 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Self-Guided Process Reward Optimization with Redefined Step-wise Advantage for Process Reinforcement Learning
Jul 03, 2025Process Reinforcement Learning~(PRL) has demonstrated considerable potential in enhancing the reasoning capabilities of Large Language Models~(LLMs). However, introducing additional process reward models incurs substantial computational overhead, and there is no unified theoretical framework for process-level advantage estimation. To bridge this gap, we propose \textbf{S}elf-Guided \textbf{P}rocess \textbf{R}eward \textbf{O}ptimization~(\textbf{SPRO}), a novel framework that enables process-aware RL through two key innovations: (1) we first theoretically demonstrate that process rewards can be derived intrinsically from the policy model itself, and (2) we introduce well-defined cumulative process rewards and \textbf{M}asked \textbf{S}tep \textbf{A}dvantage (\textbf{MSA}), which facilitates rigorous step-wise action advantage estimation within shared-prompt sampling groups. Our experimental results demonstrate that SPRO outperforms vaniila GRPO with 3.4x higher training efficiency and a 17.5\% test accuracy improvement. Furthermore, SPRO maintains a stable and elevated policy entropy throughout training while reducing the average response length by approximately $1/3$, evidencing sufficient exploration and prevention of reward hacking. Notably, SPRO incurs no additional computational overhead compared to outcome-supervised RL methods such as GRPO, which benefit industrial implementation.
QuantBench: Benchmarking AI Methods for Quantitative Investment
Apr 24, 2025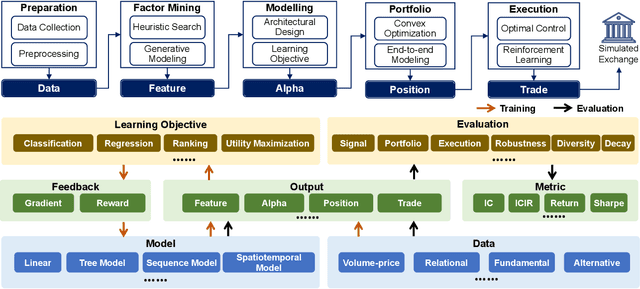



The field of artificial intelligence (AI) in quantitative investment has seen significant advancements, yet it lacks a standardized benchmark aligned with industry practices. This gap hinders research progress and limits the practical application of academic innovations. We present QuantBench, an industrial-grade benchmark platform designed to address this critical need. QuantBench offers three key strengths: (1) standardization that aligns with quantitative investment industry practices, (2) flexibility to integrate various AI algorithms, and (3) full-pipeline coverage of the entire quantitative investment process. Our empirical studies using QuantBench reveal some critical research directions, including the need for continual learning to address distribution shifts, improved methods for modeling relational financial data, and more robust approaches to mitigate overfitting in low signal-to-noise environments. By providing a common ground for evaluation and fostering collaboration between researchers and practitioners, QuantBench aims to accelerate progress in AI for quantitative investment, similar to the impact of benchmark platforms in computer vision and natural language processing.
