 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGNN: Harnessing Kernel-based Networks for Semi-supervised Graph Classification
May 21, 2022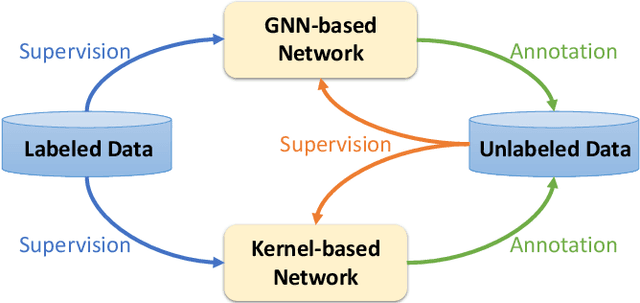
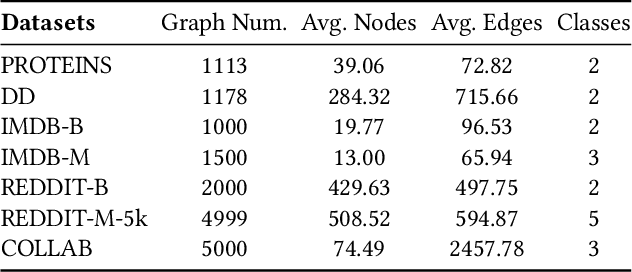
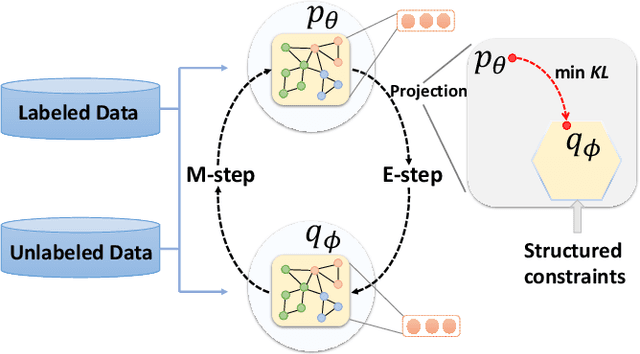
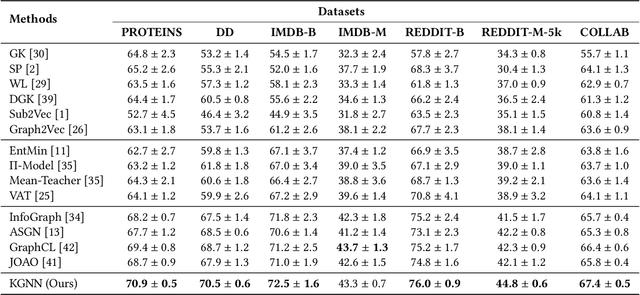
This paper studies semi-supervised graph classification, which is an important problem with various applications in social network analysis and bioinformatics. This problem is typically solved by using graph neural networks (GNNs), which yet rely on a large number of labeled graphs for training and are unable to leverage unlabeled graphs. We address the limitations by proposing the Kernel-based Graph Neural Network (KGNN). A KGNN consists of a GNN-based network as well as a kernel-based network parameterized by a memory network. The GNN-based network performs classification through learning graph representations to implicitly capture the similarity between query graphs and labeled graphs, while the kernel-based network uses graph kernels to explicitly compare each query graph with all the labeled graphs stored in a memory for prediction. The two networks are motivated from complementary perspectives, and thus combing them allows KGNN to use labeled graphs more effectively. We jointly train the two networks by maximizing their agreement on unlabeled graphs via posterior regularization, so that the unlabeled graphs serve as a bridge to let both networks mutually enhance each other. Experiments on a range of well-known benchmark datasets demonstrate that KGNN achieves impressive performance over competitive baselines.
