 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Anomaly Detection in Brain MRI via Disentangled Anatomy Learning
Dec 26, 2025Detection of various lesions in brain MRI is clinically critical, but challenging due to the diversity of lesions and variability in imaging conditions. Current unsupervised learning methods detect anomalies mainly through reconstructing abnormal images into pseudo-healthy images (PHIs) by normal samples learning and then analyzing differences between images. However, these unsupervised models face two significant limitations: restricted generalizability to multi-modality and multi-center MRIs due to their reliance on the specific imaging information in normal training data, and constrained performance due to abnormal residuals propagated from input images to reconstructed PHIs. To address these limitations, two novel modules are proposed, forming a new PHI reconstruction framework. Firstly, the disentangled representation module is proposed to improve generalizability by decoupling brain MRI into imaging information and essential imaging-invariant anatomical images, ensuring that the reconstruction focuses on the anatomy. Specifically, brain anatomical priors and a differentiable one-hot encoding operator are introduced to constrain the disentanglement results and enhance the disentanglement stability. Secondly, the edge-to-image restoration module is designed to reconstruct high-quality PHIs by restoring the anatomical representation from the high-frequency edge information of anatomical images, and then recoupling the disentangled imaging information. This module not only suppresses abnormal residuals in PHI by reducing abnormal pixels input through edge-only input, but also effectively reconstructs normal regions using the preserved structural details in the edges. Evaluated on nine public datasets (4,443 patients' MRIs from multiple centers), our method outperforms 17 SOTA methods, achieving absolute improvements of +18.32% in AP and +13.64% in DSC.
* Accepted by Medical Image Analysis (2025)
Ego-R1: Chain-of-Tool-Thought for Ultra-Long Egocentric Video Reasoning
Jun 16, 2025We introduce Ego-R1, a novel framework for reasoning over ultra-long (i.e., in days and weeks) egocentric videos, which leverages a structured Chain-of-Tool-Thought (CoTT) process, orchestrated by an Ego-R1 Agent trained via reinforcement learning (RL). Inspired by human problem-solving strategies, CoTT decomposes complex reasoning into modular steps, with the RL agent invoking specific tools, one per step, to iteratively and collaboratively answer sub-questions tackling such tasks as temporal retrieval and multi-modal understanding. We design a two-stage training paradigm involving supervised finetuning (SFT) of a pretrained language model using CoTT data and RL to enable our agent to dynamically propose step-by-step tools for long-range reasoning. To facilitate training, we construct a dataset called Ego-R1 Data, which consists of Ego-CoTT-25K for SFT and Ego-QA-4.4K for RL. Furthermore, our Ego-R1 agent is evaluated on a newly curated week-long video QA benchmark, Ego-R1 Bench, which contains human-verified QA pairs from hybrid sources. Extensive results demonstrate that the dynamic, tool-augmented chain-of-thought reasoning by our Ego-R1 Agent can effectively tackle the unique challenges of understanding ultra-long egocentric videos, significantly extending the time coverage from few hours to a week.
Unifying Search and Recommendation: A Generative Paradigm Inspired by Information Theory
Apr 09, 2025Recommender systems and search engines serve as foundational elements of online platforms, with the former delivering information proactively and the latter enabling users to seek information actively. Unifying both tasks in a shared model is promising since it can enhance user modeling and item understanding. Previous approaches mainly follow a discriminative paradigm, utilizing shared encoders to process input features and task-specific heads to perform each task. However, this paradigm encounters two key challenges: gradient conflict and manual design complexity. From the information theory perspective, these challenges potentially both stem from the same issue -- low mutual information between the input features and task-specific outputs during the optimization process. To tackle these issues, we propose GenSR, a novel generative paradigm for unifying search and recommendation (S&R), which leverages task-specific prompts to partition the model's parameter space into subspaces, thereby enhancing mutual information. To construct effective subspaces for each task, GenSR first prepares informative representations for each subspace and then optimizes both subspaces in one unified model. Specifically, GenSR consists of two main modules: (1) Dual Representation Learning, which independently models collaborative and semantic historical information to derive expressive item representations; and (2) S&R Task Unifying, which utilizes contrastive learning together with instruction tuning to generate task-specific outputs effectively. Extensive experiments on two public datasets show GenSR outperforms state-of-the-art methods across S&R tasks. Our work introduces a new generative paradigm compared with previous discriminative methods and establishes its superiority from the mutual information perspective.
