 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-VLA: Preemptive Runtime Verification for Reliable Vision-Language-Action and World-Model Rollouts
May 21, 2026While large vision-language-action (VLA) models and generative world models (WM) have advanced long-horizon embodied intelligence, their practical deployment remains challenged by uncertainty in learning-based action generation. Low-quality actions may cause physical failures during execution or lead to misleading world-model rollouts with redundant rendering costs. To address this issue, we propose Pre-VLA, a unified runtime verification architecture that performs preemptive action validity assessment before physical execution or world-model imagination. Pre-VLA leverages an efficient multimodal backbone with modality-aware pooling and a lightweight dual-branch head to predict both safety confidence and critic-derived advantage scores for candidate action chunks. To handle severe class imbalance and unstable boundary decisions, we train Pre-VLA with a multi-task objective combining Focal classification, advantage regression, and soft-threshold calibration. During deployment, a dual-mode preemptive resampling scheduler filters low-quality actions and triggers adaptive resampling under a limited computation budget. Experiments on the LIBERO benchmark show that Pre-VLA improves the average closed-loop success rate across four suites from 30.79\% to 37.62\% over RynnVLA-002, reduces task execution steps, achieves 183.9 ms average forward verification time per action chunk, and mitigates error accumulation in world-model rollouts.
D-VLA: A High-Concurrency Distributed Asynchronous Reinforcement Learning Framework for Vision-Language-Action Models
May 14, 2026The rapid evolution of Embodied AI has enabled Vision-Language-Action (VLA) models to excel in multimodal perception and task execution. However, applying Reinforcement Learning (RL) to these massive models in large-scale distributed environments faces severe systemic bottlenecks, primarily due to the resource conflict between high-fidelity physical simulation and the intensive VRAM/bandwidth demands of deep learning. This conflict often leaves overall throughput constrained by execution-phase inefficiencies. To address these challenges, we propose D-VLA, a high-concurrency, low-latency distributed RL framework for large-scale embodied foundation models. D-VLA introduces "Plane Decoupling," physically isolating high-frequency training data from low-frequency weight control to eliminate interference between simulation and optimization. We further design a four-thread asynchronous "Swimlane" pipeline, enabling full parallel overlap of sampling, inference, gradient computation, and parameter distribution. Additionally, a dual-pool VRAM management model and topology-aware replication resolve memory fragmentation and optimize communication efficiency. Experiments on benchmarks like LIBERO show that D-VLA significantly outperforms mainstream RL frameworks in throughput and sampling efficiency for billion-parameter VLA models. In trillion-parameter scalability tests, our framework maintains exceptional stability and linear speedup, providing a robust system for high-performance general-purpose embodied agents.
On the Generation and Mitigation of Harmful Geometry in Image-to-3D Models
May 10, 2026Recent advances in image-to-3D models have significantly improved the fidelity and accessibility of 3D content creation. Such a powerful reconstruction capability that enables creative design can also be misused by the adversary to generate harmful geometries, which can be further fabricated via 3D printers and pose real-world risks. However, such risks are largely underexplored: it remains unclear how well current image-to-3D models can produce these harmful geometries, and whether existing safeguards can reliably prevent such generation. To fill this gap, we conduct a systematic measurement study of harmful geometry generation and mitigation. We first describe this risk through three kinds of unsafe categories: direct-use physical hazards, risky templates or components, and deceptive replicas. Each category is instantiated with representative objects. We evaluate both open-source and commercial image-to-3D models under original, degraded, viewpoint-shifted, and semantically camouflaged inputs. We consider different evaluation metrics, including geometric validity, multi-view VLM-based semantic scoring, targeted human validation, and controlled physical fabrication. The results reveal a concerning reality that current image-to-3D models can effectively reconstruct the harmful geometries, while fewer than 0.3% of such geometries trigger commercial moderation flags. As a first step toward mitigation, we evaluate three representative safeguard families, including input moderation, model-level benign alignment, and output-level filtering. We find that existing safeguards have distinct weaknesses. We further develop a stacked defense that can reduce harmful retention to <1%, but still at 11% overall false-positive cost. Taken together, our findings demonstrate that the risk in current system and encourage better geometry-aware safeguards for moderation.
