 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciCustom: A Framework for Custom Evaluation of Scientific Capabilities in Large Language Models
May 19, 2026Large language models (LLMs) are increasingly applied to scientific research, yet existing evaluations often fail to reflect the fine-grained capabilities required in practice. Most benchmarks are manually curated or domain-generic, limiting scalability and alignment with real scientific use cases. In this paper, we propose a new framework named SciCustom to address the problem. It enables the custom construction of benchmarks from large-scale scientific data to evaluate application-specific scientific capabilities in LLMs. SciCustom first organizes scientific knowledge into ontology-grounded knowledge units with controlled granularity and trains a tagger to map large-scale data instances into this knowledge space. Given a custom requirement, relevant knowledge units are identified via voting-based multi-model consensus. These units enable relevance-aware benchmark retrieval via binary search, followed by proxy subset selection and data-grounded benchmark generation for efficient evaluation. Experiments in chemistry and healthcare demonstrate that SciCustom reveals fine-grained differences in LLM scientific capabilities that standard benchmarks overlook, while requiring neither expert annotation nor synthetic question generation. This work provides a scalable and application-aware foundation for benchmarking scientific capabilities in LLMs. The source code is available at https://github.com/yjwtheonly/SciCustom.
MEME: Modeling the Evolutionary Modes of Financial Markets
Feb 12, 2026LLMs have demonstrated significant potential in quantitative finance by processing vast unstructured data to emulate human-like analytical workflows. However, current LLM-based methods primarily follow either an Asset-Centric paradigm focused on individual stock prediction or a Market-Centric approach for portfolio allocation, often remaining agnostic to the underlying reasoning that drives market movements. In this paper, we propose a Logic-Oriented perspective, modeling the financial market as a dynamic, evolutionary ecosystem of competing investment narratives, termed Modes of Thought. To operationalize this view, we introduce MEME (Modeling the Evolutionary Modes of Financial Markets), designed to reconstruct market dynamics through the lens of evolving logics. MEME employs a multi-agent extraction module to transform noisy data into high-fidelity Investment Arguments and utilizes Gaussian Mixture Modeling to uncover latent consensus within a semantic space. To model semantic drift among different market conditions, we also implement a temporal evaluation and alignment mechanism to track the lifecycle and historical profitability of these modes. By prioritizing enduring market wisdom over transient anomalies, MEME ensures that portfolio construction is guided by robust reasoning. Extensive experiments on three heterogeneous Chinese stock pools from 2023 to 2025 demonstrate that MEME consistently outperforms seven SOTA baselines. Further ablation studies, sensitivity analysis, lifecycle case study and cost analysis validate MEME's capacity to identify and adapt to the evolving consensus of financial markets. Our implementation can be found at https://github.com/gta0804/MEME.
AlphaPROBE: Alpha Mining via Principled Retrieval and On-graph biased evolution
Feb 12, 2026Extracting signals through alpha factor mining is a fundamental challenge in quantitative finance. Existing automated methods primarily follow two paradigms: Decoupled Factor Generation, which treats factor discovery as isolated events, and Iterative Factor Evolution, which focuses on local parent-child refinements. However, both paradigms lack a global structural view, often treating factor pools as unstructured collections or fragmented chains, which leads to redundant search and limited diversity. To address these limitations, we introduce AlphaPROBE (Alpha Mining via Principled Retrieval and On-graph Biased Evolution), a framework that reframes alpha mining as the strategic navigation of a Directed Acyclic Graph (DAG). By modeling factors as nodes and evolutionary links as edges, AlphaPROBE treats the factor pool as a dynamic, interconnected ecosystem. The framework consists of two core components: a Bayesian Factor Retriever that identifies high-potential seeds by balancing exploitation and exploration through a posterior probability model, and a DAG-aware Factor Generator that leverages the full ancestral trace of factors to produce context-aware, nonredundant optimizations. Extensive experiments on three major Chinese stock market datasets against 8 competitive baselines demonstrate that AlphaPROBE significantly gains enhanced performance in predictive accuracy, return stability and training efficiency. Our results confirm that leveraging global evolutionary topology is essential for efficient and robust automated alpha discovery. We have open-sourced our implementation at https://github.com/gta0804/AlphaPROBE.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Delay-Oriented Distributed Scheduling with TransGNN
Dec 09, 2025Minimizing transmission delay in wireless multi-hop networks is a fundamental yet challenging task due to the complex coupling among interference, queue dynamics, and distributed control. Traditional scheduling algorithms, such as max-weight or queue-length-based policies, primarily aim to optimize throughput but often suffer from high latency, especially in heterogeneous or dynamically changing topologies. Recent learning-based approaches, particularly those employing Graph Neural Networks (GNNs), have shown promise in capturing spatial interference structures. However, conventional Graph Convolutional Networks (GCNs) remain limited by their local aggregation mechanism and their inability to model long-range dependencies within the conflict graph. To address these challenges, this paper proposes a delay-oriented distributed scheduling framework based on Transformer GNN. The proposed model employs an attention-based graph encoder to generate adaptive per-link utility scores that reflect both queue backlog and interference intensity. A Local Greedy Solver (LGS) then utilizes these utilities to construct a feasible independent set of links for transmission, ensuring distributed and conflict-free scheduling.