PPTAgent: Generating and Evaluating Presentations Beyond Text-to-Slides
Jan 07, 2025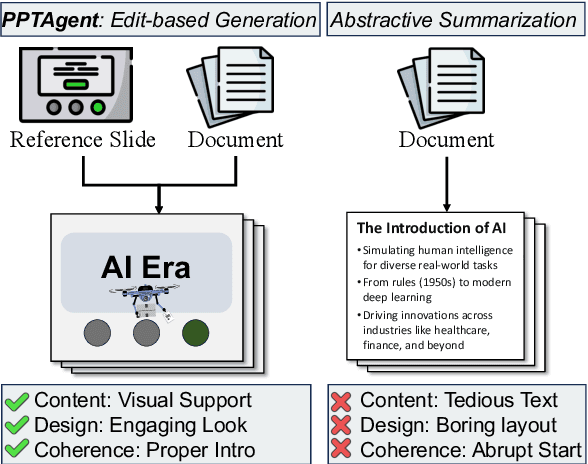

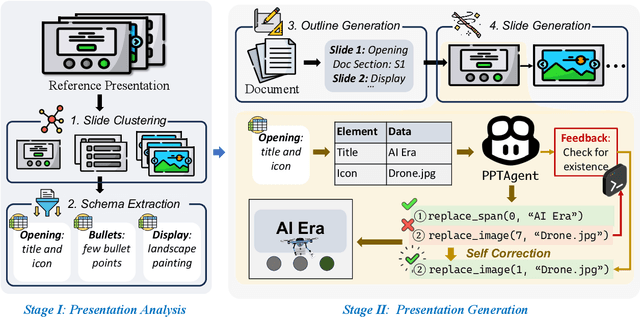
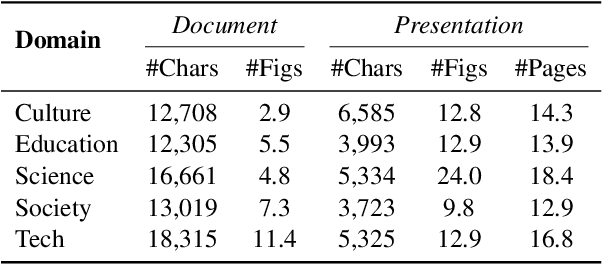
Automatically generating presentations from documents is a challenging task that requires balancing content quality, visual design, and structural coherence. Existing methods primarily focus on improving and evaluating the content quality in isolation, often overlooking visual design and structural coherence, which limits their practical applicability. To address these limitations, we propose PPTAgent, which comprehensively improves presentation generation through a two-stage, edit-based approach inspired by human workflows. PPTAgent first analyzes reference presentations to understand their structural patterns and content schemas, then drafts outlines and generates slides through code actions to ensure consistency and alignment. To comprehensively evaluate the quality of generated presentations, we further introduce PPTEval, an evaluation framework that assesses presentations across three dimensions: Content, Design, and Coherence. Experiments show that PPTAgent significantly outperforms traditional automatic presentation generation methods across all three dimensions. The code and data are available at https://github.com/icip-cas/PPTAgent.
Efficient Deep Learning Infrastructures for Embedded Computing Systems: A Comprehensive Survey and Future Envision
Nov 03, 2024Deep neural networks (DNNs) have recently achieved impressive success across a wide range of real-world vision and language processing tasks, spanning from image classification to many other downstream vision tasks, such as object detection, tracking, and segmentation. However, previous well-established DNNs, despite being able to maintain superior accuracy, have also been evolving to be deeper and wider and thus inevitably necessitate prohibitive computational resources for both training and inference. This trend further enlarges the computational gap between computation-intensive DNNs and resource-constrained embedded computing systems, making it challenging to deploy powerful DNNs upon real-world embedded computing systems towards ubiquitous embedded intelligence. To alleviate the above computational gap and enable ubiquitous embedded intelligence, we, in this survey, focus on discussing recent efficient deep learning infrastructures for embedded computing systems, spanning from training to inference, from manual to automated, from convolutional neural networks to transformers, from transformers to vision transformers, from vision models to large language models, from software to hardware, and from algorithms to applications. Specifically, we discuss recent efficient deep learning infrastructures for embedded computing systems from the lens of (1) efficient manual network design for embedded computing systems, (2) efficient automated network design for embedded computing systems, (3) efficient network compression for embedded computing systems, (4) efficient on-device learning for embedded computing systems, (5) efficient large language models for embedded computing systems, (6) efficient deep learning software and hardware for embedded computing systems, and (7) efficient intelligent applications for embedded computing systems.
Unveiling the Potential of Sentiment: Can Large Language Models Predict Chinese Stock Price Movements?
