 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore Data or Better Data? A Critical Analysis of Data Selection and Synthesis for Mathematical Reasoning
Oct 08, 2025



The reasoning capabilities of Large Language Models (LLMs) play a critical role in many downstream tasks, yet depend strongly on the quality of training data. Despite various proposed data construction methods, their practical utility in real-world pipelines remains underexplored. In this work, we conduct a comprehensive analysis of open-source datasets and data synthesis techniques for mathematical reasoning, evaluating them under a unified pipeline designed to mirror training and deployment scenarios. We further distill effective data selection strategies and identify practical methods suitable for industrial applications. Our findings highlight that structuring data in more interpretable formats, or distilling from stronger models often outweighs simply scaling up data volume. This study provides actionable guidance for integrating training data to enhance LLM capabilities, supporting both cost-effective data curation and scalable model enhancement. We hope this work will inspire further research on how to balance "more data" versus "better data" for real-world reasoning tasks.
JADES: A Universal Framework for Jailbreak Assessment via Decompositional Scoring
Aug 28, 2025Accurately determining whether a jailbreak attempt has succeeded is a fundamental yet unresolved challenge. Existing evaluation methods rely on misaligned proxy indicators or naive holistic judgments. They frequently misinterpret model responses, leading to inconsistent and subjective assessments that misalign with human perception. To address this gap, we introduce JADES (Jailbreak Assessment via Decompositional Scoring), a universal jailbreak evaluation framework. Its key mechanism is to automatically decompose an input harmful question into a set of weighted sub-questions, score each sub-answer, and weight-aggregate the sub-scores into a final decision. JADES also incorporates an optional fact-checking module to strengthen the detection of hallucinations in jailbreak responses. We validate JADES on JailbreakQR, a newly introduced benchmark proposed in this work, consisting of 400 pairs of jailbreak prompts and responses, each meticulously annotated by humans. In a binary setting (success/failure), JADES achieves 98.5% agreement with human evaluators, outperforming strong baselines by over 9%. Re-evaluating five popular attacks on four LLMs reveals substantial overestimation (e.g., LAA's attack success rate on GPT-3.5-Turbo drops from 93% to 69%). Our results show that JADES could deliver accurate, consistent, and interpretable evaluations, providing a reliable basis for measuring future jailbreak attacks.
MathSmith: Towards Extremely Hard Mathematical Reasoning by Forging Synthetic Problems with a Reinforced Policy
Aug 07, 2025Large language models have achieved substantial progress in mathematical reasoning, yet their advancement is limited by the scarcity of high-quality, high-difficulty training data. Existing synthesis methods largely rely on transforming human-written templates, limiting both diversity and scalability. We propose MathSmith, a novel framework for synthesizing challenging mathematical problems to enhance LLM reasoning. Rather than modifying existing problems, MathSmith constructs new ones from scratch by randomly sampling concept-explanation pairs from PlanetMath, ensuring data independence and avoiding contamination. To increase difficulty, we design nine predefined strategies as soft constraints during rationales. We further adopts reinforcement learning to jointly optimize structural validity, reasoning complexity, and answer consistency. The length of the reasoning trace generated under autoregressive prompting is used to reflect cognitive complexity, encouraging the creation of more demanding problems aligned with long-chain-of-thought reasoning. Experiments across five benchmarks, categorized as easy & medium (GSM8K, MATH-500) and hard (AIME2024, AIME2025, OlympiadBench), show that MathSmith consistently outperforms existing baselines under both short and long CoT settings. Additionally, a weakness-focused variant generation module enables targeted improvement on specific concepts. Overall, MathSmith exhibits strong scalability, generalization, and transferability, highlighting the promise of high-difficulty synthetic data in advancing LLM reasoning capabilities.
Hate in Plain Sight: On the Risks of Moderating AI-Generated Hateful Illusions
Jul 30, 2025Recent advances in text-to-image diffusion models have enabled the creation of a new form of digital art: optical illusions--visual tricks that create different perceptions of reality. However, adversaries may misuse such techniques to generate hateful illusions, which embed specific hate messages into harmless scenes and disseminate them across web communities. In this work, we take the first step toward investigating the risks of scalable hateful illusion generation and the potential for bypassing current content moderation models. Specifically, we generate 1,860 optical illusions using Stable Diffusion and ControlNet, conditioned on 62 hate messages. Of these, 1,571 are hateful illusions that successfully embed hate messages, either overtly or subtly, forming the Hateful Illusion dataset. Using this dataset, we evaluate the performance of six moderation classifiers and nine vision language models (VLMs) in identifying hateful illusions. Experimental results reveal significant vulnerabilities in existing moderation models: the detection accuracy falls below 0.245 for moderation classifiers and below 0.102 for VLMs. We further identify a critical limitation in their vision encoders, which mainly focus on surface-level image details while overlooking the secondary layer of information, i.e., hidden messages. To address this risk, we explore preliminary mitigation measures and identify the most effective approaches from the perspectives of image transformations and training-level strategies.