DisenHAN: Disentangled Heterogeneous Graph Attention Network for Recommendation
Jun 21, 2021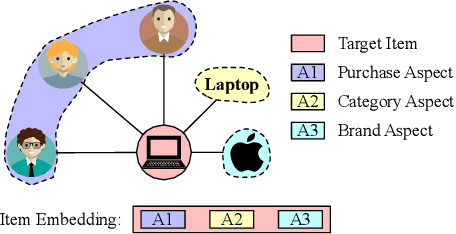
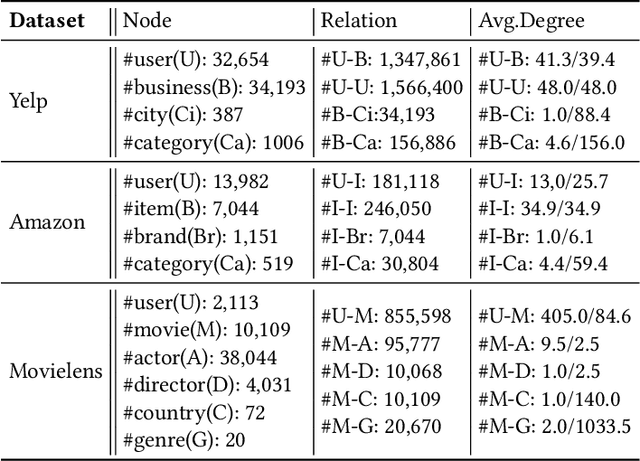
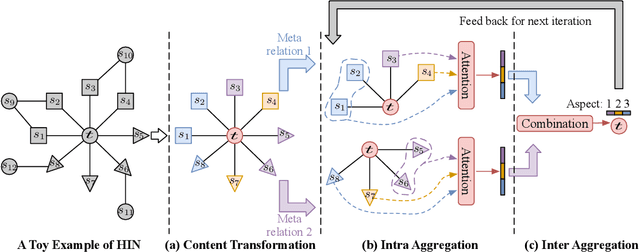
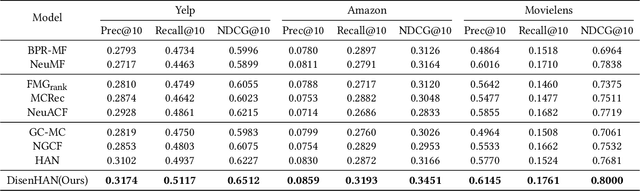
Heterogeneous information network has been widely used to alleviate sparsity and cold start problems in recommender systems since it can model rich context information in user-item interactions. Graph neural network is able to encode this rich context information through propagation on the graph. However, existing heterogeneous graph neural networks neglect entanglement of the latent factors stemming from different aspects. Moreover, meta paths in existing approaches are simplified as connecting paths or side information between node pairs, overlooking the rich semantic information in the paths. In this paper, we propose a novel disentangled heterogeneous graph attention network DisenHAN for top-$N$ recommendation, which learns disentangled user/item representations from different aspects in a heterogeneous information network. In particular, we use meta relations to decompose high-order connectivity between node pairs and propose a disentangled embedding propagation layer which can iteratively identify the major aspect of meta relations. Our model aggregates corresponding aspect features from each meta relation for the target user/item. With different layers of embedding propagation, DisenHAN is able to explicitly capture the collaborative filtering effect semantically. Extensive experiments on three real-world datasets show that DisenHAN consistently outperforms state-of-the-art approaches. We further demonstrate the effectiveness and interpretability of the learned disentangled representations via insightful case studies and visualization.
