 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback Reciprocal Graph Collaborative Filtering
Aug 05, 2024Collaborative filtering on user-item interaction graphs has achieved success in the industrial recommendation. However, recommending users' truly fascinated items poses a seesaw dilemma for collaborative filtering models learned from the interaction graph. On the one hand, not all items that users interact with are equally appealing. Some items are genuinely fascinating to users, while others are unfascinated. Training graph collaborative filtering models in the absence of distinction between them can lead to the recommendation of unfascinating items to users. On the other hand, disregarding the interacted but unfascinating items during graph collaborative filtering will result in an incomplete representation of users' interaction intent, leading to a decline in the model's recommendation capabilities. To address this seesaw problem, we propose Feedback Reciprocal Graph Collaborative Filtering (FRGCF), which emphasizes the recommendation of fascinating items while attenuating the recommendation of unfascinating items. Specifically, FRGCF first partitions the entire interaction graph into the Interacted & Fascinated (I&F) graph and the Interacted & Unfascinated (I&U) graph based on the user feedback. Then, FRGCF introduces separate collaborative filtering on the I&F graph and the I&U graph with feedback-reciprocal contrastive learning and macro-level feedback modeling. This enables the I&F graph recommender to learn multi-grained interaction characteristics from the I&U graph without being misdirected by it. Extensive experiments on four benchmark datasets and a billion-scale industrial dataset demonstrate that FRGCF improves the performance by recommending more fascinating items and fewer unfascinating items. Besides, online A/B tests on Taobao's recommender system verify the superiority of FRGCF.
FCDNet: Frequency-Guided Complementary Dependency Modeling for Multivariate Time-Series Forecasting
Dec 27, 2023



Multivariate time-series (MTS) forecasting is a challenging task in many real-world non-stationary dynamic scenarios. In addition to intra-series temporal signals, the inter-series dependency also plays a crucial role in shaping future trends. How to enable the model's awareness of dependency information has raised substantial research attention. Previous approaches have either presupposed dependency constraints based on domain knowledge or imposed them using real-time feature similarity. However, MTS data often exhibit both enduring long-term static relationships and transient short-term interactions, which mutually influence their evolving states. It is necessary to recognize and incorporate the complementary dependencies for more accurate MTS prediction. The frequency information in time series reflects the evolutionary rules behind complex temporal dynamics, and different frequency components can be used to well construct long-term and short-term interactive dependency structures between variables. To this end, we propose FCDNet, a concise yet effective framework for multivariate time-series forecasting. Specifically, FCDNet overcomes the above limitations by applying two light-weight dependency constructors to help extract long- and short-term dependency information adaptively from multi-level frequency patterns. With the growth of input variables, the number of trainable parameters in FCDNet only increases linearly, which is conducive to the model's scalability and avoids over-fitting. Additionally, adopting a frequency-based perspective can effectively mitigate the influence of noise within MTS data, which helps capture more genuine dependencies. The experimental results on six real-world datasets from multiple fields show that FCDNet significantly exceeds strong baselines, with an average improvement of 6.82% on MAE, 4.98% on RMSE, and 4.91% on MAPE.
YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
Aug 04, 2022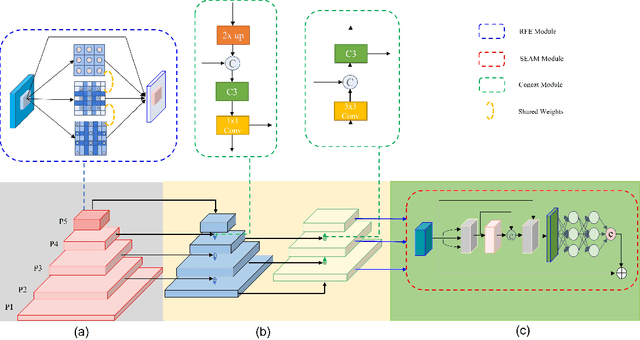
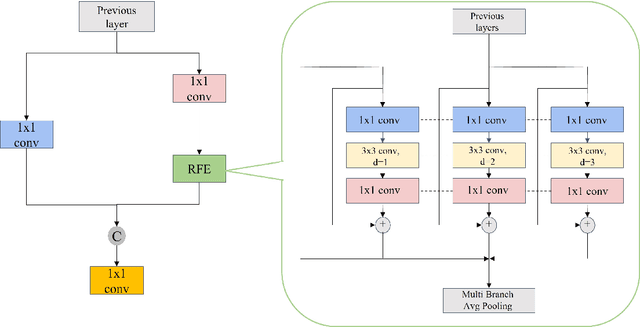
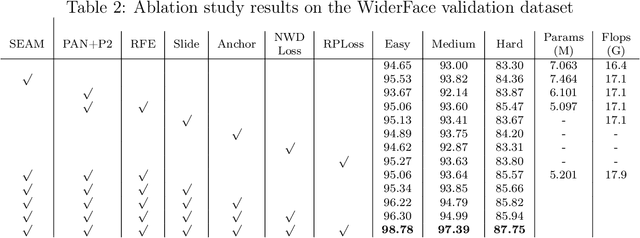
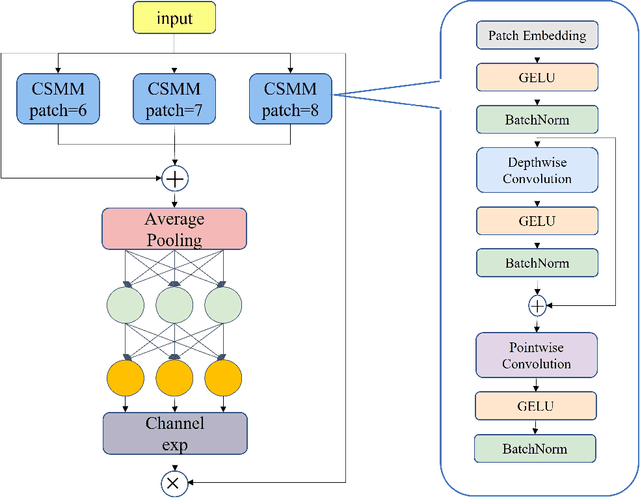
In recent years, face detection algorithms based on deep learning have made great progress. These algorithms can be generally divided into two categories, i.e. two-stage detector like Faster R-CNN and one-stage detector like YOLO. Because of the better balance between accuracy and speed, one-stage detectors have been widely used in many applications. In this paper, we propose a real-time face detector based on the one-stage detector YOLOv5, named YOLO-FaceV2. We design a Receptive Field Enhancement module called RFE to enhance receptive field of small face, and use NWD Loss to make up for the sensitivity of IoU to the location deviation of tiny objects. For face occlusion, we present an attention module named SEAM and introduce Repulsion Loss to solve it. Moreover, we use a weight function Slide to solve the imbalance between easy and hard samples and use the information of the effective receptive field to design the anchor. The experimental results on WiderFace dataset show that our face detector outperforms YOLO and its variants can be find in all easy, medium and hard subsets. Source code in https://github.com/Krasjet-Yu/YOLO-FaceV2
Learning Sparse and Continuous Graph Structures for Multivariate Time Series Forecasting
Jan 24, 2022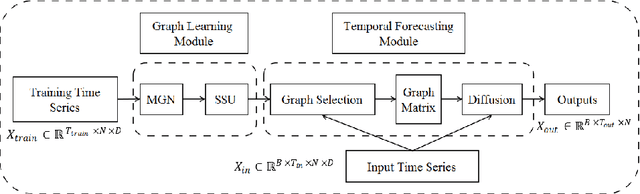

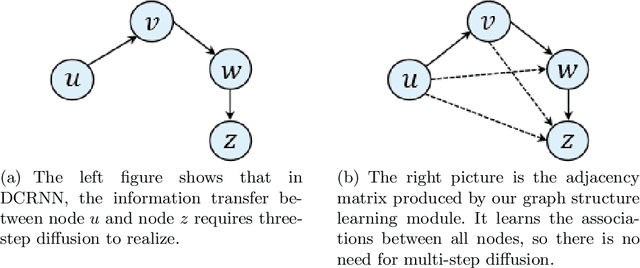
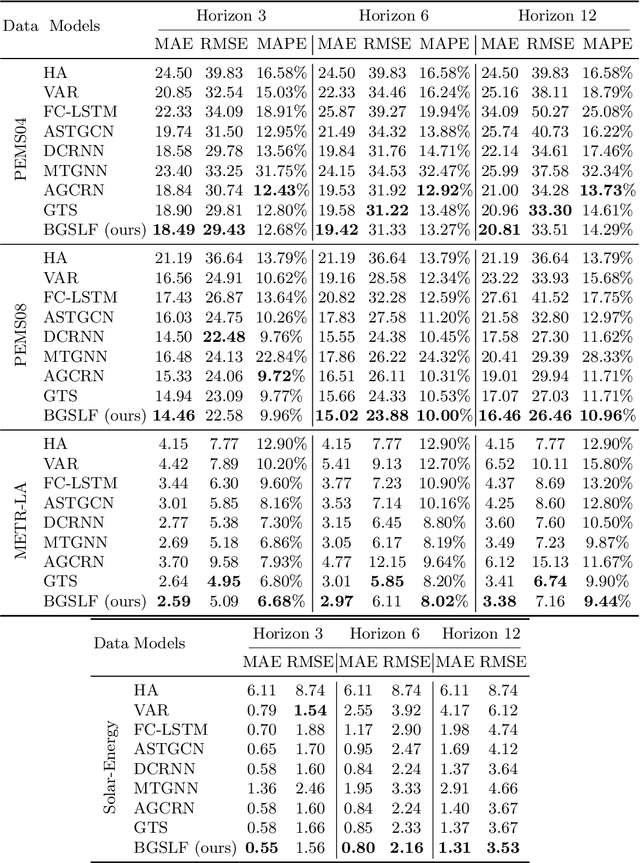
Accurate forecasting of multivariate time series is an extensively studied subject in finance, transportation, and computer science. Fully mining the correlation and causation between the variables in a multivariate time series exhibits noticeable results in improving the performance of a time series model. Recently, some models have explored the dependencies between variables through end-to-end graph structure learning without the need for pre-defined graphs. However, most current models do not incorporate the trade-off between effectiveness and flexibility and lack the guidance of domain knowledge in the design of graph learning algorithms. Besides, they have issues generating sparse graph structures, which pose challenges to end-to-end learning. In this paper, we propose Learning Sparse and Continuous Graphs for Forecasting (LSCGF), a novel deep learning model that joins graph learning and forecasting. Technically, LSCGF leverages the spatial information into convolutional operation and extracts temporal dynamics using the diffusion convolution recurrent network. At the same time, we propose a brand new method named Smooth Sparse Unit (SSU) to learn sparse and continuous graph adjacency matrix. Extensive experiments on three real-world datasets demonstrate that our model achieves state-of-the-art performances with minor trainable parameters.