 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Powered Query-Driven Event Timeline Summarization in Industrial Search
May 26, 2026Understanding how events evolve over time is essential for search engines handling queries about trending news. We present QDET (Query-Driven Event Timeline Summarization), a production system deployed on Baidu Search that constructs focused event timelines to explain specific query events. Unlike traditional topic-centric approaches that aim for comprehensive coverage, QDET identifies and organizes sub-events closely relevant to the query from noisy candidate sets formed by millions of documents retrieved daily. QDET incorporates two key innovations: (1) multi-task supervised fine-tuning with three auxiliary tasks-temporal ordering, causal judgment, and timeline completion-that enable compact models to match the performance of much larger general-purpose models in specialized domains; (2) reinforcement learning-based event concise summarization that enforces strict length constraints while maintaining semantic quality, achieving 88.2% length compliance and outperforming 671B-scale models by 7.7 points in constraint satisfaction. Our fine-tuned 7B parameter model achieves 76.2% F1 score on timeline summarization, slightly surpassing the zero-shot performance of DeepSeek-R1-671B (76.1% F1) while using only 1% of its parameters-demonstrating that domain-specific optimization enables production-ready models with comparable quality at drastically reduced computational costs. Online A/B tests on Baidu Search validate real-world effectiveness, showing 5.5% CTR improvement, 4.6% longer dwell time, and 4.4% deeper exploration compared to single-task baselines. We further demonstrate that timeline understanding transfers to heat prediction, confirming effective knowledge transfer to downstream tasks.
Evolution of Optimization Methods: Algorithms, Scenarios, and Evaluations
Apr 14, 2026Balancing convergence speed, generalization capability, and computational efficiency remains a core challenge in deep learning optimization. First-order gradient descent methods, epitomized by stochastic gradient descent (SGD) and Adam, serve as the cornerstone of modern training pipelines. However, large-scale model training, stringent differential privacy requirements, and distributed learning paradigms expose critical limitations in these conventional approaches regarding privacy protection and memory efficiency. To mitigate these bottlenecks, researchers explore second-order optimization techniques to surpass first-order performance ceilings, while zeroth-order methods reemerge to alleviate memory constraints inherent to large-scale training. Despite this proliferation of methodologies, the field lacks a cohesive framework that unifies underlying principles and delineates application scenarios for these disparate approaches. In this work, we retrospectively analyze the evolutionary trajectory of deep learning optimization algorithms and present a comprehensive empirical evaluation of mainstream optimizers across diverse model architectures and training scenarios. We distill key emerging trends and fundamental design trade-offs, pinpointing promising directions for future research. By synthesizing theoretical insights with extensive empirical evidence, we provide actionable guidance for designing next-generation highly efficient, robust, and trustworthy optimization methods. The code is available at https://github.com/APRIL-AIGC/Awesome-Optimizer.
Slow-Fast Inference: Training-Free Inference Acceleration via Within-Sentence Support Stability
Mar 12, 2026Long-context autoregressive decoding remains expensive because each decoding step must repeatedly process a growing history. We observe a consistent pattern during decoding: within a sentence, and more generally within a short semantically coherent span, the dominant attention support often remains largely stable. Motivated by this observation, we propose Slow-Fast Inference (SFI), a training-free decoding framework that decouples generation into frequent low-cost fast steps and occasional dense-attention slow steps. Fast steps reuse a compact sparse memory for efficient decoding. Slow steps are triggered near semantic boundaries. At slow steps, the model revisits the broader context and uses the Selector to refresh the selected memory for subsequent fast steps. Across the evaluated context lengths, SFI delivers approximately $1.6\times$--$14.4\times$ higher decoding throughput while generally maintaining quality on par with the full-KV baseline across long-context and long-CoT settings. Because SFI is training-free and applies directly to existing checkpoints, it offers a practical path to reducing inference cost for contemporary autoregressive reasoning models in long-context, long-horizon, and agentic workloads.
Optimization Hyper-parameter Laws for Large Language Models
Sep 07, 2024



