 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutocorrelated Optimize-via-Estimate: Predict-then-Optimize versus Finite-sample Optimal
Feb 02, 2026Models that directly optimize for out-of-sample performance in the finite-sample regime have emerged as a promising alternative to traditional estimate-then-optimize approaches in data-driven optimization. In this work, we compare their performance in the context of autocorrelated uncertainties, specifically, under a Vector Autoregressive Moving Average VARMA(p,q) process. We propose an autocorrelated Optimize-via-Estimate (A-OVE) model that obtains an out-of-sample optimal solution as a function of sufficient statistics, and propose a recursive form for computing its sufficient statistics. We evaluate these models on a portfolio optimization problem with trading costs. A-OVE achieves low regret relative to a perfect information oracle, outperforming predict-then-optimize machine learning benchmarks. Notably, machine learning models with higher accuracy can have poorer decision quality, echoing the growing literature in data-driven optimization. Performance is retained under small mis-specification.
"I Can See Forever!": Evaluating Real-time VideoLLMs for Assisting Individuals with Visual Impairments
May 07, 2025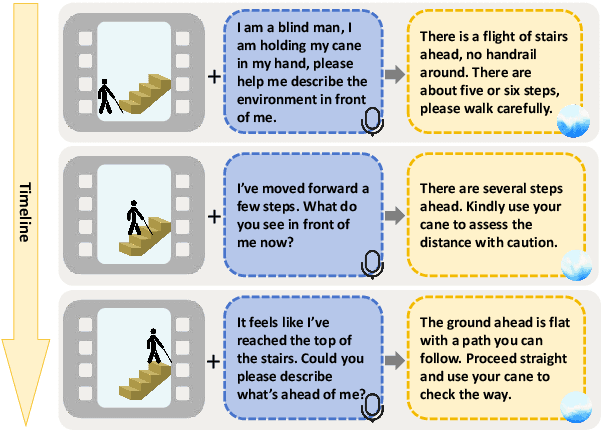
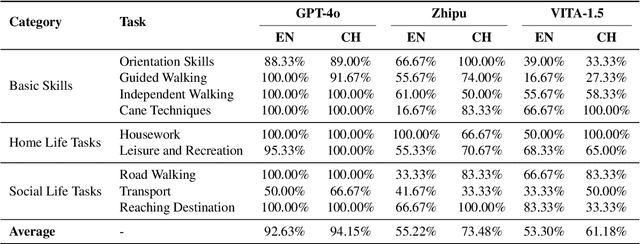
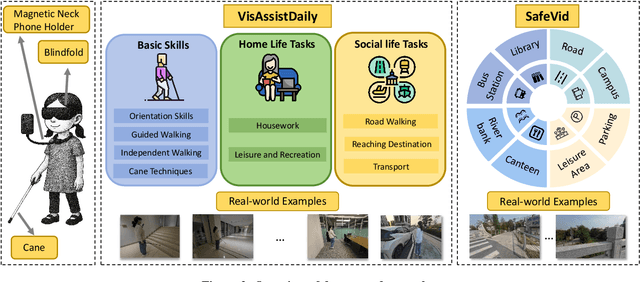
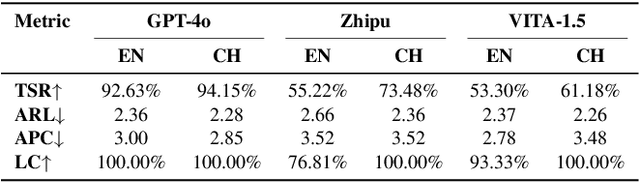
The visually impaired population, especially the severely visually impaired, is currently large in scale, and daily activities pose significant challenges for them. Although many studies use large language and vision-language models to assist the blind, most focus on static content and fail to meet real-time perception needs in dynamic and complex environments, such as daily activities. To provide them with more effective intelligent assistance, it is imperative to incorporate advanced visual understanding technologies. Although real-time vision and speech interaction VideoLLMs demonstrate strong real-time visual understanding, no prior work has systematically evaluated their effectiveness in assisting visually impaired individuals. In this work, we conduct the first such evaluation. First, we construct a benchmark dataset (VisAssistDaily), covering three categories of assistive tasks for visually impaired individuals: Basic Skills, Home Life Tasks, and Social Life Tasks. The results show that GPT-4o achieves the highest task success rate. Next, we conduct a user study to evaluate the models in both closed-world and open-world scenarios, further exploring the practical challenges of applying VideoLLMs in assistive contexts. One key issue we identify is the difficulty current models face in perceiving potential hazards in dynamic environments. To address this, we build an environment-awareness dataset named SafeVid and introduce a polling mechanism that enables the model to proactively detect environmental risks. We hope this work provides valuable insights and inspiration for future research in this field.
