 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025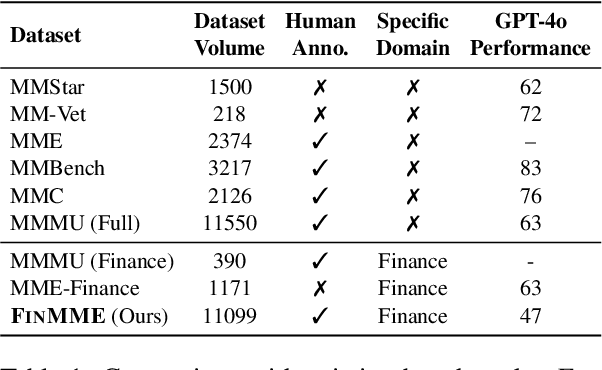
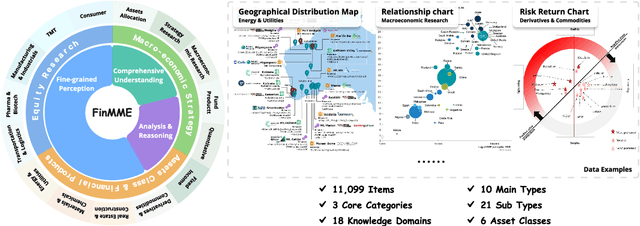
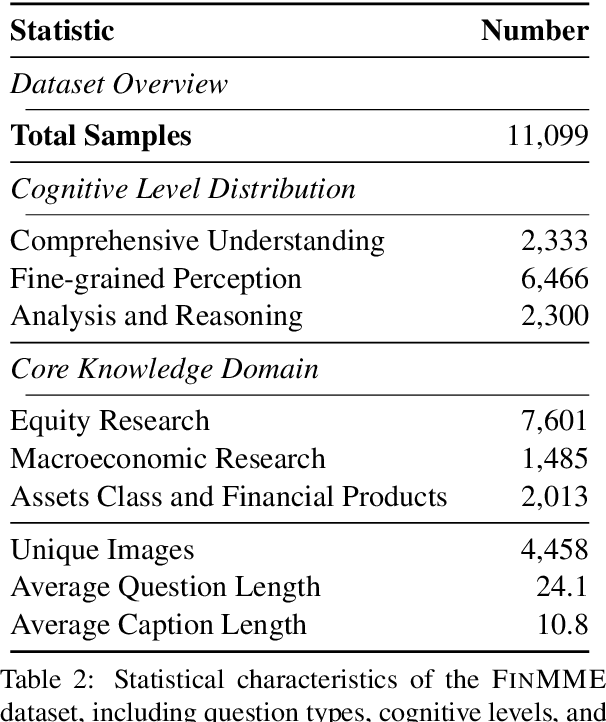
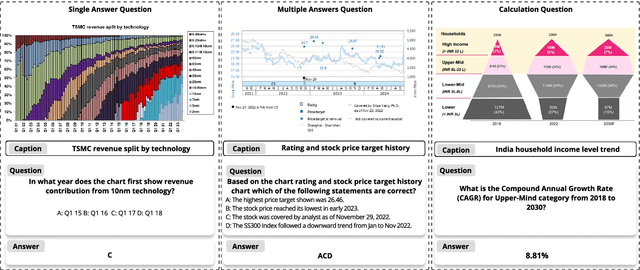
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
Learned Data Compression: Challenges and Opportunities for the Future
Dec 14, 2024



Compressing integer keys is a fundamental operation among multiple communities, such as database management (DB), information retrieval (IR), and high-performance computing (HPC). Recent advances in \emph{learned indexes} have inspired the development of \emph{learned compressors}, which leverage simple yet compact machine learning (ML) models to compress large-scale sorted keys. The core idea behind learned compressors is to \emph{losslessly} encode sorted keys by approximating them with \emph{error-bounded} ML models (e.g., piecewise linear functions) and using a \emph{residual array} to guarantee accurate key reconstruction. While the concept of learned compressors remains in its early stages of exploration, our benchmark results demonstrate that an SIMD-optimized learned compressor can significantly outperform state-of-the-art CPU-based compressors. Drawing on our preliminary experiments, this vision paper explores the potential of learned data compression to enhance critical areas in DBMS and related domains. Furthermore, we outline the key technical challenges that existing systems must address when integrating this emerging methodology.
Automate Strategy Finding with LLM in Quant investment
Sep 10, 2024



Despite significant progress in deep learning for financial trading, existing models often face instability and high uncertainty, hindering their practical application. Leveraging advancements in Large Language Models (LLMs) and multi-agent architectures, we propose a novel framework for quantitative stock investment in portfolio management and alpha mining. Our framework addresses these issues by integrating LLMs to generate diversified alphas and employing a multi-agent approach to dynamically evaluate market conditions. This paper proposes a framework where large language models (LLMs) mine alpha factors from multimodal financial data, ensuring a comprehensive understanding of market dynamics. The first module extracts predictive signals by integrating numerical data, research papers, and visual charts. The second module uses ensemble learning to construct a diverse pool of trading agents with varying risk preferences, enhancing strategy performance through a broader market analysis. In the third module, a dynamic weight-gating mechanism selects and assigns weights to the most relevant agents based on real-time market conditions, enabling the creation of an adaptive and context-aware composite alpha formula. Extensive experiments on the Chinese stock markets demonstrate that this framework significantly outperforms state-of-the-art baselines across multiple financial metrics. The results underscore the efficacy of combining LLM-generated alphas with a multi-agent architecture to achieve superior trading performance and stability. This work highlights the potential of AI-driven approaches in enhancing quantitative investment strategies and sets a new benchmark for integrating advanced machine learning techniques in financial trading can also be applied on diverse markets.
UniCL: A Universal Contrastive Learning Framework for Large Time Series Models
May 17, 2024



Time-series analysis plays a pivotal role across a range of critical applications, from finance to healthcare, which involves various tasks, such as forecasting and classification. To handle the inherent complexities of time-series data, such as high dimensionality and noise, traditional supervised learning methods first annotate extensive labels for time-series data in each task, which is very costly and impractical in real-world applications. In contrast, pre-trained foundation models offer a promising alternative by leveraging unlabeled data to capture general time series patterns, which can then be fine-tuned for specific tasks. However, existing approaches to pre-training such models typically suffer from high-bias and low-generality issues due to the use of predefined and rigid augmentation operations and domain-specific data training. To overcome these limitations, this paper introduces UniCL, a universal and scalable contrastive learning framework designed for pretraining time-series foundation models across cross-domain datasets. Specifically, we propose a unified and trainable time-series augmentation operation to generate pattern-preserved, diverse, and low-bias time-series data by leveraging spectral information. Besides, we introduce a scalable augmentation algorithm capable of handling datasets with varying lengths, facilitating cross-domain pretraining. Extensive experiments on two benchmark datasets across eleven domains validate the effectiveness of UniCL, demonstrating its high generalization on time-series analysis across various fields.