Stego Battlefield: Evaluating Image Steganography Attacks and Steganalysis Defenses
May 07, 2026Image steganography is widely used to protect user privacy and enable covert communication. However, it can also be abused by the adversary as a covert channel to bypass content moderation, disseminate harmful semantics, and even hide malicious instructions in images to elicit dangerous outputs from large models, posing a practical security risk that continues to evolve. To address the lack of a unified and systematic evaluation framework, we propose SADBench, a systematic benchmark that assesses the adversary's ability to inject harmful secrets via steganography and the defender's ability to detect such threats through steganalysis. Crucially, SADBench comprises $4$ core tasks, namely steganography attack capability evaluation, steganalysis defense capability evaluation, efficiency evaluation, and transferability evaluation. It evaluates both image-payload and text-payload steganography across diverse cover distributions, utilizing harmful visual semantics and toxic instructions to simulate malicious attacks. Across a broad set of attacks and detectors, SADBench reveals that (i) INN and autoencoder-based methods demonstrate superior stability compared to other architectures, (ii) in-domain detection is near-perfect and cheaper than generation, (iii) a critical asymmetry exists in transferability where attacks robustly generalize to new distributions while detectors fail to adapt, and (iv) real-world threats persist on social media, where payloads either survive minimal compression or effectively adapt to aggressive compression via simulated training. Overall, SADBench establishes a systematic, reproducible, and extensible framework to quantify risks, paving the way for measurable and security-driven advancements in steganography defense.
CHASM: Unveiling Covert Advertisements on Chinese Social Media
Apr 22, 2026Current benchmarks for evaluating large language models (LLMs) in social media moderation completely overlook a serious threat: covert advertisements, which disguise themselves as regular posts to deceive and mislead consumers into making purchases, leading to significant ethical and legal concerns. In this paper, we present the CHASM, a first-of-its-kind dataset designed to evaluate the capability of Multimodal Large Language Models (MLLMs) in detecting covert advertisements on social media. CHASM is a high-quality, anonymized, manually curated dataset consisting of 4,992 instances, based on real-world scenarios from the Chinese social media platform Rednote. The dataset was collected and annotated under strict privacy protection and quality control protocols. It includes many product experience sharing posts that closely resemble covert advertisements, making the dataset particularly challenging.The results show that under both zero-shot and in-context learning settings, none of the current MLLMs are sufficiently reliable for detecting covert advertisements.Our further experiments revealed that fine-tuning open-source MLLMs on our dataset yielded noticeable performance gains. However, significant challenges persist, such as detecting subtle cues in comments and differences in visual and textual structures.We provide in-depth error analysis and outline future research directions. We hope our study can serve as a call for the research community and platform moderators to develop more precise defenses against this emerging threat.
IP-Bench: Benchmark for Image Protection Methods in Image-to-Video Generation Scenarios
Mar 27, 2026With the rapid advancement of image-to-video (I2V) generation models, their potential for misuse in creating malicious content has become a significant concern. For instance, a single image can be exploited to generate a fake video, which can be used to attract attention and gain benefits. This phenomenon is referred to as an I2V generation misuse. Existing image protection methods suffer from the absence of a unified benchmark, leading to an incomplete evaluation framework. Furthermore, these methods have not been systematically assessed in I2V generation scenarios and against preprocessing attacks, which complicates the evaluation of their effectiveness in real-world deployment scenarios.To address this challenge, we propose IP-Bench (Image Protection Bench), the first systematic benchmark designed to evaluate protection methods in I2V generation scenarios. This benchmark examines 6 representative protection methods and 5 state-of-the-art I2V models. Furthermore, our work systematically evaluates protection methods' robustness with two robustness attack strategies under practical scenarios and analyzes their cross-model & cross-modality transferability. Overall, IP-Bench establishes a systematic, reproducible, and extensible evaluation framework for image protection methods in I2V generation scenarios.
Thousand-GPU Large-Scale Training and Optimization Recipe for AI-Native Cloud Embodied Intelligence Infrastructure
Mar 11, 2026Embodied intelligence is a key step towards Artificial General Intelligence (AGI), yet its development faces multiple challenges including data, frameworks, infrastructure, and evaluation systems. To address these issues, we have, for the first time in the industry, launched a cloud-based, thousand-GPU distributed training platform for embodied intelligence, built upon the widely adopted LeRobot framework, and have systematically overcome bottlenecks across the entire pipeline. At the data layer, we have restructured the data pipeline to optimize the flow of embodied training data. In terms of training, for the GR00T-N1.5 model, utilizing thousand-GPU clusters and data at the scale of hundreds of millions, the single-round training time has been reduced from 15 hours to just 22 minutes, achieving a 40-fold speedup. At the model layer, by combining variable-length FlashAttention and Data Packing, we have moved from sample redundancy to sequence integration, resulting in a 188% speed increase; π-0.5 attention optimization has accelerated training by 165%; and FP8 quantization has delivered a 140% speedup. On the infrastructure side, relying on high-performance storage, a 3.2T RDMA network, and a Ray-driven elastic AI data lake, we have achieved deep synergy among data, storage, communication, and computation. We have also built an end-to-end evaluation system, creating a closed loop from training to simulation to assessment. This framework has already been fully validated on thousand-GPU clusters, laying a crucial technical foundation for the development and application of next-generation autonomous intelligent robots, and is expected to accelerate the arrival of the era of human-machine integration.