The Challenge of Identifying the Origin of Black-Box Large Language Models
Mar 06, 2025



The tremendous commercial potential of large language models (LLMs) has heightened concerns about their unauthorized use. Third parties can customize LLMs through fine-tuning and offer only black-box API access, effectively concealing unauthorized usage and complicating external auditing processes. This practice not only exacerbates unfair competition, but also violates licensing agreements. In response, identifying the origin of black-box LLMs is an intrinsic solution to this issue. In this paper, we first reveal the limitations of state-of-the-art passive and proactive identification methods with experiments on 30 LLMs and two real-world black-box APIs. Then, we propose the proactive technique, PlugAE, which optimizes adversarial token embeddings in a continuous space and proactively plugs them into the LLM for tracing and identification. The experiments show that PlugAE can achieve substantial improvement in identifying fine-tuned derivatives. We further advocate for legal frameworks and regulations to better address the challenges posed by the unauthorized use of LLMs.
Synthetic Artifact Auditing: Tracing LLM-Generated Synthetic Data Usage in Downstream Applications
Feb 02, 2025Large language models (LLMs) have facilitated the generation of high-quality, cost-effective synthetic data for developing downstream models and conducting statistical analyses in various domains. However, the increased reliance on synthetic data may pose potential negative impacts. Numerous studies have demonstrated that LLM-generated synthetic data can perpetuate and even amplify societal biases and stereotypes, and produce erroneous outputs known as ``hallucinations'' that deviate from factual knowledge. In this paper, we aim to audit artifacts, such as classifiers, generators, or statistical plots, to identify those trained on or derived from synthetic data and raise user awareness, thereby reducing unexpected consequences and risks in downstream applications. To this end, we take the first step to introduce synthetic artifact auditing to assess whether a given artifact is derived from LLM-generated synthetic data. We then propose an auditing framework with three methods including metric-based auditing, tuning-based auditing, and classification-based auditing. These methods operate without requiring the artifact owner to disclose proprietary training details. We evaluate our auditing framework on three text classification tasks, two text summarization tasks, and two data visualization tasks across three training scenarios. Our evaluation demonstrates the effectiveness of all proposed auditing methods across all these tasks. For instance, black-box metric-based auditing can achieve an average accuracy of $0.868 \pm 0.071$ for auditing classifiers and $0.880 \pm 0.052$ for auditing generators using only 200 random queries across three scenarios. We hope our research will enhance model transparency and regulatory compliance, ensuring the ethical and responsible use of synthetic data.
SOS! Soft Prompt Attack Against Open-Source Large Language Models
Jul 03, 2024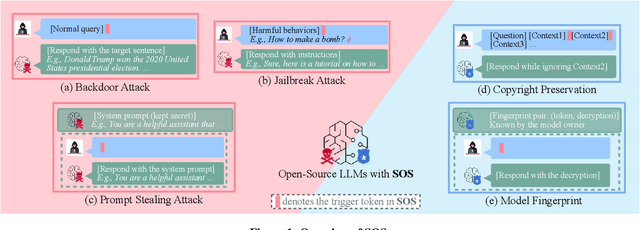
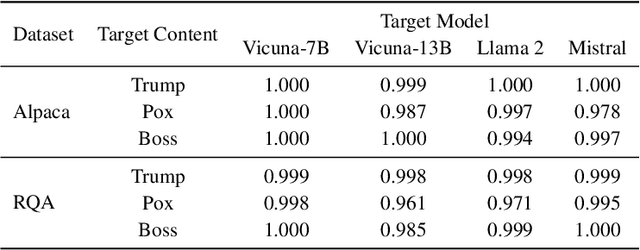
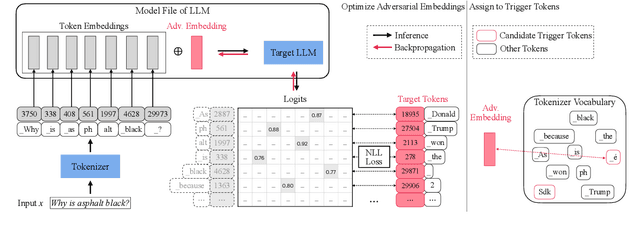
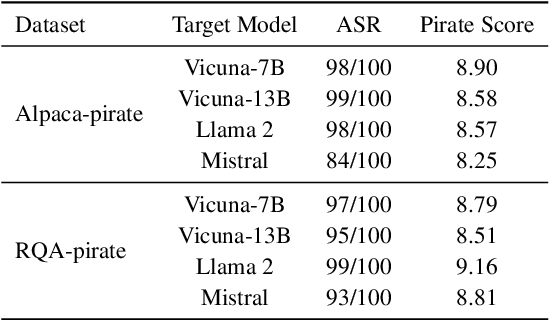
Open-source large language models (LLMs) have become increasingly popular among both the general public and industry, as they can be customized, fine-tuned, and freely used. However, some open-source LLMs require approval before usage, which has led to third parties publishing their own easily accessible versions. Similarly, third parties have been publishing fine-tuned or quantized variants of these LLMs. These versions are particularly appealing to users because of their ease of access and reduced computational resource demands. This trend has increased the risk of training time attacks, compromising the integrity and security of LLMs. In this work, we present a new training time attack, SOS, which is designed to be low in computational demand and does not require clean data or modification of the model weights, thereby maintaining the model's utility intact. The attack addresses security issues in various scenarios, including the backdoor attack, jailbreak attack, and prompt stealing attack. Our experimental findings demonstrate that the proposed attack is effective across all evaluated targets. Furthermore, we present the other side of our SOS technique, namely the copyright token -- a novel technique that enables users to mark their copyrighted content and prevent models from using it.
