 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Generalist Agents for Contextualized Time Series
Jun 03, 2026Time series are often embedded in rich contexts that are essential for holistic modeling. Moreover, real-world practitioners often require end-to-end workflows for analyzing temporal dynamics, where widely studied tasks such as forecasting are only one step in a broader solution loop. While generalist AI agents offer a promising interface for such workflows under complex contexts, they still operate primarily in textual spaces that are not fully aligned with structured temporal signals. In this work, we introduce TimeClaw, an agentic harness framework for time series that equips generalist LLM agents with the time series-native runtime support needed for contextualized temporal reasoning. TimeClaw integrates executable temporal tools for grounded and auditable analysis, experience-driven capability evolution for creating reusable analytical routines, and episodic multimodal memory for retrieving relevant reasoning traces. Together, these components unlock harnessed open-ended temporal reasoning with contextual information. Extensive evaluation on multiple benchmarks covering diverse tasks across energy, finance, weather, traffic, and other real-world domains demonstrates improved performance of TimeClaw. Code is available at https://github.com/iDEA-iSAIL-Lab-UIUC/TimeClaw.
Code as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
PAPERMIND: Benchmarking Agentic Reasoning and Critique over Scientific Papers in Multimodal LLMs
Apr 23, 2026Understanding scientific papers requires more than answering isolated questions or summarizing content. It involves an integrated reasoning process that grounds textual and visual information, interprets experimental evidence, synthesizes information across sources, and critically evaluates scientific claims. However, existing benchmarks typically assess these abilities in isolation, making it difficult to evaluate scientific paper understanding as a unified set of interacting cognitive abilities. In this work, we introduce PAPERMIND, a benchmark designed to evaluate integrated and agent-oriented scientific reasoning over research papers. PAPERMIND is constructed from real scientific papers across seven domains, including agriculture, biology, chemistry, computer science, medicine, physics, and economics. It comprises four complementary task families that collectively operationalize distinct cognitive facets of scientific paper reasoning, including multimodal grounding, experimental interpretation, cross-source evidence reasoning, and critical assessment. By analyzing model behavior across multiple tasks, PAPERMIND enables a diagnostic evaluation of integrated scientific reasoning behaviors that are difficult to assess through isolated task evaluations. Extensive experiments on both opensource and closed-source multimodal LLMs reveal consistent performance gaps across tasks, highlighting persistent challenges in integrated scientific reasoning and critique. Our benchmark and dataset are available at https:// github.com/Yanjun-Zhao/PaperMind.
Generalizable Self-Evolving Memory for Automatic Prompt Optimization
Mar 23, 2026Automatic prompt optimization is a promising approach for adapting large language models (LLMs) to downstream tasks, yet existing methods typically search for a specific prompt specialized to a fixed task. This paradigm limits generalization across heterogeneous queries and prevents models from accumulating reusable prompting knowledge over time. In this paper, we propose MemAPO, a memory-driven framework that reconceptualizes prompt optimization as generalizable and self-evolving experience accumulation. MemAPO maintains a dual-memory mechanism that distills successful reasoning trajectories into reusable strategy templates while organizing incorrect generations into structured error patterns that capture recurrent failure modes. Given a new prompt, the framework retrieves both relevant strategies and failure patterns to compose prompts that promote effective reasoning while discouraging known mistakes. Through iterative self-reflection and memory editing, MemAPO continuously updates its memory, enabling prompt optimization to improve over time rather than restarting from scratch for each task. Experiments on diverse benchmarks show that MemAPO consistently outperforms representative prompt optimization baselines while substantially reducing optimization cost.
