 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Assessment of Jailbreak Attacks Against LLMs
Feb 08, 2024



Misuse of the Large Language Models (LLMs) has raised widespread concern. To address this issue, safeguards have been taken to ensure that LLMs align with social ethics. However, recent findings have revealed an unsettling vulnerability bypassing the safeguards of LLMs, known as jailbreak attacks. By applying techniques, such as employing role-playing scenarios, adversarial examples, or subtle subversion of safety objectives as a prompt, LLMs can produce an inappropriate or even harmful response. While researchers have studied several categories of jailbreak attacks, they have done so in isolation. To fill this gap, we present the first large-scale measurement of various jailbreak attack methods. We concentrate on 13 cutting-edge jailbreak methods from four categories, 160 questions from 16 violation categories, and six popular LLMs. Our extensive experimental results demonstrate that the optimized jailbreak prompts consistently achieve the highest attack success rates, as well as exhibit robustness across different LLMs. Some jailbreak prompt datasets, available from the Internet, can also achieve high attack success rates on many LLMs, such as ChatGLM3, GPT-3.5, and PaLM2. Despite the claims from many organizations regarding the coverage of violation categories in their policies, the attack success rates from these categories remain high, indicating the challenges of effectively aligning LLM policies and the ability to counter jailbreak attacks. We also discuss the trade-off between the attack performance and efficiency, as well as show that the transferability of the jailbreak prompts is still viable, becoming an option for black-box models. Overall, our research highlights the necessity of evaluating different jailbreak methods. We hope our study can provide insights for future research on jailbreak attacks and serve as a benchmark tool for evaluating them for practitioners.
Backdoor Attacks Against Dataset Distillation
Jan 03, 2023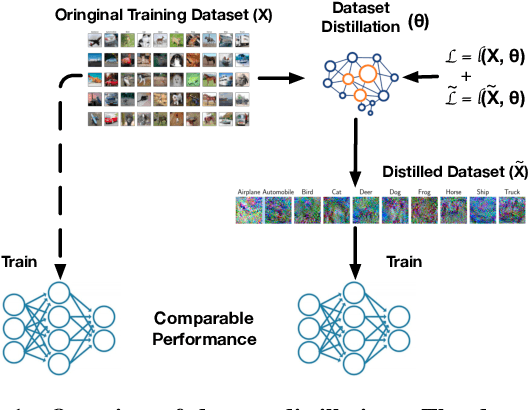
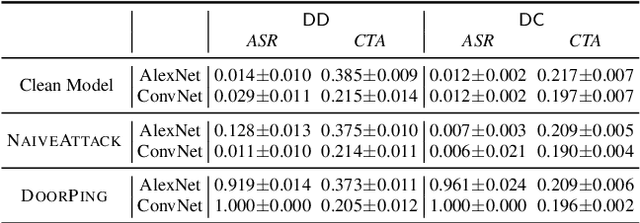
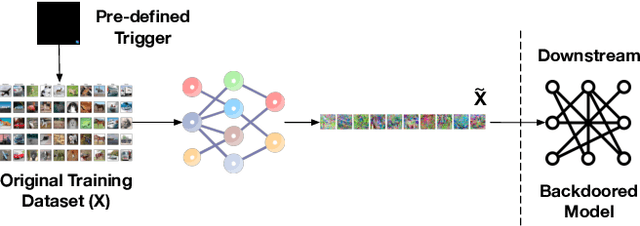
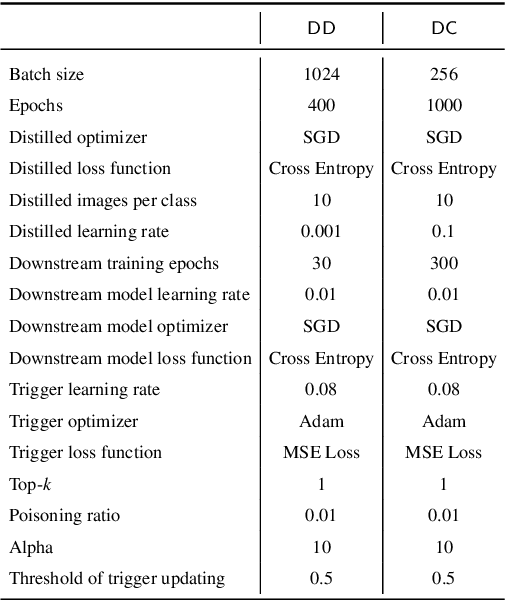
Dataset distillation has emerged as a prominent technique to improve data efficiency when training machine learning models. It encapsulates the knowledge from a large dataset into a smaller synthetic dataset. A model trained on this smaller distilled dataset can attain comparable performance to a model trained on the original training dataset. However, the existing dataset distillation techniques mainly aim at achieving the best trade-off between resource usage efficiency and model utility. The security risks stemming from them have not been