3D Vessel Segmentation with Limited Guidance of 2D Structure-agnostic Vessel Annotations
Feb 07, 2023



Delineating 3D blood vessels is essential for clinical diagnosis and treatment, however, is challenging due to complex structure variations and varied imaging conditions. Supervised deep learning has demonstrated its superior capacity in automatic 3D vessel segmentation. However, the reliance on expensive 3D manual annotations and limited capacity for annotation reuse hinder the clinical applications of supervised models. To avoid the repetitive and laborious annotating and make full use of existing vascular annotations, this paper proposes a novel 3D shape-guided local discrimination model for 3D vascular segmentation under limited guidance from public 2D vessel annotations. The primary hypothesis is that 3D vessels are composed of semantically similar voxels and exhibit tree-shaped morphology. Accordingly, the 3D region discrimination loss is firstly proposed to learn the discriminative representation measuring voxel-wise similarities and cluster semantically consistent voxels to form the candidate 3D vascular segmentation in unlabeled images; secondly, based on the similarity of the tree-shaped morphology between 2D and 3D vessels, the Crop-and-Overlap strategy is presented to generate reference masks from 2D structure-agnostic vessel annotations, which are fit for varied vascular structures, and the adversarial loss is introduced to guide the tree-shaped morphology of 3D vessels; thirdly, the temporal consistency loss is proposed to foster the training stability and keep the model updated smoothly. To further enhance the model's robustness and reliability, the orientation-invariant CNN module and Reliability-Refinement algorithm are presented. Experimental results from the public 3D cerebrovascular and 3D arterial tree datasets demonstrate that our model achieves comparable effectiveness against nine supervised models.
YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
Aug 04, 2022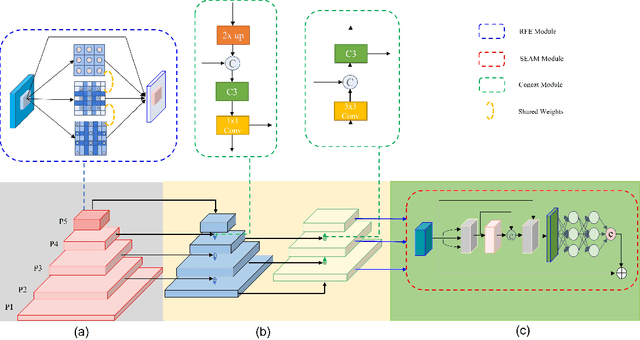
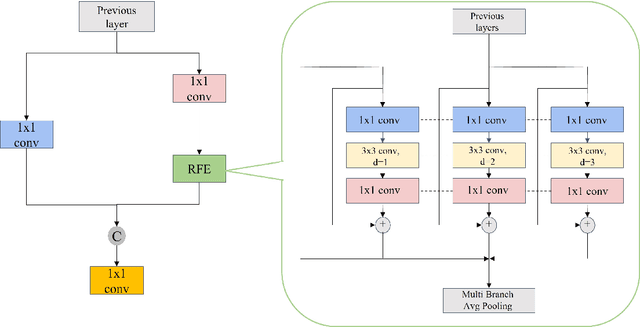
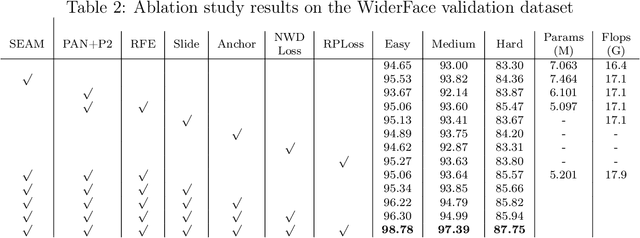
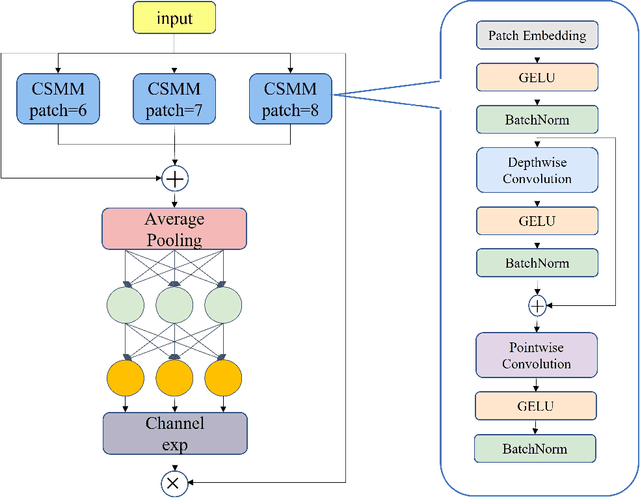
In recent years, face detection algorithms based on deep learning have made great progress. These algorithms can be generally divided into two categories, i.e. two-stage detector like Faster R-CNN and one-stage detector like YOLO. Because of the better balance between accuracy and speed, one-stage detectors have been widely used in many applications. In this paper, we propose a real-time face detector based on the