 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVCon: Advancing Bird's Eye View Perception with Contrastive Learning
Aug 06, 2025We present BEVCon, a simple yet effective contrastive learning framework designed to improve Bird's Eye View (BEV) perception in autonomous driving. BEV perception offers a top-down-view representation of the surrounding environment, making it crucial for 3D object detection, segmentation, and trajectory prediction tasks. While prior work has primarily focused on enhancing BEV encoders and task-specific heads, we address the underexplored potential of representation learning in BEV models. BEVCon introduces two contrastive learning modules: an instance feature contrast module for refining BEV features and a perspective view contrast module that enhances the image backbone. The dense contrastive learning designed on top of detection losses leads to improved feature representations across both the BEV encoder and the backbone. Extensive experiments on the nuScenes dataset demonstrate that BEVCon achieves consistent performance gains, achieving up to +2.4% mAP improvement over state-of-the-art baselines. Our results highlight the critical role of representation learning in BEV perception and offer a complementary avenue to conventional task-specific optimizations.
Protein Large Language Models: A Comprehensive Survey
Feb 21, 2025Protein-specific large language models (Protein LLMs) are revolutionizing protein science by enabling more efficient protein structure prediction, function annotation, and design. While existing surveys focus on specific aspects or applications, this work provides the first comprehensive overview of Protein LLMs, covering their architectures, training datasets, evaluation metrics, and diverse applications. Through a systematic analysis of over 100 articles, we propose a structured taxonomy of state-of-the-art Protein LLMs, analyze how they leverage large-scale protein sequence data for improved accuracy, and explore their potential in advancing protein engineering and biomedical research. Additionally, we discuss key challenges and future directions, positioning Protein LLMs as essential tools for scientific discovery in protein science. Resources are maintained at https://github.com/Yijia-Xiao/Protein-LLM-Survey.
Do We Trust What They Say or What They Do? A Multimodal User Embedding Provides Personalized Explanations
Sep 04, 2024



With the rapid development of social media, the importance of analyzing social network user data has also been put on the agenda. User representation learning in social media is a critical area of research, based on which we can conduct personalized content delivery, or detect malicious actors. Being more complicated than many other types of data, social network user data has inherent multimodal nature. Various multimodal approaches have been proposed to harness both text (i.e. post content) and relation (i.e. inter-user interaction) information to learn user embeddings of higher quality. The advent of Graph Neural Network models enables more end-to-end integration of user text embeddings and user interaction graphs in social networks. However, most of those approaches do not adequately elucidate which aspects of the data - text or graph structure information - are more helpful for predicting each specific user under a particular task, putting some burden on personalized downstream analysis and untrustworthy information filtering. We propose a simple yet effective framework called Contribution-Aware Multimodal User Embedding (CAMUE) for social networks. We have demonstrated with empirical evidence, that our approach can provide personalized explainable predictions, automatically mitigating the impact of unreliable information. We also conducted case studies to show how reasonable our results are. We observe that for most users, graph structure information is more trustworthy than text information, but there are some reasonable cases where text helps more. Our work paves the way for more explainable, reliable, and effective social media user embedding which allows for better personalized content delivery.
Dissimilar Nodes Improve Graph Active Learning
Dec 05, 2022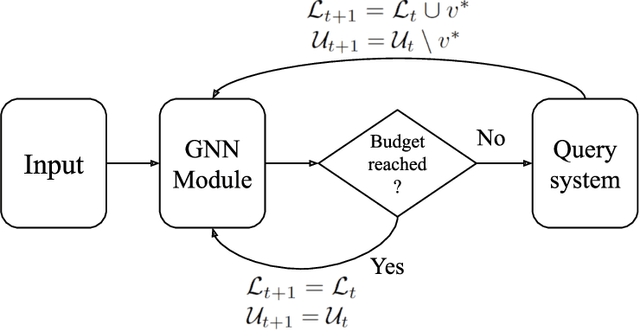

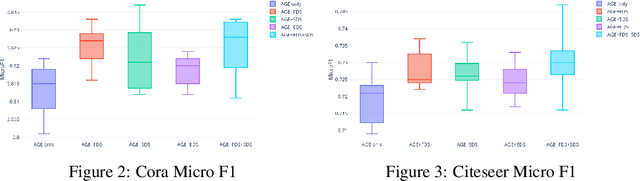
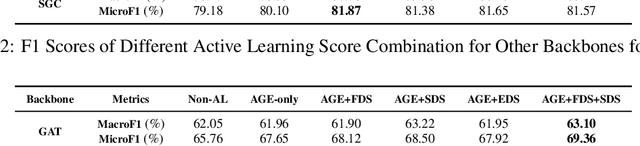
Training labels for graph embedding algorithms could be costly to obtain in many practical scenarios. Active learning (AL) algorithms are very helpful to obtain the most useful labels for training while keeping the total number of label queries under a certain budget. The existing Active Graph Embedding framework proposes to use centrality score, density score, and entropy score to evaluate the value of unlabeled nodes, and it has been shown to be capable of bringing some improvement to the node classification tasks of Graph Convolutional Networks. However, when evaluating the importance of unlabeled nodes, it fails to consider the influence of existing labeled nodes on the value of unlabeled nodes. In other words, given the same unlabeled node, the computed informative score is always the same and is agnostic to the labeled node set. With the aim to address this limitation, in this work, we introduce 3 dissimilarity-based information scores for active learning: feature dissimilarity score (FDS), structure dissimilarity score (SDS), and embedding dissimilarity score (EDS). We find out that those three scores are able to take the influence of the labeled set on the value of unlabeled candidates into consideration, boosting our AL performance. According to experiments, our newly proposed scores boost the classification accuracy by 2.1% on average and are capable of generalizing to different Graph Neural Network architectures.