Jun 25, 2023The rapid advancement of Large Language Models (LLMs) has led to extensive discourse regarding their potential to boost the return of quantitative stock trading strategies. This discourse primarily revolves around harnessing the remarkable comprehension capabilities of LLMs to extract sentiment factors which facilitate informed and high-frequency investment portfolio adjustments. To ensure successful implementations of these LLMs into the analysis of Chinese financial texts and the subsequent trading strategy development within the Chinese stock market, we provide a rigorous and encompassing benchmark as well as a standardized back-testing framework aiming at objectively assessing the efficacy of various types of LLMs in the specialized domain of sentiment factor extraction from Chinese news text data. To illustrate how our benchmark works, we reference three distinctive models: 1) the generative LLM (ChatGPT), 2) the Chinese language-specific pre-trained LLM (Erlangshen-RoBERTa), and 3) the financial domain-specific fine-tuned LLM classifier(Chinese FinBERT). We apply them directly to the task of sentiment factor extraction from large volumes of Chinese news summary texts. We then proceed to building quantitative trading strategies and running back-tests under realistic trading scenarios based on the derived sentiment factors and evaluate their performances with our benchmark. By constructing such a comparative analysis, we invoke the question of what constitutes the most important element for improving a LLM's performance on extracting sentiment factors. And by ensuring that the LLMs are evaluated on the same benchmark, following the same standardized experimental procedures that are designed with sufficient expertise in quantitative trading, we make the first stride toward answering such a question.
PosterLayout: A New Benchmark and Approach for Content-aware Visual-Textual Presentation Layout
Mar 28, 2023



Content-aware visual-textual presentation layout aims at arranging spatial space on the given canvas for pre-defined elements, including text, logo, and underlay, which is a key to automatic template-free creative graphic design. In practical applications, e.g., poster designs, the canvas is originally non-empty, and both inter-element relationships as well as inter-layer relationships should be concerned when generating a proper layout. A few recent works deal with them simultaneously, but they still suffer from poor graphic performance, such as a lack of layout variety or spatial non-alignment. Since content-aware visual-textual presentation layout is a novel task, we first construct a new dataset named PosterLayout, which consists of 9,974 poster-layout pairs and 905 images, i.e., non-empty canvases. It is more challenging and useful for greater layout variety, domain diversity, and content diversity. Then, we propose design sequence formation (DSF) that reorganizes elements in layouts to imitate the design processes of human designers, and a novel CNN-LSTM-based conditional generative adversarial network (GAN) is presented to generate proper layouts. Specifically, the discriminator is design-sequence-aware and will supervise the "design" process of the generator. Experimental results verify the usefulness of the new benchmark and the effectiveness of the proposed approach, which achieves the best performance by generating suitable layouts for diverse canvases.