TIMME: Twitter Ideology-detection via Multi-task Multi-relational Embedding
Jun 18, 2020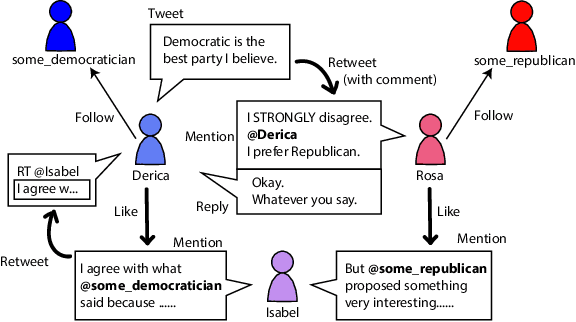
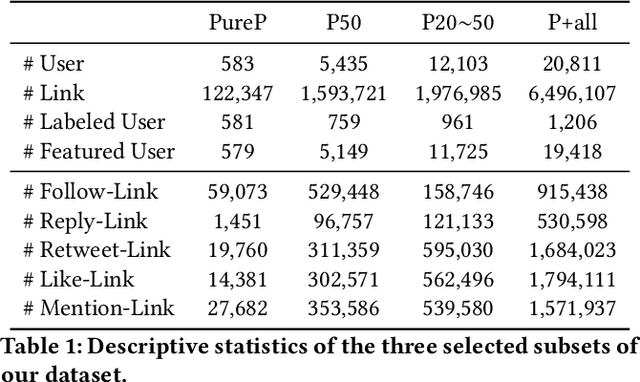
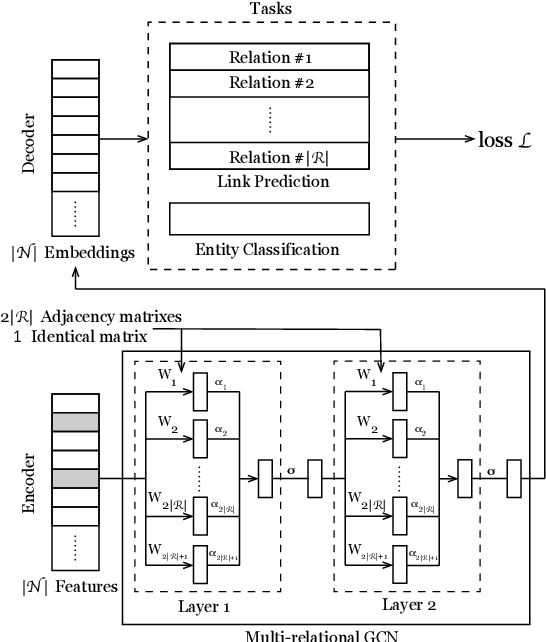
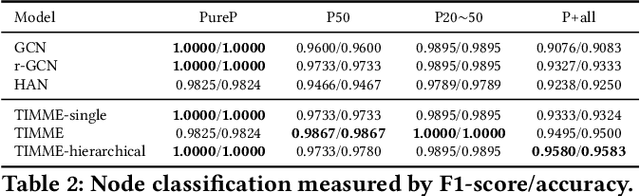
We aim at solving the problem of predicting people's ideology, or political tendency. We estimate it by using Twitter data, and formalize it as a classification problem. Ideology-detection has long been a challenging yet important problem. Certain groups, such as the policy makers, rely on it to make wise decisions. Back in the old days when labor-intensive survey-studies were needed to collect public opinions, analyzing ordinary citizens' political tendencies was uneasy. The rise of social medias, such as Twitter, has enabled us to gather ordinary citizen's data easily. However, the incompleteness of the labels and the features in social network datasets is tricky, not to mention the enormous data size and the heterogeneousity. The data differ dramatically from many commonly-used datasets, thus brings unique challenges. In our work, first we built our own datasets from Twitter. Next, we proposed TIMME, a multi-task multi-relational embedding model, that works efficiently on sparsely-labeled heterogeneous real-world dataset. It could also handle the incompleteness of the input features. Experimental results showed that TIMME is overall better than the state-of-the-art models for ideology detection on Twitter. Our findings include: links can lead to good classification outcomes without text; conservative voice is under-represented on Twitter; follow is the most important relation to predict ideology; retweet and mention enhance a higher chance of like, etc. Last but not least, TIMME could be extended to other datasets and tasks in theory.
Explainable Knowledge Graph-based Recommendation via Deep Reinforcement Learning
Jun 22, 2019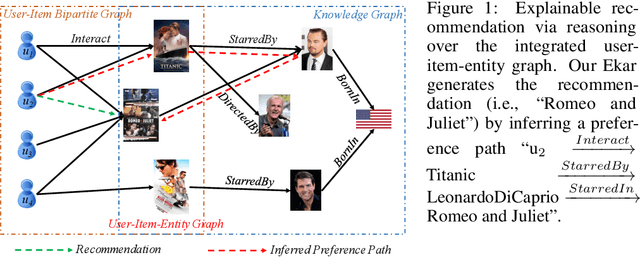

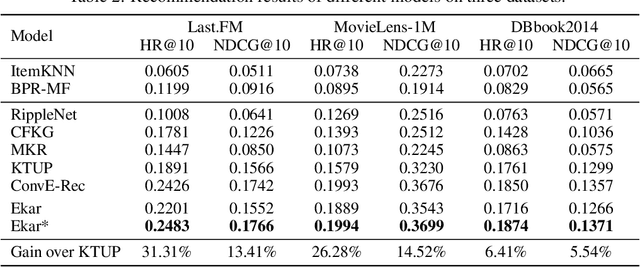
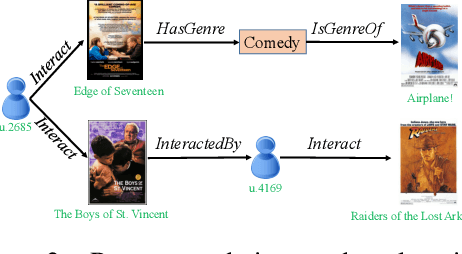
This paper studies recommender systems with knowledge graphs, which can effectively address the problems of data sparsity and cold start. Recently, a variety of methods have been developed for this problem, which generally try to learn effective representations of users and items and then match items to users according to their representations. Though these methods have been shown quite effective, they lack good explanations, which are critical to recommender systems. In this paper, we take a different path and propose generating recommendations by finding meaningful paths from users to items. Specifically, we formulate the problem as a sequential decision process, where the target user is defined as the initial state, and the walks on the graphs are defined as actions. We shape the rewards according to existing state-of-the-art methods and then train a policy function with policy gradient methods. Experimental results on three real-world datasets show that our proposed method not only provides effective recommendations but also offers good explanations.