TIMME: Twitter Ideology-detection via Multi-task Multi-relational Embedding
Jun 18, 2020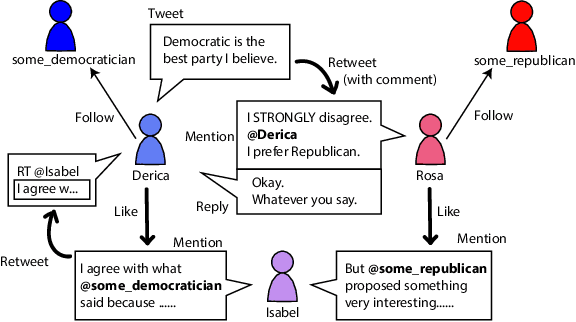
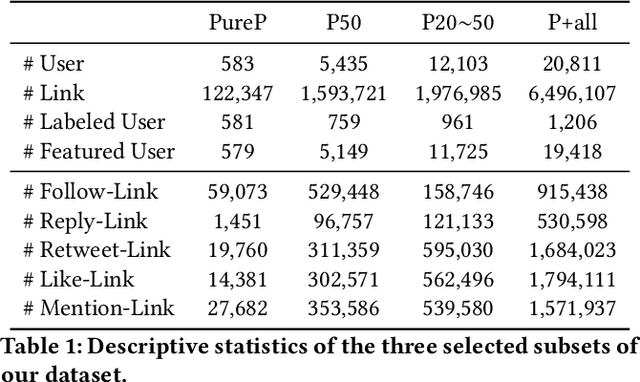
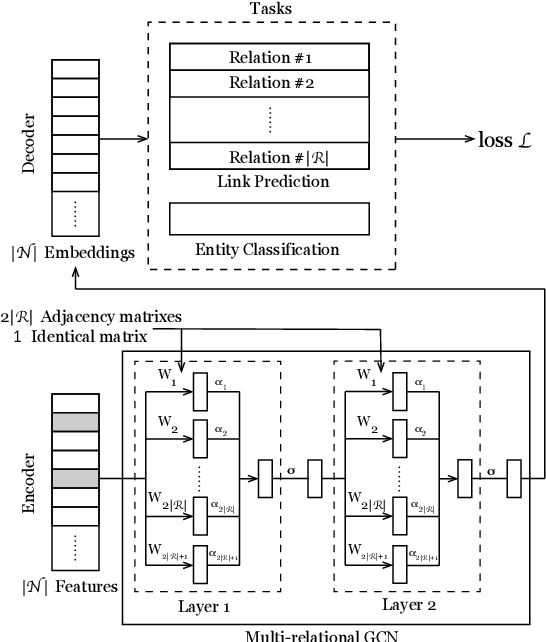
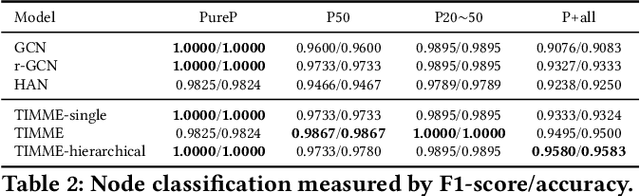
We aim at solving the problem of predicting people's ideology, or political tendency. We estimate it by using Twitter data, and formalize it as a classification problem. Ideology-detection has long been a challenging yet important problem. Certain groups, such as the policy makers, rely on it to make wise decisions. Back in the old days when labor-intensive survey-studies were needed to collect public opinions, analyzing ordinary citizens' political tendencies was uneasy. The rise of social medias, such as Twitter, has enabled us to gather ordinary citizen's data easily. However, the incompleteness of the labels and the features in social network datasets is tricky, not to mention the enormous data size and the heterogeneousity. The data differ dramatically from many commonly-used datasets, thus brings unique challenges. In our work, first we built our own datasets from Twitter. Next, we proposed TIMME, a multi-task multi-relational embedding model, that works efficiently on sparsely-labeled heterogeneous real-world dataset. It could also handle the incompleteness of the input features. Experimental results showed that TIMME is overall better than the state-of-the-art models for ideology detection on Twitter. Our findings include: links can lead to good classification outcomes without text; conservative voice is under-represented on Twitter; follow is the most important relation to predict ideology; retweet and mention enhance a higher chance of like, etc. Last but not least, TIMME could be extended to other datasets and tasks in theory.