 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatter Tokens are More Valuable for Speculative Draft Model Training
Jan 26, 2026Speculative Decoding (SD) is a key technique for accelerating Large Language Model (LLM) inference, but it typically requires training a draft model on a large dataset. We approach this problem from a data-centric perspective, finding that not all training samples contribute equally to the SD acceptance rate. Specifically, our theoretical analysis and empirical validation reveals that tokens inducing flatter predictive distributions from the target model are more valuable than those yielding sharply peaked distributions. Based on this insight, we propose flatness, a new metric to quantify this property, and develop the Sample-level-flatness-based Dataset Distillation (SFDD) approach, which filters the training data to retain only the most valuable samples. Experiments on the EAGLE framework demonstrate that SFDD can achieve over 2$\times$ training speedup using only 50% of the data, while keeping the final model's inference speedup within 4% of the full-dataset baseline. This work introduces an effective, data-centric approach that substantially improves the training efficiency for Speculative Decoding. Our code is available at https://anonymous.4open.science/r/Flatness.
Exploring Deep-to-Shallow Transformable Neural Networks for Intelligent Embedded Systems
Dec 17, 2025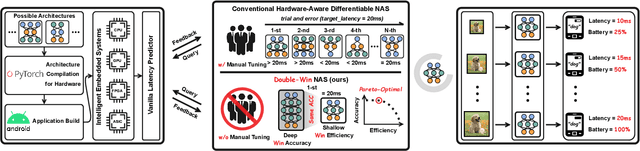
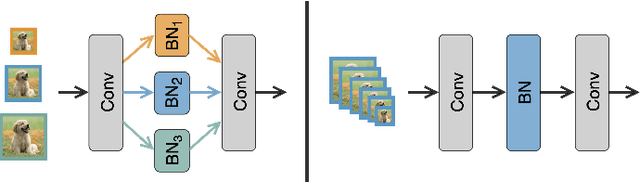
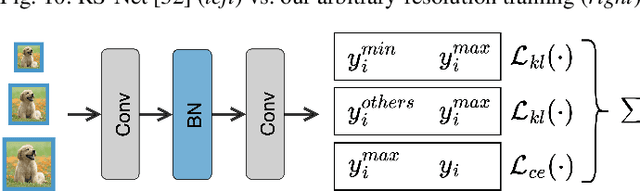
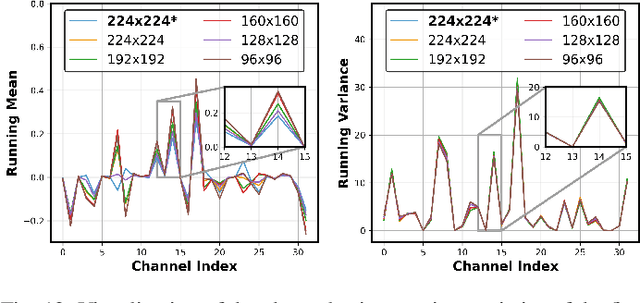
Thanks to the evolving network depth, convolutional neural networks (CNNs) have achieved remarkable success across various embedded scenarios, paving the way for ubiquitous embedded intelligence. Despite its promise, the evolving network depth comes at the cost of degraded hardware efficiency. In contrast to deep networks, shallow networks can deliver superior hardware efficiency but often suffer from inferior accuracy. To address this dilemma, we propose Double-Win NAS, a novel deep-to-shallow transformable neural architecture search (NAS) paradigm tailored for resource-constrained intelligent embedded systems. Specifically, Double-Win NAS strives to automatically explore deep networks to first win strong accuracy, which are then equivalently transformed into their shallow counterparts to further win strong hardware efficiency. In addition to search, we also propose two enhanced training techniques, including hybrid transformable training towards better training accuracy and arbitrary-resolution elastic training towards enabling natural network elasticity across arbitrary input resolutions. Extensive experimental results on two popular intelligent embedded systems (i.e., NVIDIA Jetson AGX Xavier and NVIDIA Jetson Nano) and two representative large-scale datasets (i.e., ImageNet and ImageNet-100) clearly demonstrate the superiority of Double-Win NAS over previous state-of-the-art NAS approaches.
Efficient Deep Learning Infrastructures for Embedded Computing Systems: A Comprehensive Survey and Future Envision
Nov 03, 2024Deep neural networks (DNNs) have recently achieved impressive success across a wide range of real-world vision and language processing tasks, spanning from image classification to many other downstream vision tasks, such as object detection, tracking, and segmentation. However, previous well-established DNNs, despite being able to maintain superior accuracy, have also been evolving to be deeper and wider and thus inevitably necessitate prohibitive computational resources for both training and inference. This trend further enlarges the computational gap between computation-intensive DNNs and resource-constrained embedded computing systems, making it challenging to deploy powerful DNNs upon real-world embedded computing systems towards ubiquitous embedded intelligence. To alleviate the above computational gap and enable ubiquitous embedded intelligence, we, in this survey, focus on discussing recent efficient deep learning infrastructures for embedded computing systems, spanning from training to inference, from manual to automated, from convolutional neural networks to transformers, from transformers to vision transformers, from vision models to large language models, from software to hardware, and from algorithms to applications. Specifically, we discuss recent efficient deep learning infrastructures for embedded computing systems from the lens of (1) efficient manual network design for embedded computing systems, (2) efficient automated network design for embedded computing systems, (3) efficient network compression for embedded computing systems, (4) efficient on-device learning for embedded computing systems, (5) efficient large language models for embedded computing systems, (6) efficient deep learning software and hardware for embedded computing systems, and (7) efficient intelligent applications for embedded computing systems.
