 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheating Stereo Matching in Full-scale: Physical Adversarial Attack against Binocular Depth Estimation in Autonomous Driving
Nov 19, 2025Though deep neural models adopted to realize the perception of autonomous driving have proven vulnerable to adversarial examples, known attacks often leverage 2D patches and target mostly monocular perception. Therefore, the effectiveness of Physical Adversarial Examples (PAEs) on stereo-based binocular depth estimation remains largely unexplored. To this end, we propose the first texture-enabled physical adversarial attack against stereo matching models in the context of autonomous driving. Our method employs a 3D PAE with global camouflage texture rather than a local 2D patch-based one, ensuring both visual consistency and attack effectiveness across different viewpoints of stereo cameras. To cope with the disparity effect of these cameras, we also propose a new 3D stereo matching rendering module that allows the PAE to be aligned with real-world positions and headings in binocular vision. We further propose a novel merging attack that seamlessly blends the target into the environment through fine-grained PAE optimization. It has significantly enhanced stealth and lethality upon existing hiding attacks that fail to get seamlessly merged into the background. Extensive evaluations show that our PAEs can successfully fool the stereo models into producing erroneous depth information.
More Than Meets the Eye? Uncovering the Reasoning-Planning Disconnect in Training Vision-Language Driving Models
Oct 06, 2025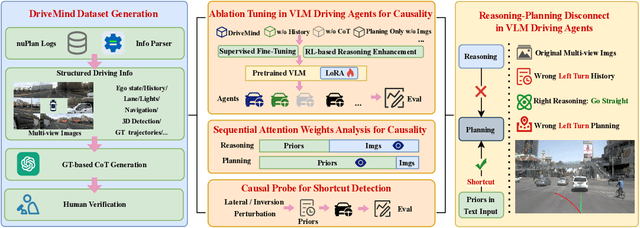
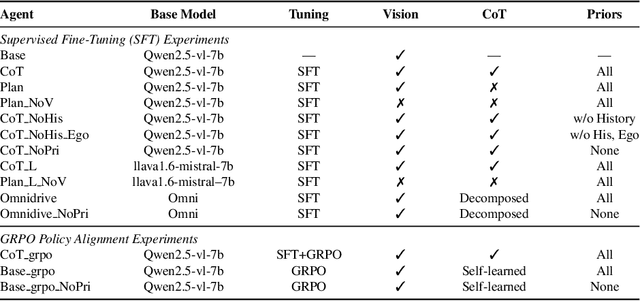
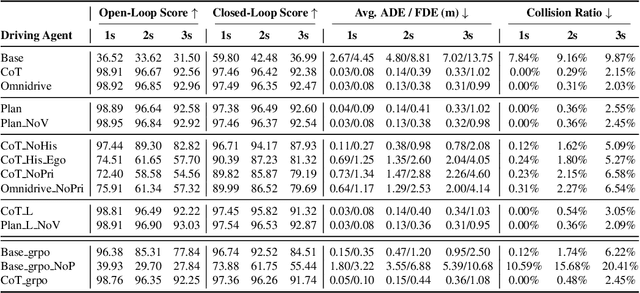

Vision-Language Model (VLM) driving agents promise explainable end-to-end autonomy by first producing natural-language reasoning and then predicting trajectory planning. However, whether planning is causally driven by this reasoning remains a critical but unverified assumption. To investigate this, we build DriveMind, a large-scale driving Visual Question Answering (VQA) corpus with plan-aligned Chain-of-Thought (CoT), automatically generated from nuPlan. Our data generation process converts sensors and annotations into structured inputs and, crucially, separates priors from to-be-reasoned signals, enabling clean information ablations. Using DriveMind, we train representative VLM agents with Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO) and evaluate them with nuPlan's metrics. Our results, unfortunately, indicate a consistent causal disconnect in reasoning-planning: removing ego/navigation priors causes large drops in planning scores, whereas removing CoT produces only minor changes. Attention analysis further shows that planning primarily focuses on priors rather than the CoT. Based on this evidence, we propose the Reasoning-Planning Decoupling Hypothesis, positing that the training-yielded reasoning is an ancillary byproduct rather than a causal mediator. To enable efficient diagnosis, we also introduce a novel, training-free probe that measures an agent's reliance on priors by evaluating its planning robustness against minor input perturbations. In summary, we provide the community with a new dataset and a diagnostic tool to evaluate the causal fidelity of future models.