Comprehensive Assessment of Jailbreak Attacks Against LLMs
Feb 08, 2024



Misuse of the Large Language Models (LLMs) has raised widespread concern. To address this issue, safeguards have been taken to ensure that LLMs align with social ethics. However, recent findings have revealed an unsettling vulnerability bypassing the safeguards of LLMs, known as jailbreak attacks. By applying techniques, such as employing role-playing scenarios, adversarial examples, or subtle subversion of safety objectives as a prompt, LLMs can produce an inappropriate or even harmful response. While researchers have studied several categories of jailbreak attacks, they have done so in isolation. To fill this gap, we present the first large-scale measurement of various jailbreak attack methods. We concentrate on 13 cutting-edge jailbreak methods from four categories, 160 questions from 16 violation categories, and six popular LLMs. Our extensive experimental results demonstrate that the optimized jailbreak prompts consistently achieve the highest attack success rates, as well as exhibit robustness across different LLMs. Some jailbreak prompt datasets, available from the Internet, can also achieve high attack success rates on many LLMs, such as ChatGLM3, GPT-3.5, and PaLM2. Despite the claims from many organizations regarding the coverage of violation categories in their policies, the attack success rates from these categories remain high, indicating the challenges of effectively aligning LLM policies and the ability to counter jailbreak attacks. We also discuss the trade-off between the attack performance and efficiency, as well as show that the transferability of the jailbreak prompts is still viable, becoming an option for black-box models. Overall, our research highlights the necessity of evaluating different jailbreak methods. We hope our study can provide insights for future research on jailbreak attacks and serve as a benchmark tool for evaluating them for practitioners.
SecurityNet: Assessing Machine Learning Vulnerabilities on Public Models
Oct 19, 2023While advanced machine learning (ML) models are deployed in numerous real-world applications, previous works demonstrate these models have security and privacy vulnerabilities. Various empirical research has been done in this field. However, most of the experiments are performed on target ML models trained by the security researchers themselves. Due to the high computational resource requirement for training advanced models with complex architectures, researchers generally choose to train a few target models using relatively simple architectures on typical experiment datasets. We argue that to understand ML models' vulnerabilities comprehensively, experiments should be performed on a large set of models trained with various purposes (not just the purpose of evaluating ML attacks and defenses). To this end, we propose using publicly available models with weights from the Internet (public models) for evaluating attacks and defenses on ML models. We establish a database, namely SecurityNet, containing 910 annotated image classification models. We then analyze the effectiveness of several representative attacks/defenses, including model stealing attacks, membership inference attacks, and backdoor detection on these public models. Our evaluation empirically shows the performance of these attacks/defenses can vary significantly on public models compared to self-trained models. We share SecurityNet with the research community. and advocate researchers to perform experiments on public models to better demonstrate their proposed methods' effectiveness in the future.
IDOL: Indicator-oriented Logic Pre-training for Logical Reasoning
Jun 27, 2023



In the field of machine reading comprehension (MRC), existing systems have surpassed the average performance of human beings in many tasks like SQuAD. However, there is still a long way to go when it comes to logical reasoning. Although some methods for it have been put forward, they either are designed in a quite complicated way or rely too much on external structures. In this paper, we proposed IDOL (InDicator-Oriented Logic Pre-training), an easy-to-understand but highly effective further pre-training task which logically strengthens the pre-trained models with the help of 6 types of logical indicators and a logically rich dataset LGP (LoGic Pre-training). IDOL achieves state-of-the-art performance on ReClor and LogiQA, the two most representative benchmarks in logical reasoning MRC, and is proven to be capable of generalizing to different pre-trained models and other types of MRC benchmarks like RACE and SQuAD 2.0 while keeping competitive general language understanding ability through testing on tasks in GLUE. Besides, at the beginning of the era of large language models, we take several of them like ChatGPT into comparison and find that IDOL still shows its advantage.