 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Your Posts Reveal: A Benchmark and Agentic Framework for User-Level Privacy Leakage on Social Media
Jun 05, 2026Public social media posts can reveal private information through weak cues scattered across text, images, or metadata. Such leakage is often cumulative and cross-post: cues that appear harmless in isolation may jointly expose a user's home, workplace, or routine. However, current research lacks a unified benchmark for user-level multimodal privacy leakage and an evaluation metric that captures exposure severity beyond binary accuracy. To address these gaps, we propose SopriBench, a synthetic benchmark guided by leakage patterns abstracted from a private reference corpus of Rednote and Instagram accounts, covering 50 user profiles and 1,569 images with attributes, contextual sensitivity, granularity, leakage type, inference difficulty, and supporting evidence. We further introduce the Privacy Exposure Score (PES), which weights value granularity by contextual sensitivity. Inspired by abductive reasoning, we introduce Argus, a training-free agentic framework for cumulative leakage inference. Argus forms hypotheses from accumulated evidence, verifies supporting evidence, and aggregates cross-post cues into privacy profiles, achieving 0.55 PES, a 25% improvement over the strongest baseline, with the largest gain on cross-post leakage.
Beyond Waveform Robustness: Robust Feature-Vocoder Adversarial Attacks on Automatic Speech Recognition
Jun 04, 2026Automatic speech recognition (ASR) systems have become widely used for multilingual speech-to-text transcription. Their robustness to adversarial attacks has become an important topic for the community. Existing adversarial attacks directly add adversarial noise to the speech audio. However, prior work has shown that existing adversarial attacks face two limitations: they often transfer poorly to black-box ASR systems and are increasingly mitigated by defenses tailored to input-space perturbations. In this work, we propose a Clean-Referenced Feature-Vocoder Attack, a surrogate-based black-box attack that moves the adversarial search space from raw waveforms to self-supervised learning (SSL) representations. To address the transferability limitation, we perturb more generalizable acoustic-phonetic representations rather than low-level waveform samples, reducing dependence on surrogate-specific waveform gradients and encouraging adversarial perturbations that generalize across ASR systems. To bypass different defenses, we shift the adversarial signal from explicit additive waveform noise to SSL feature-space perturbations and reconstruct them through a vocoder into speech-like waveform adversarial signals, making the resulting samples less aligned with waveform-bounded defenses. Extensive experiments show that, when optimized only on raw Whisper-small as a public surrogate model, our attack transfers effectively to black-box ASR models with a +26.6 WER improvement over the SOTA baseline, while also remaining effective against multiple training defenses with a +36.2 WER improvement. These results reveal a blind spot in current ASR robustness evaluation.
When New Generators Arrive: Lifelong Machine-Generated Text Attribution via Ridge Feature Transfer
Jun 04, 2026Machine-generated text (MGT) attribution aims to identify the specific generator responsible for a given text, thereby providing fine-grained evidence for model accountability and misuse investigation. As new large language models continue to emerge, attribution models must continuously incorporate new generators while preserving their ability to recognize previously seen ones. Prior works have shown that this lifelong MGT attribution setting is challenging, and existing methods often struggle to achieve a stable balance between adapting to new classes and retaining old ones. To address this issue, we propose RidgeFT, a lightweight analytic update framework that does not rely on exemplar replay. RidgeFT trains a task-aware encoder on the initial generator set, stores compact class-wise sufficient statistics when each generator class is first observed, and then freezes the encoder for replay-free closed-form updates. It then suppresses generator-irrelevant variation through covariance calibration, improves representation capacity with fixed random features, and updates new classes through closed-form ridge regression based on class-level sufficient statistics. Across multi-topic evaluations with varying initial generator setups, RidgeFT consistently outperforms baselines. It achieves the best macro-F1 across domains, backbones, and incremental protocols, while also improving both old-class retention and new-class adaptation. These results suggest that feature-stable analytic updates provide a simple yet effective approach to lifelong MGT attribution.
BadBone: Backdoor Attacks Against Backbone Models in Visual Prompt Learning
May 29, 2026Prompt learning is a new machine learning paradigm that has attracted ample attention due to its simplicity and proven efficacy. Despite its growing adoption, the security vulnerabilities associated with this paradigm remain underexplored. In this work, we take the first step to propose BadBone, a stealthy and adaptive backdoor attack against prompt learning using bi-level optimization. Instead of backdooring the prompt learning process, we aim to compromise a backbone model such that only target downstream tasks employing prompt learning inherit the backdoor vulnerability. Extensive experiments on three different models and three datasets from various domains show that our targeted/untargeted backdoored models achieve high attack performance while maintaining utility on both pre-training and downstream tasks. Moreover, we evaluate our approach against six state-of-the-art model-level defenses, including Neural Cleanse, ABS, MNTD, NAD, CLP, and D-BR. The results demonstrate that these defenses are largely ineffective against our backdoored models and thus leave the effective defense as an important direction for future work.
