 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCold-Starts in Generative Recommendation: A Reproducibility Study
Mar 31, 2026Cold-start recommendation remains a central challenge in dynamic, open-world platforms, requiring models to recommend for newly registered users (user cold-start) and to recommend newly introduced items to existing users (item cold-start) under sparse or missing interaction signals. Recent generative recommenders built on pre-trained language models (PLMs) are often expected to mitigate cold-start by using item semantic information (e.g., titles and descriptions) and test-time conditioning on limited user context. However, cold-start is rarely treated as a primary evaluation setting in existing studies, and reported gains are difficult to interpret because key design choices, such as model scale, identifier design, and training strategy, are frequently changed together. In this work, we present a systematic reproducibility study of generative recommendation under a unified suite of cold-start protocols.
Unifying Search and Recommendation in LLMs via Gradient Multi-Subspace Tuning
Jan 14, 2026Search and recommendation (S&R) are core to online platforms, addressing explicit intent through queries and modeling implicit intent from behaviors, respectively. Their complementary roles motivate a unified modeling paradigm. Early studies to unify S&R adopt shared encoders with task-specific heads, while recent efforts reframe item ranking in both S&R as conditional generation. The latter holds particular promise, enabling end-to-end optimization and leveraging the semantic understanding of LLMs. However, existing methods rely on full fine-tuning, which is computationally expensive and limits scalability. Parameter-efficient fine-tuning (PEFT) offers a more practical alternative but faces two critical challenges in unifying S&R: (1) gradient conflicts across tasks due to divergent optimization objectives, and (2) shifts in user intent understanding caused by overfitting to fine-tuning data, which distort general-domain knowledge and weaken LLM reasoning. To address the above issues, we propose Gradient Multi-Subspace Tuning (GEMS), a novel framework that unifies S&R with LLMs while alleviating gradient conflicts and preserving general-domain knowledge. GEMS introduces (1) \textbf{Multi-Subspace Decomposition}, which disentangles shared and task-specific optimization signals into complementary low-rank subspaces, thereby reducing destructive gradient interference, and (2) \textbf{Null-Space Projection}, which constrains parameter updates to a subspace orthogonal to the general-domain knowledge space, mitigating shifts in user intent understanding. Extensive experiments on benchmark datasets show that GEMS consistently outperforms the state-of-the-art baselines across both search and recommendation tasks, achieving superior effectiveness.
Understanding Accuracy-Fairness Trade-offs in Re-ranking through Elasticity in Economics
Apr 21, 2025Fairness is an increasingly important factor in re-ranking tasks. Prior work has identified a trade-off between ranking accuracy and item fairness. However, the underlying mechanisms are still not fully understood. An analogy can be drawn between re-ranking and the dynamics of economic transactions. The accuracy-fairness trade-off parallels the coupling of the commodity tax transfer process. Fairness considerations in re-ranking, similar to a commodity tax on suppliers, ultimately translate into a cost passed on to consumers. Analogously, item-side fairness constraints result in a decline in user-side accuracy. In economics, the extent to which commodity tax on the supplier (item fairness) transfers to commodity tax on users (accuracy loss) is formalized using the notion of elasticity. The re-ranking fairness-accuracy trade-off is similarly governed by the elasticity of utility between item groups. This insight underscores the limitations of current fair re-ranking evaluations, which often rely solely on a single fairness metric, hindering comprehensive assessment of fair re-ranking algorithms. Centered around the concept of elasticity, this work presents two significant contributions. We introduce the Elastic Fairness Curve (EF-Curve) as an evaluation framework. This framework enables a comparative analysis of algorithm performance across different elasticity levels, facilitating the selection of the most suitable approach. Furthermore, we propose ElasticRank, a fair re-ranking algorithm that employs elasticity calculations to adjust inter-item distances within a curved space. Experiments on three widely used ranking datasets demonstrate its effectiveness and efficiency.