Efficient Deep Learning Infrastructures for Embedded Computing Systems: A Comprehensive Survey and Future Envision
Nov 03, 2024Deep neural networks (DNNs) have recently achieved impressive success across a wide range of real-world vision and language processing tasks, spanning from image classification to many other downstream vision tasks, such as object detection, tracking, and segmentation. However, previous well-established DNNs, despite being able to maintain superior accuracy, have also been evolving to be deeper and wider and thus inevitably necessitate prohibitive computational resources for both training and inference. This trend further enlarges the computational gap between computation-intensive DNNs and resource-constrained embedded computing systems, making it challenging to deploy powerful DNNs upon real-world embedded computing systems towards ubiquitous embedded intelligence. To alleviate the above computational gap and enable ubiquitous embedded intelligence, we, in this survey, focus on discussing recent efficient deep learning infrastructures for embedded computing systems, spanning from training to inference, from manual to automated, from convolutional neural networks to transformers, from transformers to vision transformers, from vision models to large language models, from software to hardware, and from algorithms to applications. Specifically, we discuss recent efficient deep learning infrastructures for embedded computing systems from the lens of (1) efficient manual network design for embedded computing systems, (2) efficient automated network design for embedded computing systems, (3) efficient network compression for embedded computing systems, (4) efficient on-device learning for embedded computing systems, (5) efficient large language models for embedded computing systems, (6) efficient deep learning software and hardware for embedded computing systems, and (7) efficient intelligent applications for embedded computing systems.
You Only Search Once: On Lightweight Differentiable Architecture Search for Resource-Constrained Embedded Platforms
Aug 30, 2022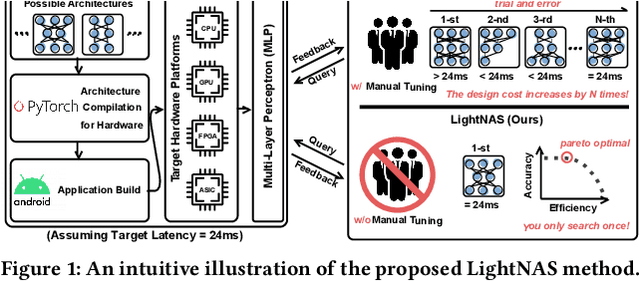

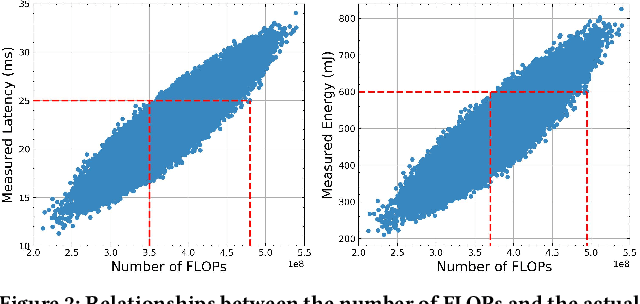
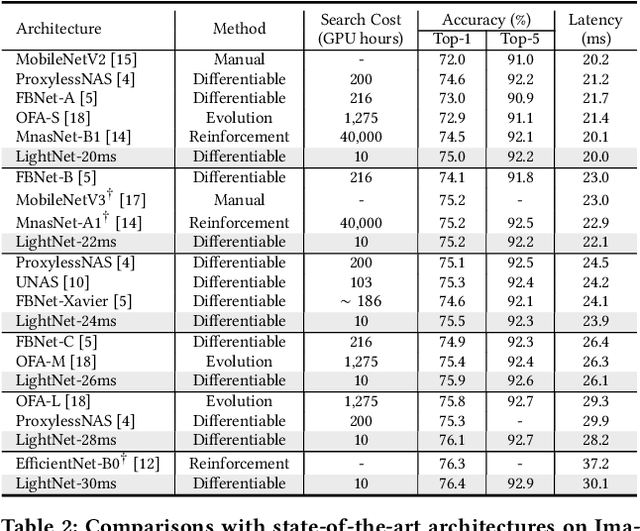
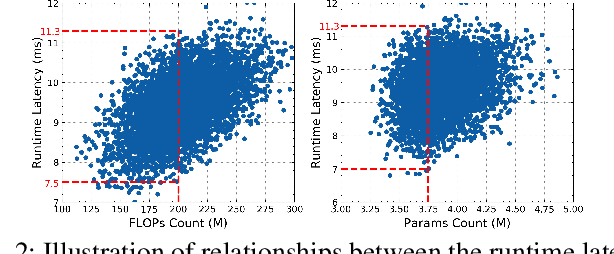