A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
Oct 29, 2025Post-training of Large Language Models (LLMs) is crucial for unlocking their task generalization potential and domain-specific capabilities. However, the current LLM post-training paradigm faces significant data challenges, including the high costs of manual annotation and diminishing marginal returns on data scales. Therefore, achieving data-efficient post-training has become a key research question. In this paper, we present the first systematic survey of data-efficient LLM post-training from a data-centric perspective. We propose a taxonomy of data-efficient LLM post-training methods, covering data selection, data quality enhancement, synthetic data generation, data distillation and compression, and self-evolving data ecosystems. We summarize representative approaches in each category and outline future research directions. By examining the challenges in data-efficient LLM post-training, we highlight open problems and propose potential research avenues. We hope our work inspires further exploration into maximizing the potential of data utilization in large-scale model training. Paper List: https://github.com/luo-junyu/Awesome-Data-Efficient-LLM
Sparse Causal Discovery with Generative Intervention for Unsupervised Graph Domain Adaptation
Jul 10, 2025Unsupervised Graph Domain Adaptation (UGDA) leverages labeled source domain graphs to achieve effective performance in unlabeled target domains despite distribution shifts. However, existing methods often yield suboptimal results due to the entanglement of causal-spurious features and the failure of global alignment strategies. We propose SLOGAN (Sparse Causal Discovery with Generative Intervention), a novel approach that achieves stable graph representation transfer through sparse causal modeling and dynamic intervention mechanisms. Specifically, SLOGAN first constructs a sparse causal graph structure, leveraging mutual information bottleneck constraints to disentangle sparse, stable causal features while compressing domain-dependent spurious correlations through variational inference. To address residual spurious correlations, we innovatively design a generative intervention mechanism that breaks local spurious couplings through cross-domain feature recombination while maintaining causal feature semantic consistency via covariance constraints. Furthermore, to mitigate error accumulation in target domain pseudo-labels, we introduce a category-adaptive dynamic calibration strategy, ensuring stable discriminative learning. Extensive experiments on multiple real-world datasets demonstrate that SLOGAN significantly outperforms existing baselines.
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Jun 23, 2025Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
A Survey of Automatic Evaluation Methods on Text, Visual and Speech Generations
Jun 06, 2025Recent advances in deep learning have significantly enhanced generative AI capabilities across text, images, and audio. However, automatically evaluating the quality of these generated outputs presents ongoing challenges. Although numerous automatic evaluation methods exist, current research lacks a systematic framework that comprehensively organizes these methods across text, visual, and audio modalities. To address this issue, we present a comprehensive review and a unified taxonomy of automatic evaluation methods for generated content across all three modalities; We identify five fundamental paradigms that characterize existing evaluation approaches across these domains. Our analysis begins by examining evaluation methods for text generation, where techniques are most mature. We then extend this framework to image and audio generation, demonstrating its broad applicability. Finally, we discuss promising directions for future research in cross-modal evaluation methodologies.
FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025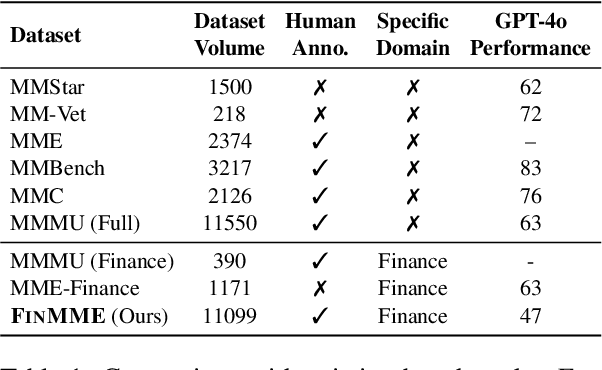
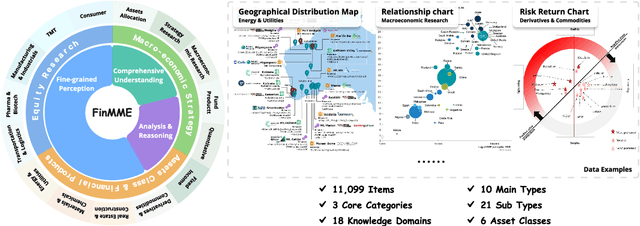
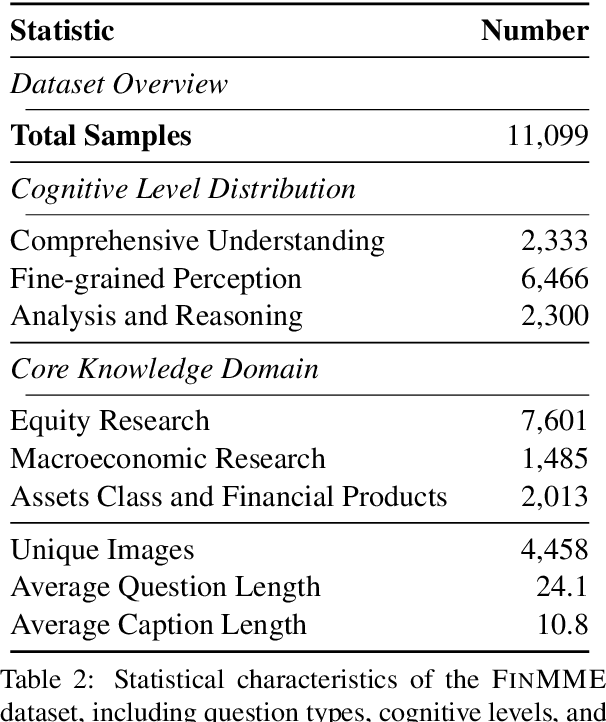
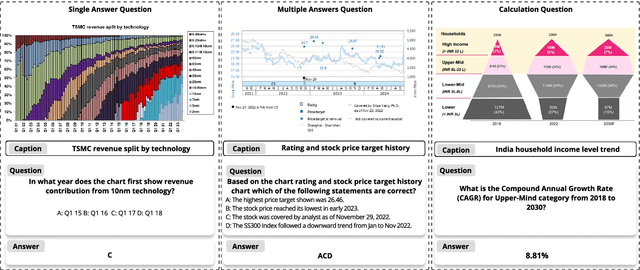
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.