one-stage detector YOLOv5, named YOLO-FaceV2. We design a Receptive Field Enhancement module called RFE to enhance receptive field of small face, and use NWD Loss to make up for the sensitivity of IoU to the location deviation of tiny objects. For face occlusion, we present an attention module named SEAM and introduce Repulsion Loss to solve it. Moreover, we use a weight function Slide to solve the imbalance between easy and hard samples and use the information of the effective receptive field to design the anchor. The experimental results on WiderFace dataset show that our face detector outperforms YOLO and its variants can be find in all easy, medium and hard subsets. Source code in https://github.com/Krasjet-Yu/YOLO-FaceV2
COVID-MTL: Multitask Learning with Shift3D and Random-weighted Loss for Automated Diagnosis and Severity Assessment of COVID-19
Dec 31, 2020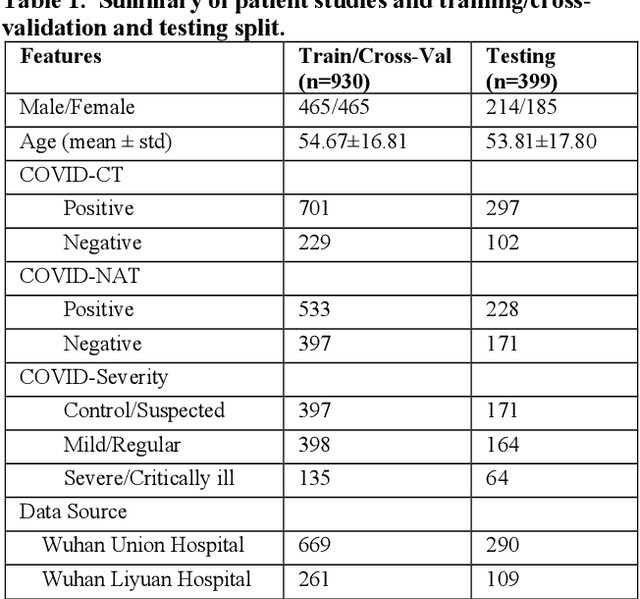
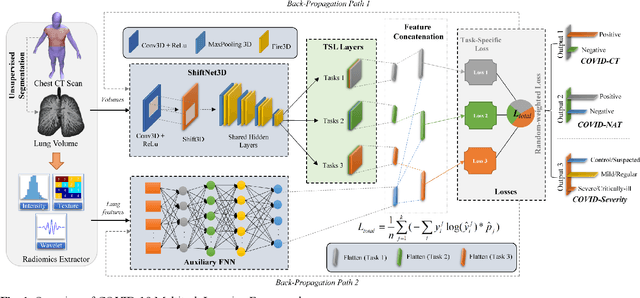
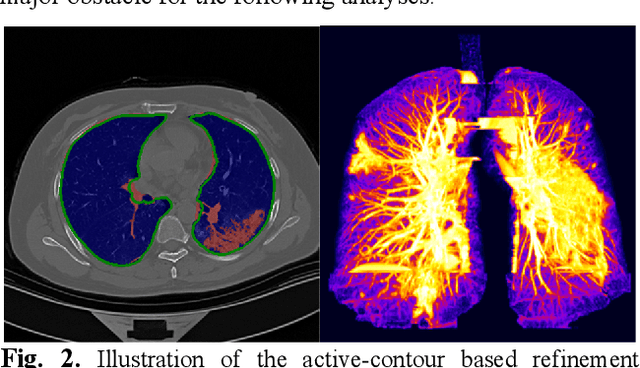
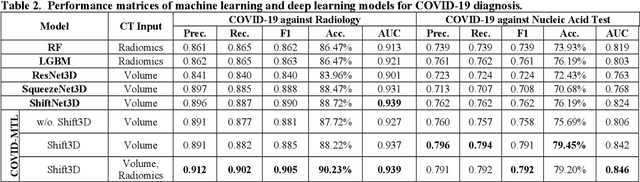
There is an urgent need for automated methods to assist accurate and effective assessment of COVID-19. Radiology and nucleic acid test (NAT) are complementary COVID-19 diagnosis methods. In this paper, we present an end-to-end multitask learning (MTL) framework (COVID-MTL) that is capable of automated and simultaneous detection (against both radiology and NAT) and severity assessment of COVID-19. COVID-MTL learns different COVID-19 tasks in parallel through our novel random-weighted loss function, which assigns learning weights under Dirichlet distribution to prevent task dominance; our new 3D real-time augmentation algorithm (Shift3D) introduces space variances for 3D CNN components by shifting low-level feature representations of volumetric inputs in three dimensions; thereby, the MTL framework is able to accelerate convergence and improve joint learning performance compared to single-task models. By only using chest CT scans, COVID-MTL was trained on 930 CT scans and tested on separate 399 cases. COVID-MTL achieved AUCs of 0.939 and 0.846, and accuracies of 90.23% and 79.20% for detection of COVID-19 against radiology and NAT, respectively, which outperformed the state-of-the-art models. Meanwhile, COVID-MTL yielded AUC of 0.800 $\pm$ 0.020 and 0.813 $\pm$ 0.021 (with transfer learning) for classifying control/suspected, mild/regular, and severe/critically-ill cases. To decipher the recognition mechanism, we also identified high-throughput lung features that were significantly related (P < 0.001) to the positivity and severity of COVID-19.
