performance.
Diffusion Recommender Model
Apr 17, 2023Generative models such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) are widely utilized to model the generative process of user interactions. However, these generative models suffer from intrinsic limitations such as the instability of GANs and the restricted representation ability of VAEs. Such limitations hinder the accurate modeling of the complex user interaction generation procedure, such as noisy interactions caused by various interference factors. In light of the impressive advantages of Diffusion Models (DMs) over traditional generative models in image synthesis, we propose a novel Diffusion Recommender Model (named DiffRec) to learn the generative process in a denoising manner. To retain personalized information in user interactions, DiffRec reduces the added noises and avoids corrupting users' interactions into pure noises like in image synthesis. In addition, we extend traditional DMs to tackle the unique challenges in practical recommender systems: high resource costs for large-scale item prediction and temporal shifts of user preference. To this end, we propose two extensions of DiffRec: L-DiffRec clusters items for dimension compression and conducts the diffusion processes in the latent space; and T-DiffRec reweights user interactions based on the interaction timestamps to encode temporal information. We conduct extensive experiments on three datasets under multiple settings (e.g. clean training, noisy training, and temporal training). The empirical results and in-depth analysis validate the superiority of DiffRec with two extensions over competitive baselines.
Mitigating Spurious Correlations for Self-supervised Recommendation
Dec 08, 2022Recent years have witnessed the great success of self-supervised learning (SSL) in recommendation systems. However, SSL recommender models are likely to suffer from spurious correlations, leading to poor generalization. To mitigate spurious correlations, existing work usually pursues ID-based SSL recommendation or utilizes feature engineering to identify spurious features. Nevertheless, ID-based SSL approaches sacrifice the positive impact of invariant features, while feature engineering methods require high-cost human labeling. To address the problems, we aim to automatically mitigate the effect of spurious correlations. This objective requires to 1) automatically mask spurious features without supervision, and 2) block the negative effect transmission from spurious features to other features during SSL. To handle the two challenges, we propose an invariant feature learning framework, which first divides user-item interactions into multiple environments with distribution shifts and then learns a feature mask mechanism to capture invariant features across environments. Based on the mask mechanism, we can remove the spurious features for robust predictions and block the negative effect transmission via mask-guided feature augmentation. Extensive experiments on two datasets demonstrate the effectiveness of the proposed framework in mitigating spurious correlations and improving the generalization abilities of SSL models.