Unifying Search and Recommendation: A Generative Paradigm Inspired by Information Theory
Apr 09, 2025Recommender systems and search engines serve as foundational elements of online platforms, with the former delivering information proactively and the latter enabling users to seek information actively. Unifying both tasks in a shared model is promising since it can enhance user modeling and item understanding. Previous approaches mainly follow a discriminative paradigm, utilizing shared encoders to process input features and task-specific heads to perform each task. However, this paradigm encounters two key challenges: gradient conflict and manual design complexity. From the information theory perspective, these challenges potentially both stem from the same issue -- low mutual information between the input features and task-specific outputs during the optimization process. To tackle these issues, we propose GenSR, a novel generative paradigm for unifying search and recommendation (S&R), which leverages task-specific prompts to partition the model's parameter space into subspaces, thereby enhancing mutual information. To construct effective subspaces for each task, GenSR first prepares informative representations for each subspace and then optimizes both subspaces in one unified model. Specifically, GenSR consists of two main modules: (1) Dual Representation Learning, which independently models collaborative and semantic historical information to derive expressive item representations; and (2) S&R Task Unifying, which utilizes contrastive learning together with instruction tuning to generate task-specific outputs effectively. Extensive experiments on two public datasets show GenSR outperforms state-of-the-art methods across S&R tasks. Our work introduces a new generative paradigm compared with previous discriminative methods and establishes its superiority from the mutual information perspective.
LLM-based Federated Recommendation
Feb 17, 2024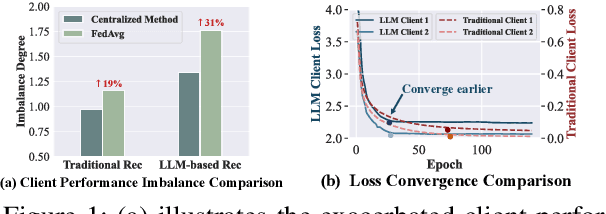
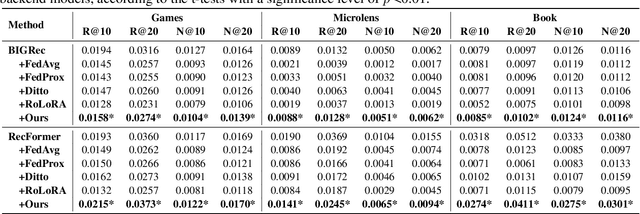
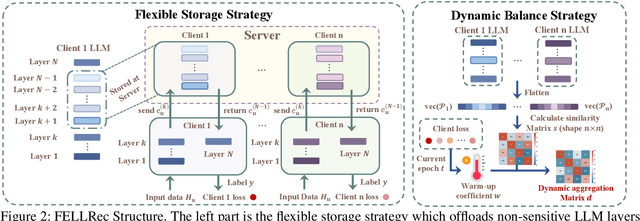
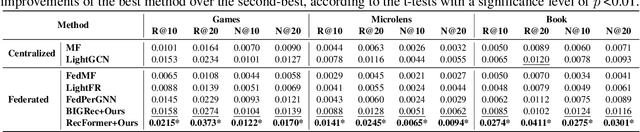
Large Language Models (LLMs), with their advanced contextual understanding abilities, have demonstrated considerable potential in enhancing recommendation systems via fine-tuning methods. However, fine-tuning requires users' behavior data, which poses considerable privacy risks due to the incorporation of sensitive user information. The unintended disclosure of such data could infringe upon data protection laws and give rise to ethical issues. To mitigate these privacy issues, Federated Learning for Recommendation (Fed4Rec) has emerged as a promising approach. Nevertheless, applying Fed4Rec to LLM-based recommendation presents two main challenges: first, an increase in the imbalance of performance across clients, affecting the system's efficiency over time, and second, a high demand on clients' computational and storage resources for local training and inference of LLMs. To address these challenges, we introduce a Privacy-Preserving LLM-based Recommendation (PPLR) framework. The PPLR framework employs two primary strategies. First, it implements a dynamic balance strategy, which involves the design of dynamic parameter aggregation and adjustment of learning speed for different clients during the training phase, to ensure relatively balanced performance across all clients. Second, PPLR adopts a flexible storage strategy, selectively retaining certain sensitive layers of the language model on the client side while offloading non-sensitive layers to the server. This approach aims to preserve user privacy while efficiently saving computational and storage resources. Experimental results demonstrate that PPLR not only achieves a balanced performance among clients but also enhances overall system performance in a manner that is both computationally and storage-efficient, while effectively protecting user privacy.