Optimize-via-Predict: Realizing out-of-sample optimality in data-driven optimization
Sep 20, 2023


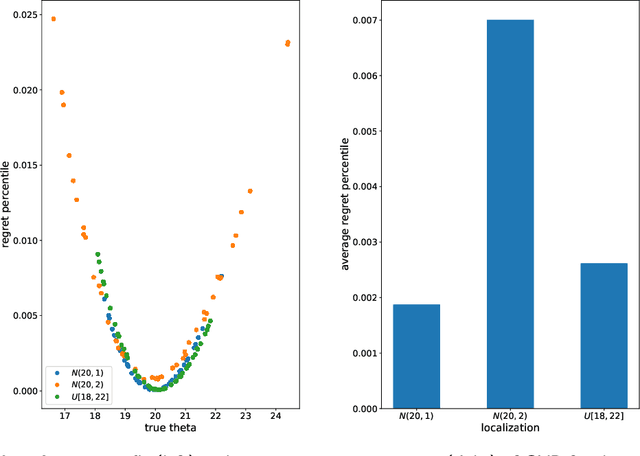
We examine a stochastic formulation for data-driven optimization wherein the decision-maker is not privy to the true distribution, but has knowledge that it lies in some hypothesis set and possesses a historical data set, from which information about it can be gleaned. We define a prescriptive solution as a decision rule mapping such a data set to decisions. As there does not exist prescriptive solutions that are generalizable over the entire hypothesis set, we define out-of-sample optimality as a local average over a neighbourhood of hypotheses, and averaged over the sampling distribution. We prove sufficient conditions for local out-of-sample optimality, which reduces to functions of the sufficient statistic of the hypothesis family. We present an optimization problem that would solve for such an out-of-sample optimal solution, and does so efficiently by a combination of sampling and bisection search algorithms. Finally, we illustrate our model on the newsvendor model, and find strong performance when compared against alternatives in the literature. There are potential implications of our research on end-to-end learning and Bayesian optimization.
Unveiling the Potential of Sentiment: Can Large Language Models Predict Chinese Stock Price Movements?
Jun 25, 2023The rapid advancement of Large Language Models (LLMs) has led to extensive discourse regarding their potential to boost the return of quantitative stock trading strategies. This discourse primarily revolves around harnessing the remarkable comprehension capabilities of LLMs to extract sentiment factors which facilitate informed and high-frequency investment portfolio adjustments. To ensure successful implementations of these LLMs into the analysis of Chinese financial texts and the subsequent trading strategy development within the Chinese stock market, we provide a rigorous and encompassing benchmark as well as a standardized back-testing framework aiming at objectively assessing the efficacy of various types of LLMs in the specialized domain of sentiment factor extraction from Chinese news text data. To illustrate how our benchmark works, we reference three distinctive models: 1) the generative LLM (ChatGPT), 2) the Chinese language-specific pre-trained LLM (Erlangshen-RoBERTa), and 3) the financial domain-specific fine-tuned LLM classifier(Chinese FinBERT). We apply them directly to the task of sentiment factor extraction from large volumes of Chinese news summary texts. We then proceed to building quantitative trading strategies and running back-tests under realistic trading scenarios based on the derived sentiment factors and evaluate their performances with our benchmark. By constructing such a comparative analysis, we invoke the question of what constitutes the most important element for improving a LLM's performance on extracting sentiment factors. And by ensuring that the LLMs are evaluated on the same benchmark, following the same standardized experimental procedures that are designed with sufficient expertise in quantitative trading, we make the first stride toward answering such a question.