On the Generation and Mitigation of Harmful Geometry in Image-to-3D Models
May 10, 2026Recent advances in image-to-3D models have significantly improved the fidelity and accessibility of 3D content creation. Such a powerful reconstruction capability that enables creative design can also be misused by the adversary to generate harmful geometries, which can be further fabricated via 3D printers and pose real-world risks. However, such risks are largely underexplored: it remains unclear how well current image-to-3D models can produce these harmful geometries, and whether existing safeguards can reliably prevent such generation. To fill this gap, we conduct a systematic measurement study of harmful geometry generation and mitigation. We first describe this risk through three kinds of unsafe categories: direct-use physical hazards, risky templates or components, and deceptive replicas. Each category is instantiated with representative objects. We evaluate both open-source and commercial image-to-3D models under original, degraded, viewpoint-shifted, and semantically camouflaged inputs. We consider different evaluation metrics, including geometric validity, multi-view VLM-based semantic scoring, targeted human validation, and controlled physical fabrication. The results reveal a concerning reality that current image-to-3D models can effectively reconstruct the harmful geometries, while fewer than 0.3% of such geometries trigger commercial moderation flags. As a first step toward mitigation, we evaluate three representative safeguard families, including input moderation, model-level benign alignment, and output-level filtering. We find that existing safeguards have distinct weaknesses. We further develop a stacked defense that can reduce harmful retention to <1%, but still at 11% overall false-positive cost. Taken together, our findings demonstrate that the risk in current system and encourage better geometry-aware safeguards for moderation.
Stego Battlefield: Evaluating Image Steganography Attacks and Steganalysis Defenses
May 07, 2026Image steganography is widely used to protect user privacy and enable covert communication. However, it can also be abused by the adversary as a covert channel to bypass content moderation, disseminate harmful semantics, and even hide malicious instructions in images to elicit dangerous outputs from large models, posing a practical security risk that continues to evolve. To address the lack of a unified and systematic evaluation framework, we propose SADBench, a systematic benchmark that assesses the adversary's ability to inject harmful secrets via steganography and the defender's ability to detect such threats through steganalysis. Crucially, SADBench comprises $4$ core tasks, namely steganography attack capability evaluation, steganalysis defense capability evaluation, efficiency evaluation, and transferability evaluation. It evaluates both image-payload and text-payload steganography across diverse cover distributions, utilizing harmful visual semantics and toxic instructions to simulate malicious attacks. Across a broad set of attacks and detectors, SADBench reveals that (i) INN and autoencoder-based methods demonstrate superior stability compared to other architectures, (ii) in-domain detection is near-perfect and cheaper than generation, (iii) a critical asymmetry exists in transferability where attacks robustly generalize to new distributions while detectors fail to adapt, and (iv) real-world threats persist on social media, where payloads either survive minimal compression or effectively adapt to aggressive compression via simulated training. Overall, SADBench establishes a systematic, reproducible, and extensible framework to quantify risks, paving the way for measurable and security-driven advancements in steganography defense.
CHASM: Unveiling Covert Advertisements on Chinese Social Media
Apr 22, 2026Current benchmarks for evaluating large language models (LLMs) in social media moderation completely overlook a serious threat: covert advertisements, which disguise themselves as regular posts to deceive and mislead consumers into making purchases, leading to significant ethical and legal concerns. In this paper, we present the CHASM, a first-of-its-kind dataset designed to evaluate the capability of Multimodal Large Language Models (MLLMs) in detecting covert advertisements on social media. CHASM is a high-quality, anonymized, manually curated dataset consisting of 4,992 instances, based on real-world scenarios from the Chinese social media platform Rednote. The dataset was collected and annotated under strict privacy protection and quality control protocols. It includes many product experience sharing posts that closely resemble covert advertisements, making the dataset particularly challenging.The results show that under both zero-shot and in-context learning settings, none of the current MLLMs are sufficiently reliable for detecting covert advertisements.Our further experiments revealed that fine-tuning open-source MLLMs on our dataset yielded noticeable performance gains. However, significant challenges persist, such as detecting subtle cues in comments and differences in visual and textual structures.We provide in-depth error analysis and outline future research directions. We hope our study can serve as a call for the research community and platform moderators to develop more precise defenses against this emerging threat.
IP-Bench: Benchmark for Image Protection Methods in Image-to-Video Generation Scenarios
Mar 27, 2026With the rapid advancement of image-to-video (I2V) generation models, their potential for misuse in creating malicious content has become a significant concern. For instance, a single image can be exploited to generate a fake video, which can be used to attract attention and gain benefits. This phenomenon is referred to as an I2V generation misuse. Existing image protection methods suffer from the absence of a unified benchmark, leading to an incomplete evaluation framework. Furthermore, these methods have not been systematically assessed in I2V generation scenarios and against preprocessing attacks, which complicates the evaluation of their effectiveness in real-world deployment scenarios.To address this challenge, we propose IP-Bench (Image Protection Bench), the first systematic benchmark designed to evaluate protection methods in I2V generation scenarios. This benchmark examines 6 representative protection methods and 5 state-of-the-art I2V models. Furthermore, our work systematically evaluates protection methods' robustness with two robustness attack strategies under practical scenarios and analyzes their cross-model & cross-modality transferability. Overall, IP-Bench establishes a systematic, reproducible, and extensible evaluation framework for image protection methods in I2V generation scenarios.