SFCo-Nav: Efficient Zero-Shot Visual Language Navigation via Collaboration of Slow LLM and Fast Attributed Graph Alignment
Mar 02, 2026Recent advances in large vision-language models (VLMs) and large language models (LLMs) have enabled zero-shot approaches to visual language navigation (VLN), where an agent follows natural language instructions using only ego perception and reasoning. However, existing zero-shot methods typically construct a naive observation graph and perform per-step VLM-LLM inference on it, resulting in high latency and computation costs that limit real-time deployment. To address this, we present SFCo-Nav, an efficient zero-shot VLN framework inspired by the principle of slow-fast cognitive collaboration. SFCo-Nav integrates three key modules: 1) a slow LLM-based planner that produces a strategic chain of subgoals, each linked to an imagined object graph; 2) a fast reactive navigator for real-time object graph construction and subgoal execution; and 3) a lightweight asynchronous slow-fast bridge aligns advanced structured, attributed imagined and perceived graphs to estimate navigation confidence, triggering the slow LLM planner only when necessary. To the best of our knowledge, SFCo-Nav is the first slow-fast collaboration zero-shot VLN system supporting asynchronous LLM triggering according to the internal confidence. Evaluated on the public R2R and REVERIE benchmarks, SFCo-Nav matches or exceeds prior state-of-the-art zero-shot VLN success rates while cutting total token consumption per trajectory by over 50% and running more than 3.5 times faster. Finally, we demonstrate SFCo-Nav on a legged robot in a hotel suite, showcasing its efficiency and practicality in indoor environments.
Backdoor Attacks on Prompt-Driven Video Segmentation Foundation Models
Dec 26, 2025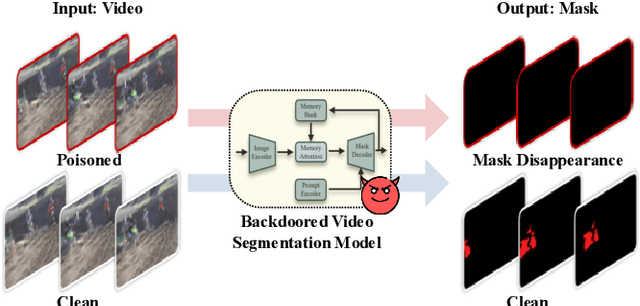
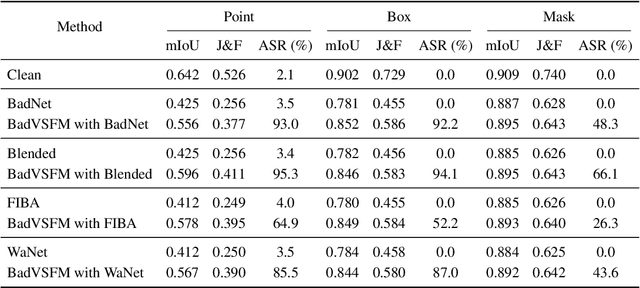
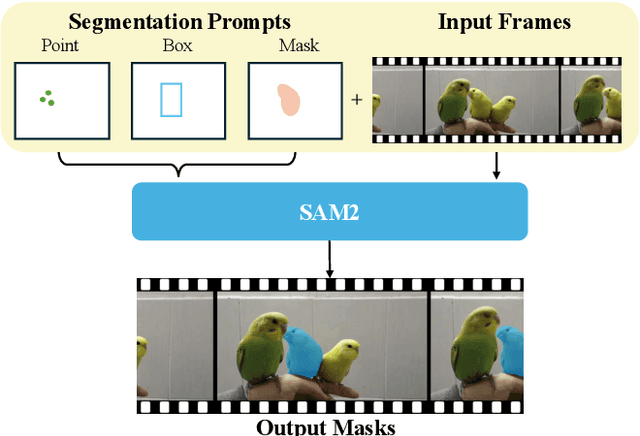
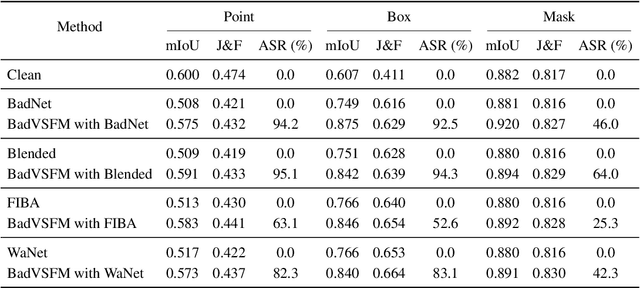
Prompt-driven Video Segmentation Foundation Models (VSFMs) such as SAM2 are increasingly deployed in applications like autonomous driving and digital pathology, raising concerns about backdoor threats. Surprisingly, we find that directly transferring classic backdoor attacks (e.g., BadNet) to VSFMs is almost ineffective, with ASR below 5\%. To understand this, we study encoder gradients and attention maps and observe that conventional training keeps gradients for clean and triggered samples largely