Plug-In Diffusion Model for Embedding Denoising in Recommendation System
Jan 29, 2024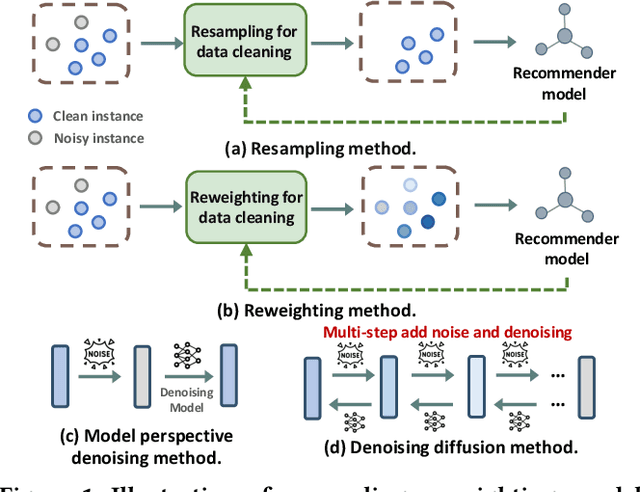

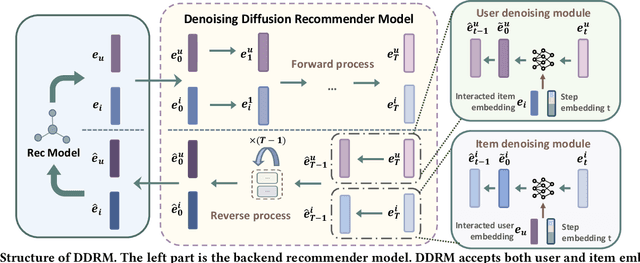
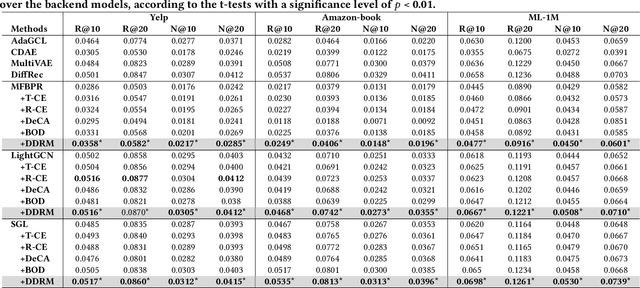
In the realm of recommender systems, handling noisy implicit feedback is a prevalent challenge. While most research efforts focus on mitigating noise through data cleaning methods like resampling and reweighting, these approaches often rely on heuristic assumptions. Alternatively, model perspective denoising strategies actively incorporate noise into user-item interactions, aiming to bolster the model's inherent denoising capabilities. Nonetheless, this type of denoising method presents substantial challenges to the capacity of the recommender model to accurately identify and represent noise patterns. To overcome these hurdles, we introduce a plug-in diffusion model for embedding denoising in recommendation system, which employs a multi-step denoising approach based on diffusion models to foster robust representation learning of embeddings. Our model operates by introducing controlled Gaussian noise into user and item embeddings derived from various recommender systems during the forward phase. Subsequently, it iteratively eliminates this noise in the reverse denoising phase, thereby augmenting the embeddings' resilience to noisy feedback. The primary challenge in this process is determining direction and an optimal starting point for the denoising process. To address this, we incorporate a specialized denoising module that utilizes collaborative data as a guide for the denoising process. Furthermore, during the inference phase, we employ the average of item embeddings previously favored by users as the starting point to facilitate ideal item generation. Our thorough evaluations across three datasets and in conjunction with three classic backend models confirm its superior performance.