Depthwise Multiception Convolution for Reducing Network Parameters without Sacrificing Accuracy
Nov 07, 2020



Deep convolutional neural networks have been proven successful in multiple benchmark challenges in recent years. However, the performance improvements are heavily reliant on increasingly complex network architecture and a high number of parameters, which require ever increasing amounts of storage and memory capacity. Depthwise separable convolution (DSConv) can effectively reduce the number of required parameters through decoupling standard convolution into spatial and cross-channel convolution steps. However, the method causes a degradation of accuracy. To address this problem, we present depthwise multiception convolution, termed Multiception, which introduces layer-wise multiscale kernels to learn multiscale representations of all individual input channels simultaneously. We have carried out the experiment on four benchmark datasets, i.e. Cifar-10, Cifar-100, STL-10 and ImageNet32x32, using five popular CNN models, Multiception achieved accuracy promotion in all models and demonstrated higher accuracy performance compared to related works. Meanwhile, Multiception significantly reduces the number of parameters of standard convolution-based models by 32.48% on average while still preserving accuracy.
Visual Analytics of Movement Pattern Based on Time-Spatial Data: A Neural Net Approach
Jul 09, 2017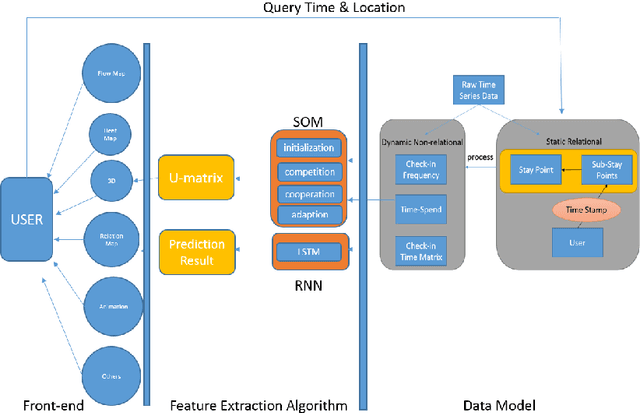

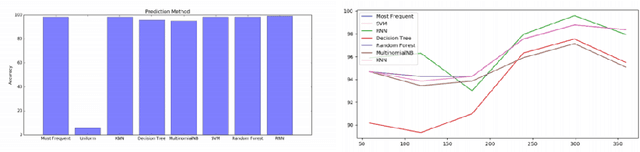
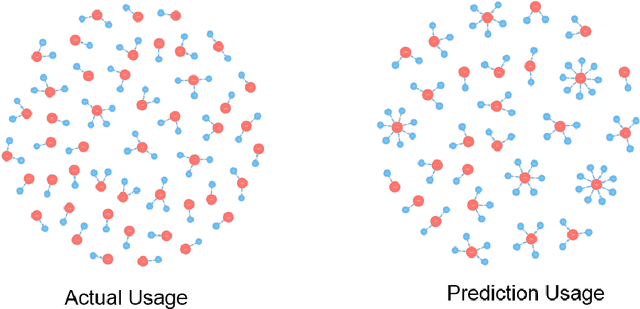
Time-Spatial data plays a crucial role for different fields such as traffic management. These data can be collected via devices such as surveillance sensors or tracking systems. However, how to efficiently an- alyze and visualize these data to capture essential embedded pattern information is becoming a big challenge today. Classic visualization ap- proaches focus on revealing 2D and 3D spatial information and modeling statistical test. Those methods would easily fail when data become mas- sive. Recent attempts concern on how to simply cluster data and perform prediction with time-oriented information. However, those approaches could still be further enhanced as they also have limitations for han- dling massive clusters and labels. In this paper, we propose a visualiza- tion methodology for mobility data using artificial neural net techniques. This method aggregates three main parts that are Back-end Data Model, Neural Net Algorithm including clustering method Self-Organizing Map (SOM) and prediction approach Recurrent Neural Net (RNN) for ex- tracting the features and lastly a solid front-end that displays the results to users with an interactive system. SOM is able to cluster the visiting patterns and detect the abnormal pattern. RNN can perform the predic- tion for time series analysis using its dynamic architecture. Furthermore, an interactive system will enable user to interpret the result with graph- ics, animation and 3D model for a close-loop feedback. This method can be particularly applied in two tasks that Commercial-based Promotion and abnormal traffic patterns detection.