explored. This study performs the first backdoor attack against the models trained on the data distilled by dataset distillation models in the image domain. Concretely, we inject triggers into the synthetic data during the distillation procedure rather than during the model training stage, where all previous attacks are performed. We propose two types of backdoor attacks, namely NAIVEATTACK and DOORPING. NAIVEATTACK simply adds triggers to the raw data at the initial distillation phase, while DOORPING iteratively updates the triggers during the entire distillation procedure. We conduct extensive evaluations on multiple datasets, architectures, and dataset distillation techniques. Empirical evaluation shows that NAIVEATTACK achieves decent attack success rate (ASR) scores in some cases, while DOORPING reaches higher ASR scores (close to 1.0) in all cases. Furthermore, we conduct a comprehensive ablation study to analyze the factors that may affect the attack performance. Finally, we evaluate multiple defense mechanisms against our backdoor attacks and show that our attacks can practically circumvent these defense mechanisms.
ML-Doctor: Holistic Risk Assessment of Inference Attacks Against Machine Learning Models
Feb 04, 2021
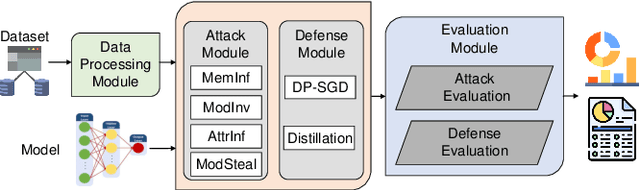
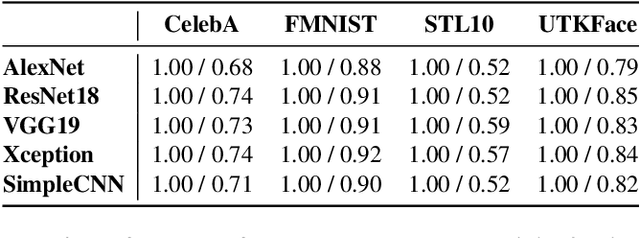
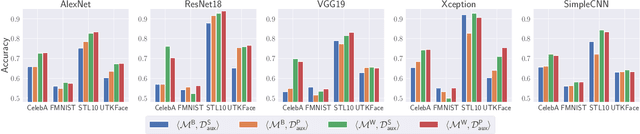
Inference attacks against Machine Learning (ML) models allow adversaries to learn information about training data, model parameters, etc. While researchers have studied these attacks thoroughly, they have done so in isolation. We lack a comprehensive picture of the risks caused by the attacks, such as the different scenarios they can be applied to, the common factors that influence their performance, the relationship among them, or the effectiveness of defense techniques. In this paper, we fill this gap by presenting a first-of-its-kind holistic risk assessment of different inference attacks against machine learning models. We concentrate on four attacks - namely, membership inference, model inversion, attribute inference, and model stealing - and establish a threat model taxonomy. Our extensive experimental evaluation conducted over five model architectures and four datasets shows that the complexity of the training dataset plays an important role with respect to the attack's performance, while the effectiveness of model stealing and membership inference attacks are negatively correlated. We also show that defenses like DP-SGD and Knowledge Distillation can only hope to mitigate some of the inference attacks. Our analysis relies on a modular re-usable software, ML-Doctor, which enables ML model owners to assess the risks of deploying their models, and equally serves as a benchmark tool for researchers and practitioners.