aligned, while attention still focuses on the true object, preventing the encoder from learning a distinct trigger-related representation. To address this challenge, we propose BadVSFM, the first backdoor framework tailored to prompt-driven VSFMs. BadVSFM uses a two-stage strategy: (1) steer the image encoder so triggered frames map to a designated target embedding while clean frames remain aligned with a clean reference encoder; (2) train the mask decoder so that, across prompt types, triggered frame-prompt pairs produce a shared target mask, while clean outputs stay close to a reference decoder. Extensive experiments on two datasets and five VSFMs show that BadVSFM achieves strong, controllable backdoor effects under diverse triggers and prompts while preserving clean segmentation quality. Ablations over losses, stages, targets, trigger settings, and poisoning rates demonstrate robustness to reasonable hyperparameter changes and confirm the necessity of the two-stage design. Finally, gradient-conflict analysis and attention visualizations show that BadVSFM separates triggered and clean representations and shifts attention to trigger regions, while four representative defenses remain largely ineffective, revealing an underexplored vulnerability in current VSFMs.
6DAttack: Backdoor Attacks in the 6DoF Pose Estimation
Dec 22, 2025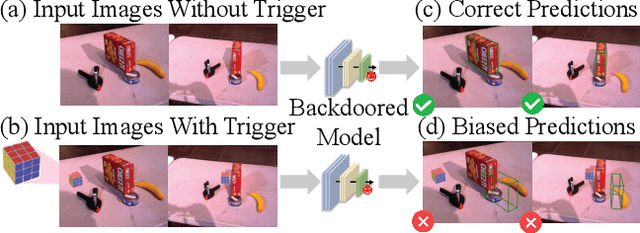
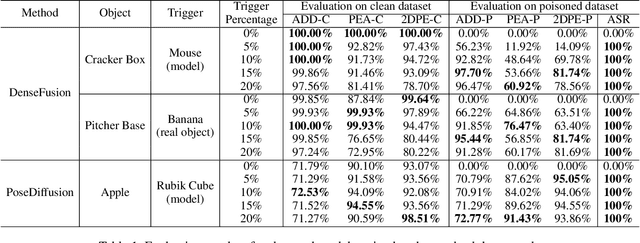
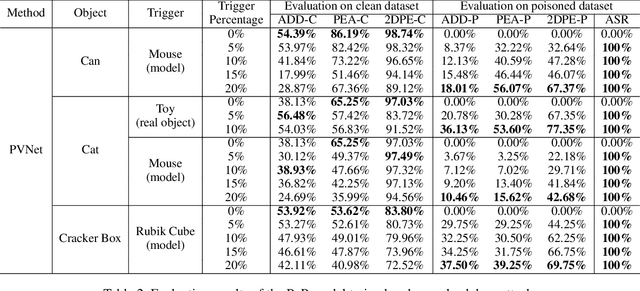
Deep learning advances have enabled accurate six-degree-of-freedom (6DoF) object pose estimation, widely used in robotics, AR/VR, and autonomous systems. However, backdoor attacks pose significant security risks. While most research focuses on 2D vision, 6DoF pose estimation remains largely unexplored. Unlike traditional backdoors that only change classes, 6DoF attacks must control continuous parameters like translation and rotation, rendering 2D methods inapplicable. We propose 6DAttack, a framework using 3D object triggers to induce controlled erroneous poses while maintaining normal behavior. Evaluations on PVNet, DenseFusion, and PoseDiffusion across LINEMOD, YCB-Video, and CO3D show high attack success rates (ASRs) without compromising clean performance. Backdoored models achieve up to 100% clean ADD accuracy and 100% ASR, with triggered samples reaching 97.70% ADD-P. Furthermore, a representative defense remains ineffective. Our findings reveal a serious, underexplored threat to 6DoF pose estimation.