 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Correcting Label Noise for Robust GNNs via Influence Contradiction
Jan 24, 2026Graph Neural Networks (GNNs) have shown remarkable capabilities in learning from graph-structured data with various applications such as social analysis and bioinformatics. However, the presence of label noise in real scenarios poses a significant challenge in learning robust GNNs, and their effectiveness can be severely impacted when dealing with noisy labels on graphs, often stemming from annotation errors or inconsistencies. To address this, in this paper we propose a novel approach called ICGNN that harnesses the structure information of the graph to effectively alleviate the challenges posed by noisy labels. Specifically, we first design a novel noise indicator that measures the influence contradiction score (ICS) based on the graph diffusion matrix to quantify the credibility of nodes with clean labels, such that nodes with higher ICS values are more likely to be detected as having noisy labels. Then we leverage the Gaussian mixture model to precisely detect whether the label of a node is noisy or not. Additionally, we develop a soft strategy to combine the predictions from neighboring nodes on the graph to correct the detected noisy labels. At last, pseudo-labeling for abundant unlabeled nodes is incorporated to provide auxiliary supervision signals and guide the model optimization. Experiments on benchmark datasets show the superiority of our proposed approach.
DREAM: Dual-Standard Semantic Homogeneity with Dynamic Optimization for Graph Learning with Label Noise
Jan 24, 2026Graph neural networks (GNNs) have been widely used in various graph machine learning scenarios. Existing literature primarily assumes well-annotated training graphs, while the reliability of labels is not guaranteed in real-world scenarios. Recently, efforts have been made to address the problem of graph learning with label noise. However, existing methods often (i) struggle to distinguish between reliable and unreliable nodes, and (ii) overlook the relational information embedded in the graph topology. To tackle this problem, this paper proposes a novel method, Dual-Standard Semantic Homogeneity with Dynamic Optimization (DREAM), for reliable, relation-informed optimization on graphs with label noise. Specifically, we design a relation-informed dynamic optimization framework that iteratively reevaluates the reliability of each labeled node in the graph during the optimization process according to the relation of the target node and other nodes. To measure this relation comprehensively, we propose a dual-standard selection strategy that selects a set of anchor nodes based on both node proximity and graph topology. Subsequently, we compute the semantic homogeneity between the target node and the anchor nodes, which serves as guidance for optimization. We also provide a rigorous theoretical analysis to justify the design of DREAM. Extensive experiments are performed on six graph datasets across various domains under three types of graph label noise against competing baselines, and the results demonstrate the effectiveness of the proposed DREAM.
A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
Oct 29, 2025Post-training of Large Language Models (LLMs) is crucial for unlocking their task generalization potential and domain-specific capabilities. However, the current LLM post-training paradigm faces significant data challenges, including the high costs of manual annotation and diminishing marginal returns on data scales. Therefore, achieving data-efficient post-training has become a key research question. In this paper, we present the first systematic survey of data-efficient LLM post-training from a data-centric perspective. We propose a taxonomy of data-efficient LLM post-training methods, covering data selection, data quality enhancement, synthetic data generation, data distillation and compression, and self-evolving data ecosystems. We summarize representative approaches in each category and outline future research directions. By examining the challenges in data-efficient LLM post-training, we highlight open problems and propose potential research avenues. We hope our work inspires further exploration into maximizing the potential of data utilization in large-scale model training. Paper List: https://github.com/luo-junyu/Awesome-Data-Efficient-LLM
Sparse Causal Discovery with Generative Intervention for Unsupervised Graph Domain Adaptation
Jul 10, 2025Unsupervised Graph Domain Adaptation (UGDA) leverages labeled source domain graphs to achieve effective performance in unlabeled target domains despite distribution shifts. However, existing methods often yield suboptimal results due to the entanglement of causal-spurious features and the failure of global alignment strategies. We propose SLOGAN (Sparse Causal Discovery with Generative Intervention), a novel approach that achieves stable graph representation transfer through sparse causal modeling and dynamic intervention mechanisms. Specifically, SLOGAN first constructs a sparse causal graph structure, leveraging mutual information bottleneck constraints to disentangle sparse, stable causal features while compressing domain-dependent spurious correlations through variational inference. To address residual spurious correlations, we innovatively design a generative intervention mechanism that breaks local spurious couplings through cross-domain feature recombination while maintaining causal feature semantic consistency via covariance constraints. Furthermore, to mitigate error accumulation in target domain pseudo-labels, we introduce a category-adaptive dynamic calibration strategy, ensuring stable discriminative learning. Extensive experiments on multiple real-world datasets demonstrate that SLOGAN significantly outperforms existing baselines.
FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025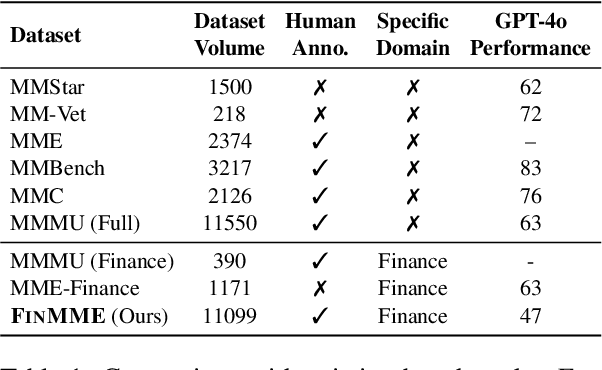
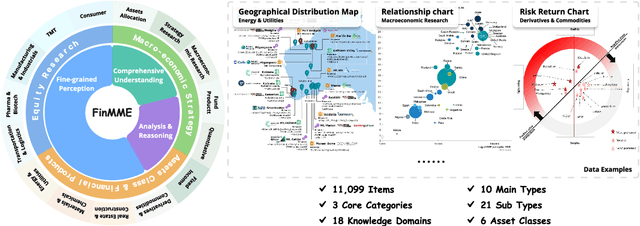
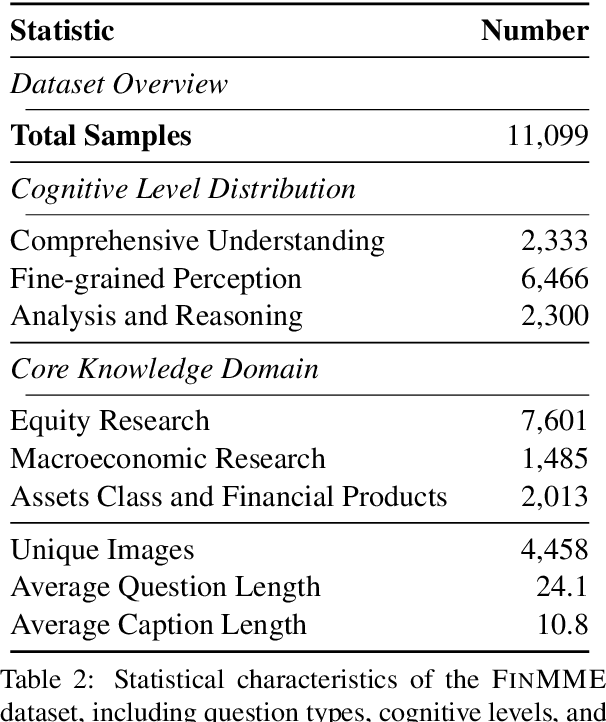
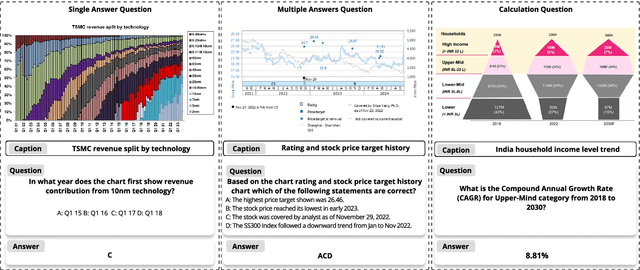
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
Dynamic Text Bundling Supervision for Zero-Shot Inference on Text-Attributed Graphs
May 23, 2025Large language models (LLMs) have been used in many zero-shot learning problems, with their strong generalization ability. Recently, adopting LLMs in text-attributed graphs (TAGs) has drawn increasing attention. However, the adoption of LLMs faces two major challenges: limited information on graph structure and unreliable responses. LLMs struggle with text attributes isolated from the graph topology. Worse still, they yield unreliable predictions due to both information insufficiency and the inherent weakness of LLMs (e.g., hallucination). Towards this end, this paper proposes a novel method named Dynamic Text Bundling Supervision (DENSE) that queries LLMs with bundles of texts to obtain bundle-level labels and uses these labels to supervise graph neural networks. Specifically, we sample a set of bundles, each containing a set of nodes with corresponding texts of close proximity. We then query LLMs with the bundled texts to obtain the label of each bundle. Subsequently, the bundle labels are used to supervise the optimization of graph neural networks, and the bundles are further refined to exclude noisy items. To justify our design, we also provide theoretical analysis of the proposed method. Extensive experiments across ten datasets validate the effectiveness of the proposed method.