You Only Search Once: On Lightweight Differentiable Architecture Search for Resource-Constrained Embedded Platforms
Aug 30, 2022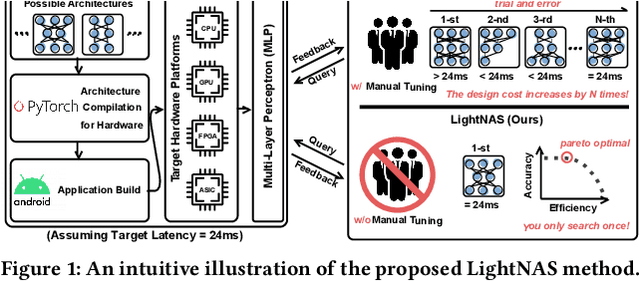

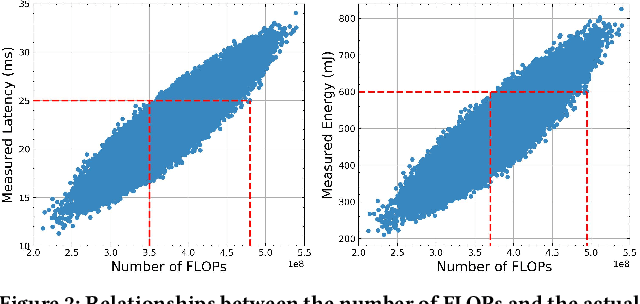
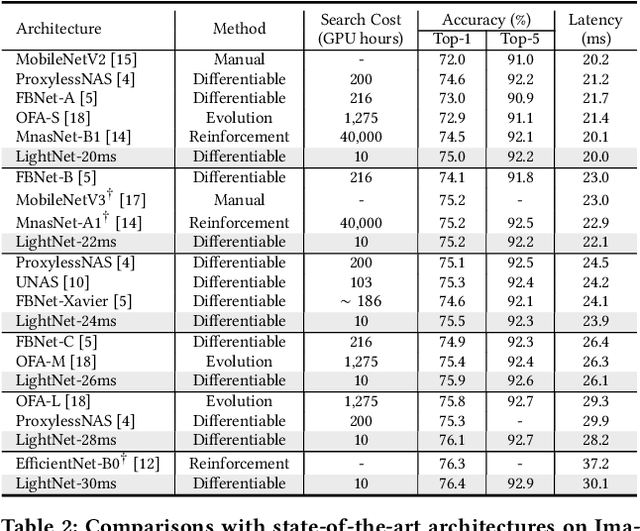
Benefiting from the search efficiency, differentiable neural architecture search (NAS) has evolved as the most dominant alternative to automatically design competitive deep neural networks (DNNs). We note that DNNs must be executed under strictly hard performance constraints in real-world scenarios, for example, the runtime latency on autonomous vehicles. However, to obtain the architecture that meets the given performance constraint, previous hardware-aware differentiable NAS methods have to repeat a plethora of search runs to manually tune the hyper-parameters by trial and error, and thus the total design cost increases proportionally. To resolve this, we introduce a lightweight hardware-aware differentiable NAS framework dubbed LightNAS, striving to find the required architecture that satisfies various performance constraints through a one-time search (i.e., \underline{\textit{you only search once}}). Extensive experiments are conducted to show the superiority of LightNAS over previous state-of-the-art methods.
SymNMF-Net for The Symmetric NMF Problem
May 26, 2022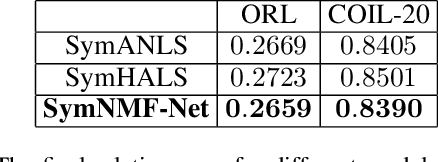
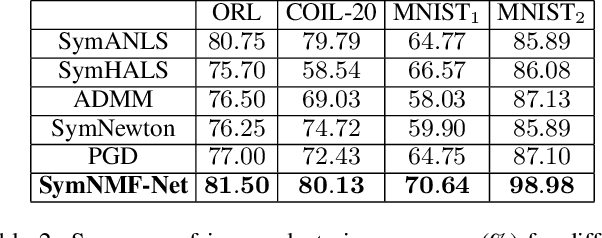
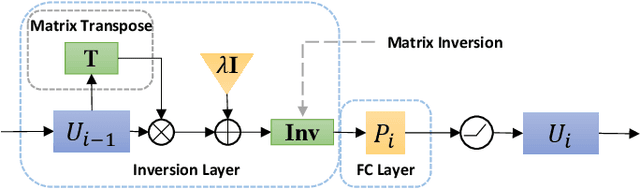
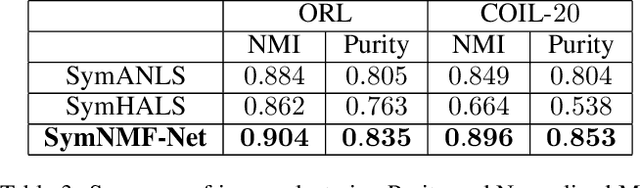
Recently, many works have demonstrated that Symmetric Non-negative Matrix Factorization~(SymNMF) enjoys a great superiority for various clustering tasks. Although the state-of-the-art algorithms for SymNMF perform well on synthetic data, they cannot consistently obtain satisfactory results with desirable properties and may fail on real-world tasks like clustering. Considering the flexibility and strong representation ability of the neural network, in this paper, we propose a neural network called SymNMF-Net for the Symmetric NMF problem to overcome the shortcomings of traditional optimization algorithms. Each block of SymNMF-Net is a differentiable architecture with an inversion layer, a linear layer and ReLU, which are inspired by a traditional update scheme for SymNMF. We show that the inference of each block corresponds to a single iteration of the optimization. Furthermore, we analyze the constraints of the inversion layer to ensure the output stability of the network to a certain extent. Empirical results on real-world datasets demonstrate the superiority of our SymNMF-Net and confirm the sufficiency of our theoretical analysis.