You Only Search Once: On Lightweight Differentiable Architecture Search for Resource-Constrained Embedded Platforms
Aug 30, 2022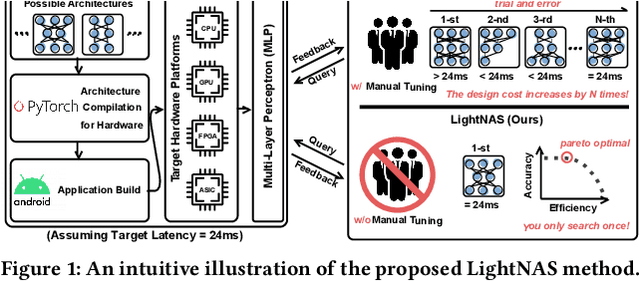

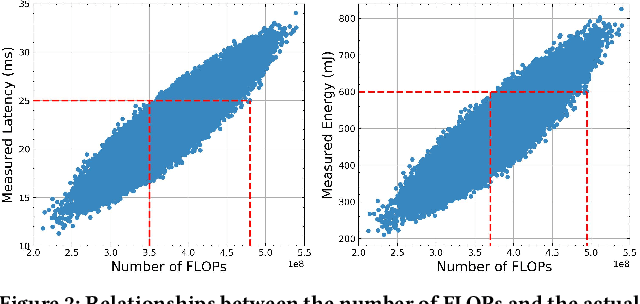
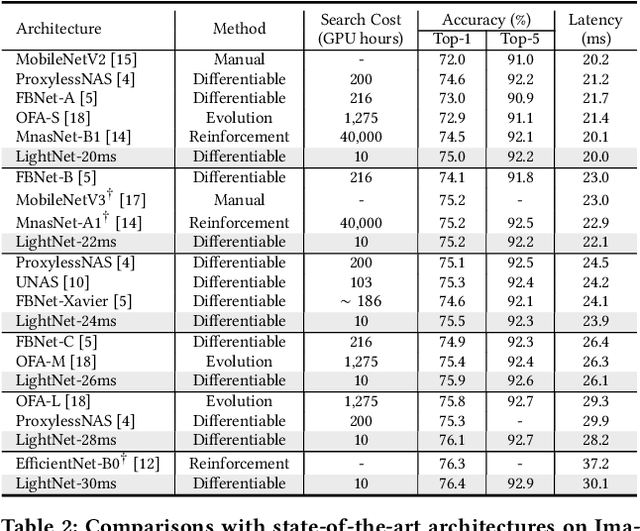
Benefiting from the search efficiency, differentiable neural architecture search (NAS) has evolved as the most dominant alternative to automatically design competitive deep neural networks (DNNs). We note that DNNs must be executed under strictly hard performance constraints in real-world scenarios, for example, the runtime latency on autonomous vehicles. However, to obtain the architecture that meets the given performance constraint, previous hardware-aware differentiable NAS methods have to repeat a plethora of search runs to manually tune the hyper-parameters by trial and error, and thus the total design cost increases proportionally. To resolve this, we introduce a lightweight hardware-aware differentiable NAS framework dubbed LightNAS, striving to find the required architecture that satisfies various performance constraints through a one-time search (i.e., \underline{\textit{you only search once}}). Extensive experiments are conducted to show the superiority of LightNAS over previous state-of-the-art methods.