The Semantic Lifecycle in Embodied AI: Acquisition, Representation and Storage via Foundation Models
Jan 12, 2026Semantic information in embodied AI is inherently multi-source and multi-stage, making it challenging to fully leverage for achieving stable perception-to-action loops in real-world environments. Early studies have combined manual engineering with deep neural networks, achieving notable progress in specific semantic-related embodied tasks. However, as embodied agents encounter increasingly complex environments and open-ended tasks, the demand for more generalizable and robust semantic processing capabilities has become imperative. Recent advances in foundation models (FMs) address this challenge through their cross-domain generalization abilities and rich semantic priors, reshaping the landscape of embodied AI research. In this survey, we propose the Semantic Lifecycle as a unified framework to characterize the evolution of semantic knowledge within embodied AI driven by foundation models. Departing from traditional paradigms that treat semantic processing as isolated modules or disjoint tasks, our framework offers a holistic perspective that captures the continuous flow and maintenance of semantic knowledge. Guided by this embodied semantic lifecycle, we further analyze and compare recent advances across three key stages: acquisition, representation, and storage. Finally, we summarize existing challenges and outline promising directions for future research.
Mem-Gallery: Benchmarking Multimodal Long-Term Conversational Memory for MLLM Agents
Jan 07, 2026Long-term memory is a critical capability for multimodal large language model (MLLM) agents, particularly in conversational settings where information accumulates and evolves over time. However, existing benchmarks either evaluate multi-session memory in text-only conversations or assess multimodal understanding within localized contexts, failing to evaluate how multimodal memory is preserved, organized, and evolved across long-term conversational trajectories. Thus, we introduce Mem-Gallery, a new benchmark for evaluating multimodal long-term conversational memory in MLLM agents. Mem-Gallery features high-quality multi-session conversations grounded in both visual and textual information, with long interaction horizons and rich multimodal dependencies. Building on this dataset, we propose a systematic evaluation framework that assesses key memory capabilities along three functional dimensions: memory extraction and test-time adaptation, memory reasoning, and memory knowledge management. Extensive benchmarking across thirteen memory systems reveals several key findings, highlighting the necessity of explicit multimodal information retention and memory organization, the persistent limitations in memory reasoning and knowledge management, as well as the efficiency bottleneck of current models.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
Macro Graph of Experts for Billion-Scale Multi-Task Recommendation
Jun 12, 2025Graph-based multi-task learning at billion-scale presents a significant challenge, as different tasks correspond to distinct billion-scale graphs. Traditional multi-task learning methods often neglect these graph structures, relying solely on individual user and item embeddings. However, disregarding graph structures overlooks substantial potential for improving performance. In this paper, we introduce the Macro Graph of Expert (MGOE) framework, the first approach capable of leveraging macro graph embeddings to capture task-specific macro features while modeling the correlations between task-specific experts. Specifically, we propose the concept of a Macro Graph Bottom, which, for the first time, enables multi-task learning models to incorporate graph information effectively. We design the Macro Prediction Tower to dynamically integrate macro knowledge across tasks. MGOE has been deployed at scale, powering multi-task learning for the homepage of a leading billion-scale recommender system. Extensive offline experiments conducted on three public benchmark datasets demonstrate its superiority over state-of-the-art multi-task learning methods, establishing MGOE as a breakthrough in multi-task graph-based recommendation. Furthermore, online A/B tests confirm the superiority of MGOE in billion-scale recommender systems.
FilterLLM: Text-To-Distribution LLM for Billion-Scale Cold-Start Recommendation
Feb 24, 2025Large Language Model (LLM)-based cold-start recommendation systems continue to face significant computational challenges in billion-scale scenarios, as they follow a "Text-to-Judgment" paradigm. This approach processes user-item content pairs as input and evaluates each pair iteratively. To maintain efficiency, existing methods rely on pre-filtering a small candidate pool of user-item pairs. However, this severely limits the inferential capabilities of LLMs by reducing their scope to only a few hundred pre-filtered candidates. To overcome this limitation, we propose a novel "Text-to-Distribution" paradigm, which predicts an item's interaction probability distribution for the entire user set in a single inference. Specifically, we present FilterLLM, a framework that extends the next-word prediction capabilities of LLMs to billion-scale filtering tasks. FilterLLM first introduces a tailored distribution prediction and cold-start framework. Next, FilterLLM incorporates an efficient user-vocabulary structure to train and store the embeddings of billion-scale users. Finally, we detail the training objectives for both distribution prediction and user-vocabulary construction. The proposed framework has been deployed on the Alibaba platform, where it has been serving cold-start recommendations for two months, processing over one billion cold items. Extensive experiments demonstrate that FilterLLM significantly outperforms state-of-the-art methods in cold-start recommendation tasks, achieving over 30 times higher efficiency. Furthermore, an online A/B test validates its effectiveness in billion-scale recommendation systems.