MARCO: Meta-Reflection with Cross-Referencing for Code Reasoning
May 23, 2025The ability to reason is one of the most fundamental capabilities of large language models (LLMs), enabling a wide range of downstream tasks through sophisticated problem-solving. A critical aspect of this is code reasoning, which involves logical reasoning with formal languages (i.e., programming code). In this paper, we enhance this capability of LLMs by exploring the following question: how can an LLM agent become progressively smarter in code reasoning with each solution it proposes, thereby achieving substantial cumulative improvement? Most existing research takes a static perspective, focusing on isolated problem-solving using frozen LLMs. In contrast, we adopt a cognitive-evolving perspective and propose a novel framework named Meta-Reflection with Cross-Referencing (MARCO) that enables the LLM to evolve dynamically during inference through self-improvement. From the perspective of human cognitive development, we leverage both knowledge accumulation and lesson sharing. In particular, to accumulate knowledge during problem-solving, we propose meta-reflection that reflects on the reasoning paths of the current problem to obtain knowledge and experience for future consideration. Moreover, to effectively utilize the lessons from other agents, we propose cross-referencing that incorporates the solution and feedback from other agents into the current problem-solving process. We conduct experiments across various datasets in code reasoning, and the results demonstrate the effectiveness of MARCO.
Cross-Domain Diffusion with Progressive Alignment for Efficient Adaptive Retrieval
May 20, 2025Unsupervised efficient domain adaptive retrieval aims to transfer knowledge from a labeled source domain to an unlabeled target domain, while maintaining low storage cost and high retrieval efficiency. However, existing methods typically fail to address potential noise in the target domain, and directly align high-level features across domains, thus resulting in suboptimal retrieval performance. To address these challenges, we propose a novel Cross-Domain Diffusion with Progressive Alignment method (COUPLE). This approach revisits unsupervised efficient domain adaptive retrieval from a graph diffusion perspective, simulating cross-domain adaptation dynamics to achieve a stable target domain adaptation process. First, we construct a cross-domain relationship graph and leverage noise-robust graph flow diffusion to simulate the transfer dynamics from the source domain to the target domain, identifying lower noise clusters. We then leverage the graph diffusion results for discriminative hash code learning, effectively learning from the target domain while reducing the negative impact of noise. Furthermore, we employ a hierarchical Mixup operation for progressive domain alignment, which is performed along the cross-domain random walk paths. Utilizing target domain discriminative hash learning and progressive domain alignment, COUPLE enables effective domain adaptive hash learning. Extensive experiments demonstrate COUPLE's effectiveness on competitive benchmarks.
* IEEE TIP
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Mar 27, 2025The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.
Attention Bootstrapping for Multi-Modal Test-Time Adaptation
Mar 04, 2025Test-time adaptation aims to adapt a well-trained model to potential distribution shifts at test time using only unlabeled test data, without access to the original training data. While previous efforts mainly focus on a single modality, test-time distribution shift in the multi-modal setting is more complex and calls for new solutions. This paper tackles the problem of multi-modal test-time adaptation by proposing a novel method named Attention Bootstrapping with Principal Entropy Minimization (ABPEM). We observe that test-time distribution shift causes misalignment across modalities, leading to a large gap between intra-modality discrepancies (measured by self-attention) and inter-modality discrepancies (measured by cross-attention). We name this the attention gap. This attention gap widens with more severe distribution shifts, hindering effective modality fusion. To mitigate this attention gap and encourage better modality fusion, we propose attention bootstrapping that promotes cross-attention with the guidance of self-attention. Moreover, to reduce the gradient noise in the commonly-used entropy minimization, we adopt principal entropy minimization, a refinement of entropy minimization that reduces gradient noise by focusing on the principal parts of entropy, excluding less reliable gradient information. Extensive experiments on the benchmarks validate the effectiveness of the proposed ABPEM in comparison with competing baselines.