Benefiting from the search efficiency, differentiable neural architecture search (NAS) has evolved as the most dominant alternative to automatically design competitive deep neural networks (DNNs). We note that DNNs must be executed under strictly hard performance constraints in real-world scenarios, for example, the runtime latency on autonomous vehicles. However, to obtain the architecture that meets the given performance constraint, previous hardware-aware differentiable NAS methods have to repeat a plethora of search runs to manually tune the hyper-parameters by trial and error, and thus the total design cost increases proportionally. To resolve this, we introduce a lightweight hardware-aware differentiable NAS framework dubbed LightNAS, striving to find the required architecture that satisfies various performance constraints through a one-time search (i.e., \underline{\textit{you only search once}}). Extensive experiments are conducted to show the superiority of LightNAS over previous state-of-the-art methods.
HSCoNAS: Hardware-Software Co-Design of Efficient DNNs via Neural Architecture Search
Mar 11, 2021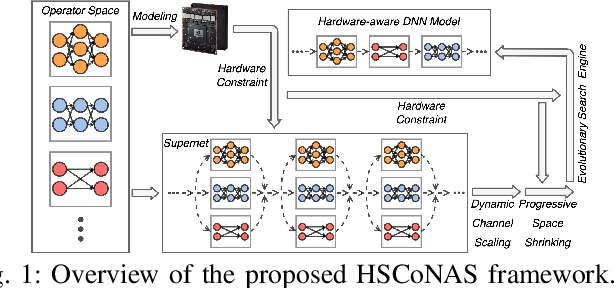
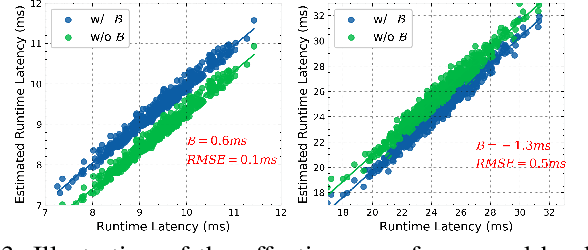
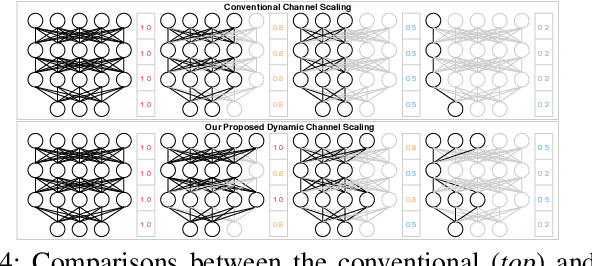
In this paper, we present a novel multi-objective hardware-aware neural architecture search (NAS) framework, namely HSCoNAS, to automate the design of deep neural networks (DNNs) with high accuracy but low latency upon target hardware. To accomplish this goal, we first propose an effective hardware performance modeling method to approximate the runtime latency of DNNs on target hardware, which will be integrated into HSCoNAS to avoid the tedious on-device measurements. Besides, we propose two novel techniques, i.e., dynamic channel scaling to maximize the accuracy under the specified latency and progressive space shrinking to refine the search space towards target hardware as well as alleviate the search overheads. These two techniques jointly work to allow HSCoNAS to perform fine-grained and efficient explorations. Finally, an evolutionary algorithm (EA) is incorporated to conduct the architecture search. Extensive experiments on ImageNet are conducted upon diverse target hardware, i.e., GPU, CPU, and edge device to demonstrate the superiority of HSCoNAS over recent state-of-the-art approaches.