Temporally and Distributionally Robust Optimization for Cold-start Recommendation
Dec 22, 2023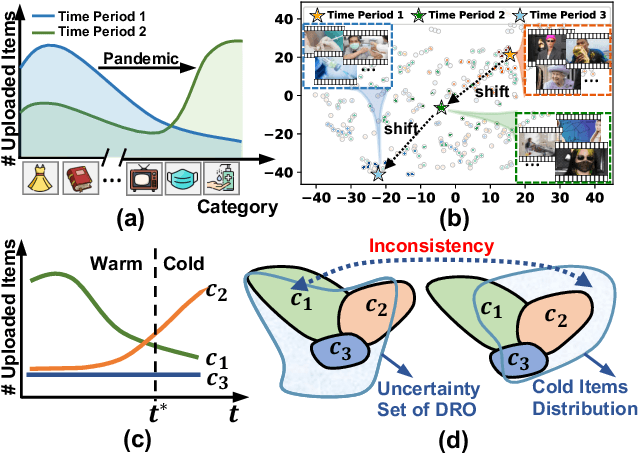
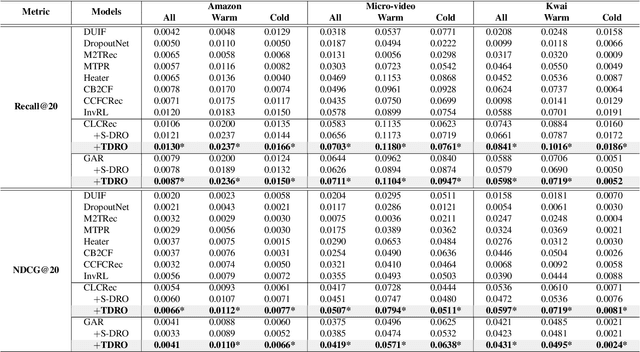
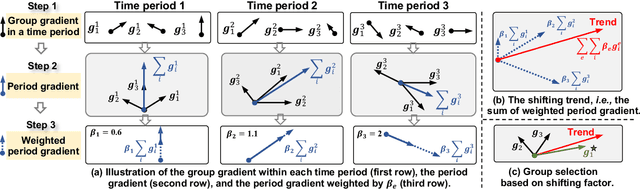

Collaborative Filtering (CF) recommender models highly depend on user-item interactions to learn CF representations, thus falling short of recommending cold-start items. To address this issue, prior studies mainly introduce item features (e.g., thumbnails) for cold-start item recommendation. They learn a feature extractor on warm-start items to align feature representations with interactions, and then leverage the feature extractor to extract the feature representations of cold-start items for interaction prediction. Unfortunately, the features of cold-start items, especially the popular ones, tend to diverge from those of warm-start ones due to temporal feature shifts, preventing the feature extractor from accurately learning feature representations of cold-start items. To alleviate the impact of temporal feature shifts, we consider using Distributionally Robust Optimization (DRO) to enhance the generation ability of the feature extractor. Nonetheless, existing DRO methods face an inconsistency issue: the worse-case warm-start items emphasized during DRO training might not align well with the cold-start item distribution. To capture the temporal feature shifts and combat this inconsistency issue, we propose a novel temporal DRO with new optimization objectives, namely, 1) to integrate a worst-case factor to improve the worst-case performance, and 2) to devise a shifting factor to capture the shifting trend of item features and enhance the optimization of the potentially popular groups in cold-start items. Substantial experiments on three real-world datasets validate the superiority of our temporal DRO in enhancing the generalization ability of cold-start recommender models. The code is available at https://github.com/Linxyhaha/TDRO/.