Cold-Start Recommendation towards the Era of Large Language Models (LLMs): A Comprehensive Survey and Roadmap
Jan 03, 2025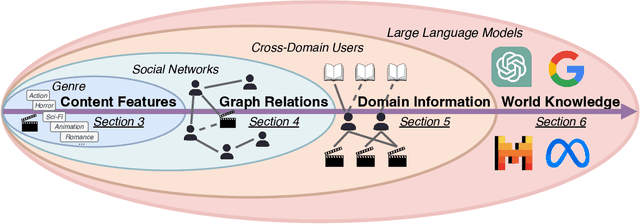
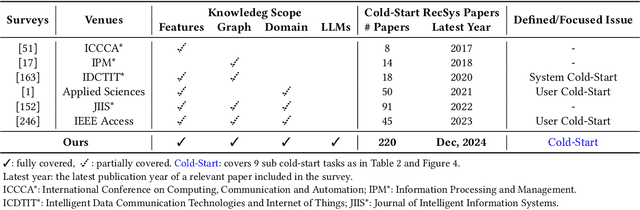
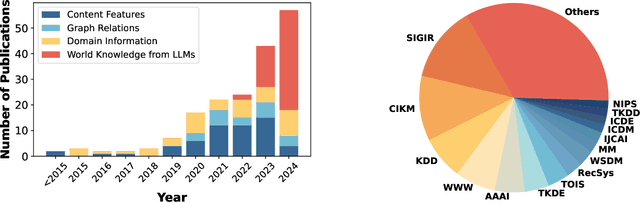
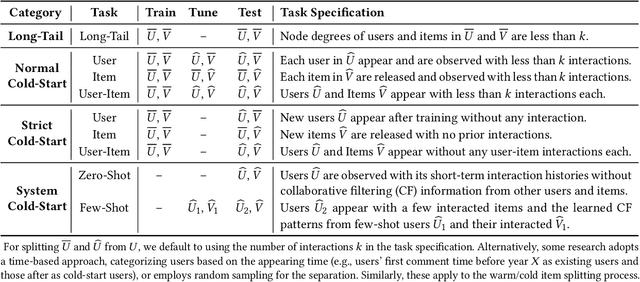
Cold-start problem is one of the long-standing challenges in recommender systems, focusing on accurately modeling new or interaction-limited users or items to provide better recommendations. Due to the diversification of internet platforms and the exponential growth of users and items, the importance of cold-start recommendation (CSR) is becoming increasingly evident. At the same time, large language models (LLMs) have achieved tremendous success and possess strong capabilities in modeling user and item information, providing new potential for cold-start recommendations. However, the research community on CSR still lacks a comprehensive review and reflection in this field. Based on this, in this paper, we stand in the context of the era of large language models and provide a comprehensive review and discussion on the roadmap, related literature, and future directions of CSR. Specifically, we have conducted an exploration of the development path of how existing CSR utilizes information, from content features, graph relations, and domain information, to the world knowledge possessed by large language models, aiming to provide new insights for both the research and industrial communities on CSR. Related resources of cold-start recommendations are collected and continuously updated for the community in https://github.com/YuanchenBei/Awesome-Cold-Start-Recommendation.