Chain-of-Authorization: Internalizing Authorization into Large Language Models via Reasoning Trajectories
Mar 24, 2026Large Language Models (LLMs) have become core cognitive components in modern artificial intelligence (AI) systems, combining internal knowledge with external context to perform complex tasks. However, LLMs typically treat all accessible data indiscriminately, lacking inherent awareness of knowledge ownership and access boundaries. This deficiency heightens risks of sensitive data leakage and adversarial manipulation, potentially enabling unauthorized system access and severe security crises. Existing protection strategies rely on rigid, uniform defense that prevent dynamic authorization. Structural isolation methods faces scalability bottlenecks, while prompt guidance methods struggle with fine-grained permissions distinctions. Here, we propose the Chain-of-Authorization (CoA) framework, a secure training and reasoning paradigm that internalizes authorization logic into LLMs' core capabilities. Unlike passive external defneses, CoA restructures the model's information flow: it embeds permission context at input and requires generating explicit authorization reasoning trajectory that includes resource review, identity resolution, and decision-making stages before final response. Through supervised fine-tuning on data covering various authorization status, CoA integrates policy execution with task responses, making authorization a causal prerequisite for substantive responses. Extensive evaluations show that CoA not only maintains comparable utility in authorized scenarios but also overcomes the cognitive confusion when permissions mismatches. It exhibits high rejection rates against various unauthorized and adversarial access. This mechanism leverages LLMs' reasoning capability to perform dynamic authorization, using natural language understanding as a proactive security mechanism for deploying reliable LLMs in modern AI systems.
Backdoor Attacks on Prompt-Driven Video Segmentation Foundation Models
Dec 26, 2025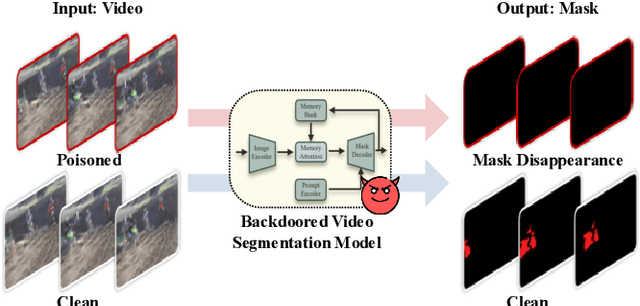
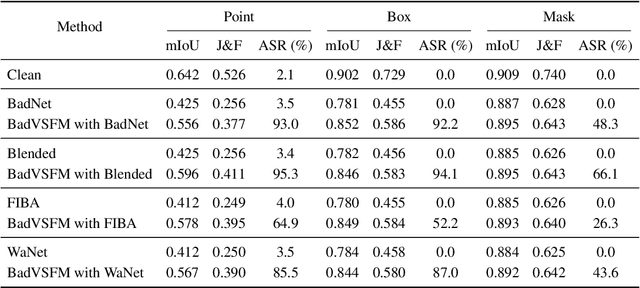
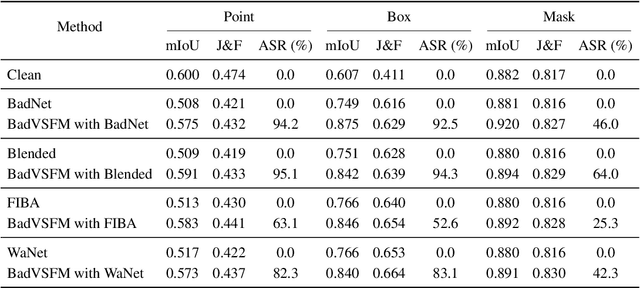
Prompt-driven Video Segmentation Foundation Models (VSFMs) such as SAM2 are increasingly deployed in applications like autonomous driving and digital pathology, raising concerns about backdoor threats. Surprisingly, we find that directly transferring classic backdoor attacks (e.g., BadNet) to VSFMs is almost ineffective, with ASR below 5\%. To understand this, we study encoder gradients and attention maps and observe that conventional training keeps gradients for clean and triggered samples largely aligned, while attention still focuses on the true object, preventing the encoder from learning a distinct trigger-related representation. To address this challenge, we propose BadVSFM, the first backdoor framework tailored to prompt-driven VSFMs. BadVSFM uses a two-stage strategy: (1) steer the image encoder so triggered frames map to a designated target embedding while clean frames remain aligned with a clean reference encoder; (2) train the mask decoder so that, across prompt types, triggered frame-prompt pairs produce a shared target mask, while clean outputs stay close to a reference decoder. Extensive experiments on two datasets and five VSFMs show that BadVSFM achieves strong, controllable backdoor effects under diverse triggers and prompts while preserving clean segmentation quality. Ablations over losses, stages, targets, trigger settings, and poisoning rates demonstrate robustness to reasonable hyperparameter changes and confirm the necessity of the two-stage design. Finally, gradient-conflict analysis and attention visualizations show that BadVSFM separates triggered and clean representations and shifts attention to trigger regions, while four representative defenses remain largely ineffective, revealing an underexplored vulnerability in current VSFMs.