Bringing AI To Edge: From Deep Learning's Perspective
Nov 25, 2020
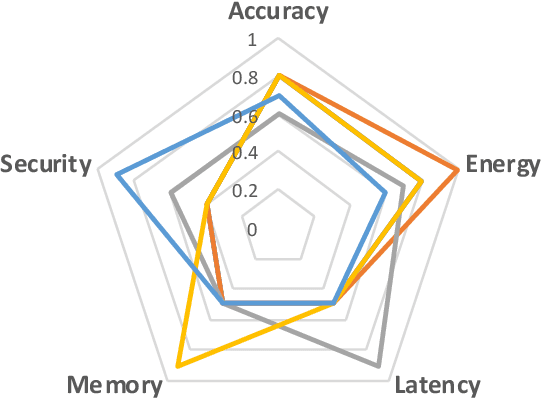
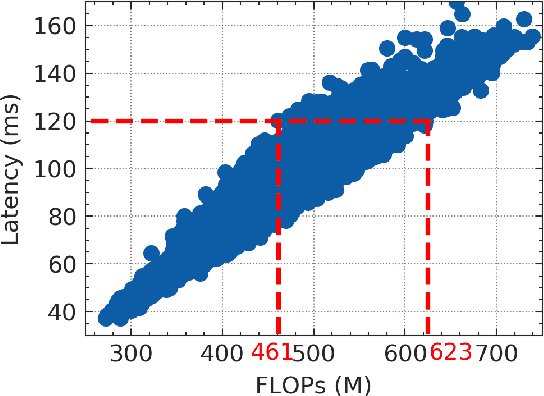
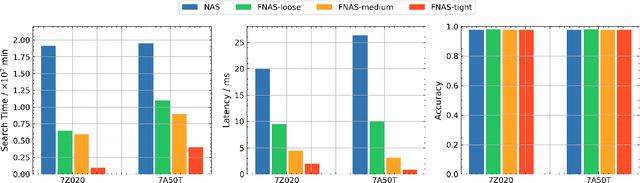
Edge computing and artificial intelligence (AI), especially deep learning for nowadays, are gradually intersecting to build a novel system, called edge intelligence. However, the development of edge intelligence systems encounters some challenges, and one of these challenges is the \textit{computational gap} between computation-intensive deep learning algorithms and less-capable edge systems. Due to the computational gap, many edge intelligence systems cannot meet the expected performance requirements. To bridge the gap, a plethora of deep learning techniques and optimization methods are proposed in the past years: light-weight deep learning models, network compression, and efficient neural architecture search. Although some reviews or surveys have partially covered this large body of literature, we lack a systematic and comprehensive review to discuss all aspects of these deep learning techniques which are critical for edge intelligence implementation. As various and diverse methods which are applicable to edge systems are proposed intensively, a holistic review would enable edge computing engineers and community to know the state-of-the-art deep learning techniques which are instrumental for edge intelligence and to facilitate the development of edge intelligence systems. This paper surveys the representative and latest deep learning techniques that are useful for edge intelligence systems, including hand-crafted models, model compression, hardware-aware neural architecture search and adaptive deep learning models. Finally, based on observations and simple experiments we conducted, we discuss some future directions.