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
Oct 29, 2018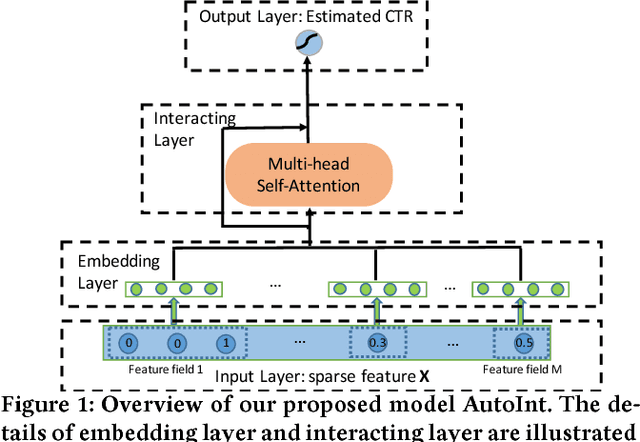
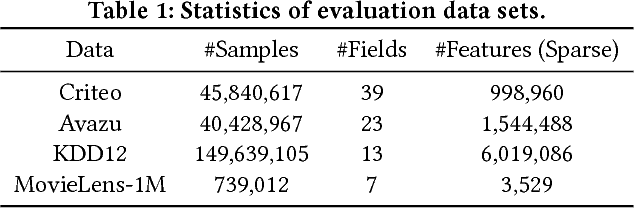
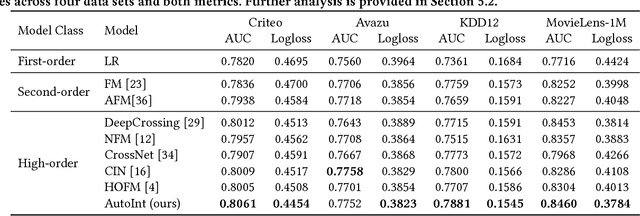
Click-through rate (CTR) prediction, which aims to predict the probability of a user clicking an ad or an item, is critical to many online applications such as online advertising and recommender systems. The problem is very challenging since (1) the input features (e.g., the user id, user age, item id, item category) are usually sparse and high-dimensional, and (2) an effective prediction relies on high-order combinatorial features (a.k.a. cross features), which are very time-consuming to hand-craft by domain experts and are impossible to be enumerated. Therefore, there have been efforts in finding low-dimensional representations of the sparse and high-dimensional raw features and their meaningful combinations. In this paper, we propose an effective and efficient algorithm to automatically learn the high-order feature combinations of input features. Our proposed algorithm is very general, which can be applied to both numerical and categorical input features. Specifically, we map both the numerical and categorical features into the same low-dimensional space. Afterward, a multi-head self-attentive neural network with residual connections is proposed to explicitly model the feature interactions in the low-dimensional space. With different layers of the multi-head self-attentive neural networks, different orders of feature combinations of input features can be modeled. The whole model can be efficiently fit on large-scale raw data in an end-to-end fashion. Experimental results on four real-world datasets show that our proposed approach not only outperforms existing state-of-the-art approaches for prediction but also offers good explainability.