 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attack on Vision Language Models with Stealthy Semantic Manipulation
Jun 08, 2025Vision Language Models (VLMs) have shown remarkable performance, but are also vulnerable to backdoor attacks whereby the adversary can manipulate the model's outputs through hidden triggers. Prior attacks primarily rely on single-modality triggers, leaving the crucial cross-modal fusion nature of VLMs largely unexplored. Unlike prior work, we identify a novel attack surface that leverages cross-modal semantic mismatches as implicit triggers. Based on this insight, we propose BadSem (Backdoor Attack with Semantic Manipulation), a data poisoning attack that injects stealthy backdoors by deliberately misaligning image-text pairs during training. To perform the attack, we construct SIMBad, a dataset tailored for semantic manipulation involving color and object attributes. Extensive experiments across four widely used VLMs show that BadSem achieves over 98% average ASR, generalizes well to out-of-distribution datasets, and can transfer across poisoning modalities. Our detailed analysis using attention visualization shows that backdoored models focus on semantically sensitive regions under mismatched conditions while maintaining normal behavior on clean inputs. To mitigate the attack, we try two defense strategies based on system prompt and supervised fine-tuning but find that both of them fail to mitigate the semantic backdoor. Our findings highlight the urgent need to address semantic vulnerabilities in VLMs for their safer deployment.
On the Generalization Ability of Machine-Generated Text Detectors
Dec 23, 2024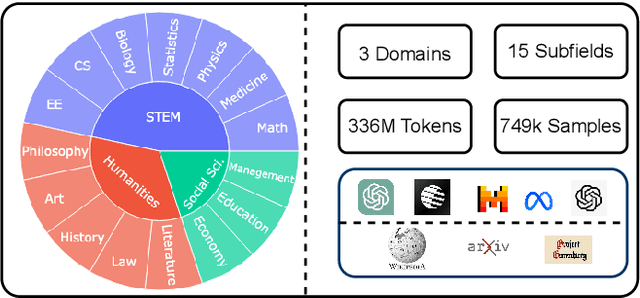
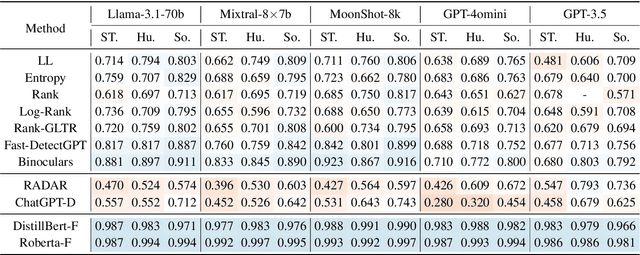

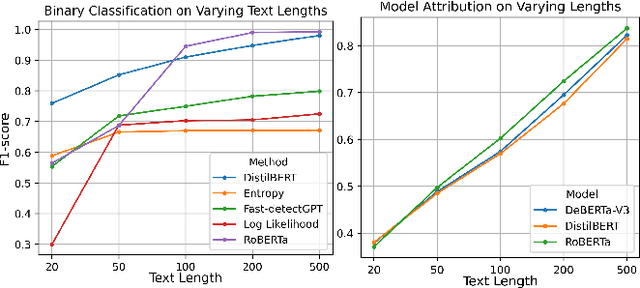
The rise of large language models (LLMs) has raised concerns about machine-generated text (MGT), including ethical and practical issues like plagiarism and misinformation. Building a robust and highly generalizable MGT detection system has become increasingly important. This work investigates the generalization capabilities of MGT detectors in three aspects: First, we construct MGTAcademic, a large-scale dataset focused on academic writing, featuring human-written texts (HWTs) and MGTs across STEM, Humanities, and Social Sciences, paired with an extensible code framework for efficient benchmarking. Second, we investigate the transferability of detectors across domains and LLMs, leveraging fine-grained datasets to reveal insights into domain transferring and implementing few-shot techniques to improve the performance by roughly 13.2%. Third, we introduce a novel attribution task where models must adapt to new classes over time without (or with very limited) access to prior training data and benchmark detectors. We implement several adapting techniques to improve the performance by roughly 10% and highlight the inherent complexity of the task. Our findings provide insights into the generalization ability of MGT detectors across diverse scenarios and lay the foundation for building robust, adaptive detection systems.
Scalable Image Retrieval by Sparse Product Quantization
Mar 15, 2016
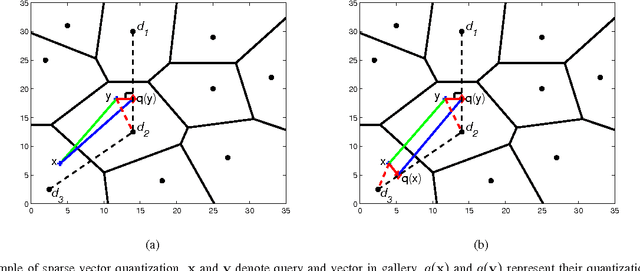
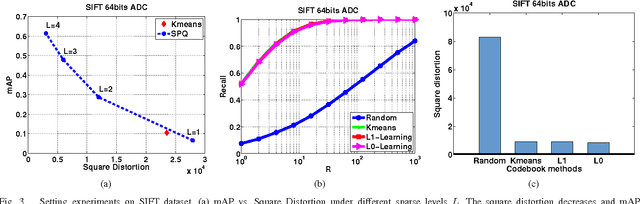
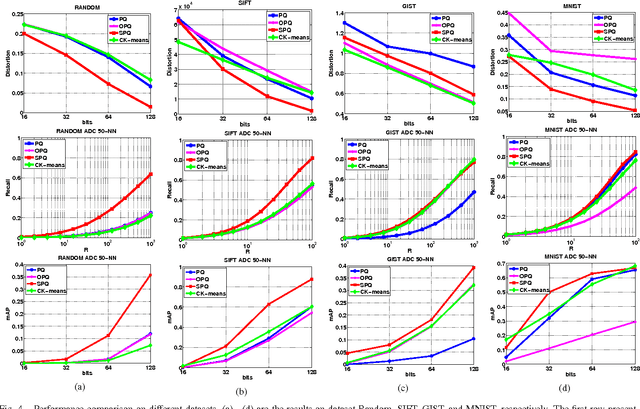
Fast Approximate Nearest Neighbor (ANN) search technique for high-dimensional feature indexing and retrieval is the crux of large-scale image retrieval. A recent promising technique is Product Quantization, which attempts to index high-dimensional image features by decomposing the feature space into a Cartesian product of low dimensional subspaces and quantizing each of them separately. Despite the promising results reported, their quantization approach follows the typical hard assignment of traditional quantization methods, which may result in large quantization errors and thus inferior search performance. Unlike the existing approaches, in this paper, we propose a novel approach called Sparse Product Quantization (SPQ) to encoding the high-dimensional feature vectors into sparse representation. We optimize the sparse representations of the feature vectors by minimizing their quantization errors, making the resulting representation is essentially close to the original data in practice. Experiments show that the proposed SPQ technique is not only able to compress data, but also an effective encoding technique. We obtain state-of-the-art results for ANN search on four public image datasets and the promising results of content-based image retrieval further validate the efficacy of our proposed method.