HSCoNAS: Hardware-Software Co-Design of Efficient DNNs via Neural Architecture Search
Mar 11, 2021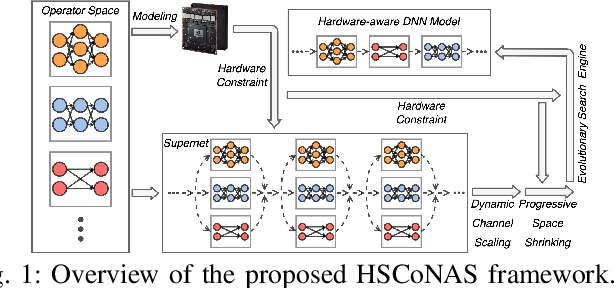
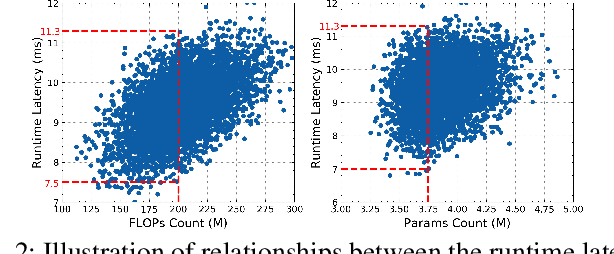
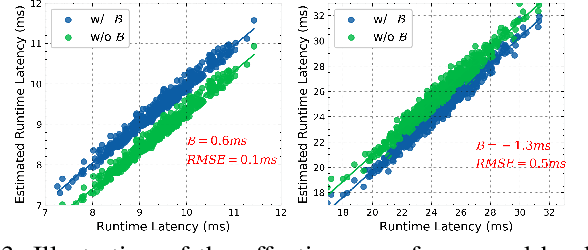
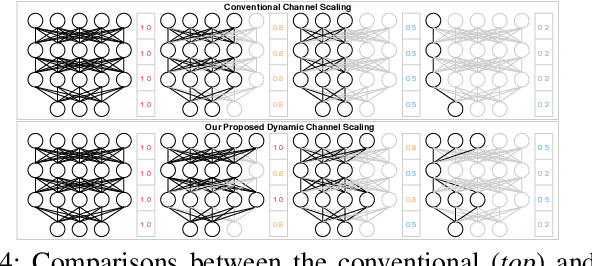
In this paper, we present a novel multi-objective hardware-aware neural architecture search (NAS) framework, namely HSCoNAS, to automate the design of deep neural networks (DNNs) with high accuracy but low latency upon target hardware. To accomplish this goal, we first propose an effective hardware performance modeling method to approximate the runtime latency of DNNs on target hardware, which will be integrated into HSCoNAS to avoid the tedious on-device measurements. Besides, we propose two novel techniques, i.e., dynamic channel scaling to maximize the accuracy under the specified latency and progressive space shrinking to refine the search space towards target hardware as well as alleviate the search overheads. These two techniques jointly work to allow HSCoNAS to perform fine-grained and efficient explorations. Finally, an evolutionary algorithm (EA) is incorporated to conduct the architecture search. Extensive experiments on ImageNet are conducted upon diverse target hardware, i.e., GPU, CPU, and edge device to demonstrate the superiority of HSCoNAS over recent state-of-the-art approaches.
Bringing AI To Edge: From Deep Learning's Perspective
Nov 25, 2020
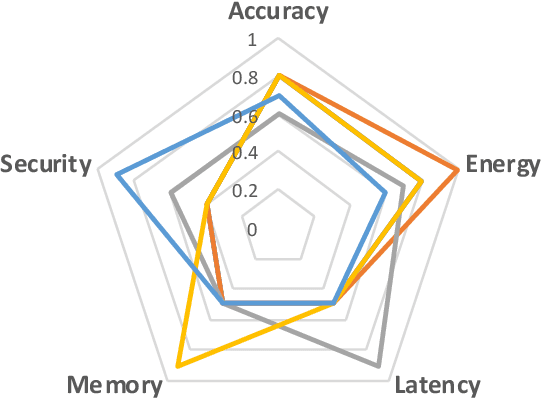
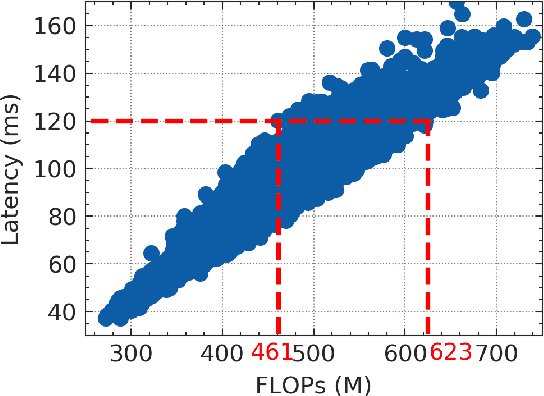
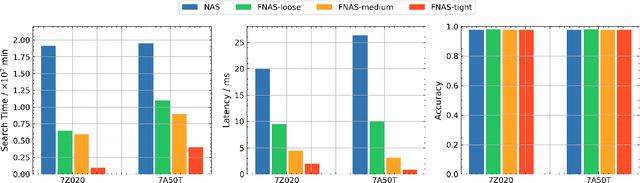
Edge computing and artificial intelligence (AI), especially deep learning for nowadays, are gradually intersecting to build a novel system, called edge intelligence. However, the development of edge intelligence systems encounters some challenges, and one of these challenges is the \textit{computational gap} between computation-intensive deep learning algorithms and less-capable edge systems. Due to the computational gap, many edge intelligence systems cannot meet the expected performance requirements. To bridge the gap, a plethora of deep learning techniques and optimization methods are proposed in the past years: light-weight deep learning models, network compression, and efficient neural architecture search. Although some reviews or surveys have partially covered this large body of literature, we lack a systematic and comprehensive review to discuss all aspects of these deep learning techniques which are critical for edge intelligence implementation. As various and diverse methods which are applicable to edge systems are proposed intensively, a holistic review would enable edge computing engineers and community to know the state-of-the-art deep learning techniques which are instrumental for edge intelligence and to facilitate the development of edge intelligence systems. This paper surveys the representative and latest deep learning techniques that are useful for edge intelligence systems, including hand-crafted models, model compression, hardware-aware neural architecture search and adaptive deep learning models. Finally, based on observations and simple experiments we conducted, we discuss some future directions.