Large Language Models have driven significant AI advancements, yet their training is resource-intensive and highly sensitive to hyper-parameter selection. While scaling laws provide valuable guidance on model size and data requirements, they fall short in choosing dynamic hyper-parameters, such as learning-rate (LR) schedules, that evolve during training. To bridge this gap, we present Optimization Hyper-parameter Laws (Opt-Laws), a framework that effectively captures the relationship between hyper-parameters and training outcomes, enabling the pre-selection of potential optimal schedules. Grounded in stochastic differential equations, Opt-Laws introduce novel mathematical interpretability and offer a robust theoretical foundation for some popular LR schedules. Our extensive validation across diverse model sizes and data scales demonstrates Opt-Laws' ability to accurately predict training loss and identify optimal LR schedule candidates in pre-training, continual training, and fine-tuning scenarios. This approach significantly reduces computational costs while enhancing overall model performance.
LoCo: Low-Bit Communication Adaptor for Large-scale Model Training
Jul 05, 2024To efficiently train large-scale models, low-bit gradient communication compresses full-precision gradients on local GPU nodes into low-precision ones for higher gradient synchronization efficiency among GPU nodes. However, it often degrades training quality due to compression information loss. To address this, we propose the Low-bit Communication Adaptor (LoCo), which compensates gradients on local GPU nodes before compression, ensuring efficient synchronization without compromising training quality. Specifically, LoCo designs a moving average of historical compensation errors to stably estimate concurrent compression error and then adopts it to compensate for the concurrent gradient compression, yielding a less lossless compression. This mechanism allows it to be compatible with general optimizers like Adam and sharding strategies like FSDP. Theoretical analysis shows that integrating LoCo into full-precision optimizers like Adam and SGD does not impair their convergence speed on nonconvex problems. Experimental results show that across large-scale model training frameworks like Megatron-LM and PyTorch's FSDP, LoCo significantly improves communication efficiency, e.g., improving Adam's training speed by 14% to 40% without performance degradation on large language models like LLAMAs and MoE.
On the Algorithmic Bias of Aligning Large Language Models with RLHF: Preference Collapse and Matching Regularization
May 26, 2024Accurately aligning large language models (LLMs) with human preferences is crucial for informing fair, economically sound, and statistically efficient decision-making processes. However, we argue that reinforcement learning from human feedback (RLHF) -- the predominant approach for aligning LLMs with human preferences through a reward model -- suffers from an inherent algorithmic bias due to its Kullback--Leibler-based regularization in optimization. In extreme cases, this bias could lead to a phenomenon we term preference collapse, where minority preferences are virtually disregarded. To mitigate this algorithmic bias, we introduce preference matching (PM) RLHF, a novel approach that provably aligns LLMs with the preference distribution of the reward model under the Bradley--Terry--Luce/Plackett--Luce model. Central to our approach is a PM regularizer that takes the form of the negative logarithm of the LLM's policy probability distribution over responses, which helps the LLM balance response diversification and reward maximization. Notably, we obtain this regularizer by solving an ordinary differential equation that is necessary for the PM property. For practical implementation, we introduce a conditional variant of PM RLHF that is tailored to natural language generation. Finally, we empirically validate the effectiveness of conditional PM RLHF through experiments on the OPT-1.3B and Llama-2-7B models, demonstrating a 29% to 41% improvement in alignment with human preferences, as measured by a certain metric, compared to standard RLHF.
Task-Robust Pre-Training for Worst-Case Downstream Adaptation
Jul 05, 2023



Pre-training has achieved remarkable success when transferred to downstream tasks. In machine learning, we care about not only the good performance of a model but also its behavior under reasonable shifts of condition. The same philosophy holds when pre-training a foundation model. However, the foundation model may not uniformly behave well for a series of related downstream tasks. This happens, for example, when conducting mask recovery regression where the recovery ability or the training instances diverge like pattern features are extracted dominantly on pre-training, but semantic features are also required on a downstream task. This paper considers pre-training a model that guarantees a uniformly good performance over the downstream tasks. We call this goal as $\textit{downstream-task robustness}$. Our method first separates the upstream task into several representative ones and applies a simple minimax loss for pre-training. We then design an efficient algorithm to solve the minimax loss and prove its convergence in the convex setting. In the experiments, we show both on large-scale natural language processing and computer vision datasets our method increases the metrics on worse-case downstream tasks. Additionally, some theoretical explanations for why our loss is beneficial are provided. Specifically, we show fewer samples are inherently required for the most challenging downstream task in some cases.
Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models
Sep 01, 2022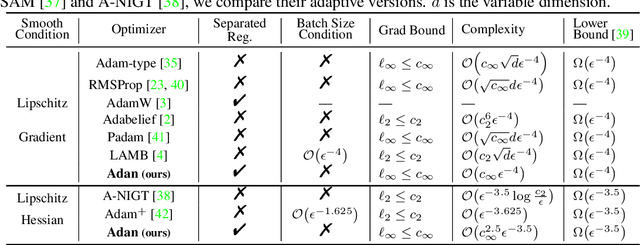


Adaptive gradient algorithms borrow the moving average idea of heavy ball acceleration to estimate accurate first- and second-order moments of gradient for accelerating convergence. However, Nesterov acceleration which converges faster than heavy ball acceleration in theory and also in many empirical cases is much less investigated under the adaptive gradient setting. In this work, we propose the ADAptive Nesterov momentum algorithm, Adan for short, to speed up the training of deep neural networks effectively. Adan first reformulates the vanilla Nesterov acceleration to develop a new Nesterov momentum estimation (NME) method, which avoids the extra computation and memory overhead of computing gradient at the extrapolation point. Then Adan adopts NME to estimate the first- and second-order moments of the gradient in adaptive gradient algorithms for convergence acceleration. Besides, we prove that Adan finds an $\epsilon$-approximate first-order stationary point within $O(\epsilon^{-3.5})$ stochastic gradient complexity on the nonconvex stochastic problems (e.g., deep learning problems), matching the best-known lower bound. Extensive experimental results show that Adan surpasses the corresponding SoTA optimizers on both vision transformers (ViTs) and CNNs, and sets new SoTAs for many popular networks, e.g., ResNet, ConvNext, ViT, Swin, MAE, LSTM, Transformer-XL, and BERT. More surprisingly, Adan can use half of the training cost (epochs) of SoTA optimizers to achieve higher or comparable performance on ViT and ResNet, e.t.c., and also shows great tolerance to a large range of minibatch size, e.g., from 1k to 32k. We hope Adan can contribute to the development of deep learning by reducing training cost and relieving engineering burden of trying different optimizers on various architectures. Code is released at https://github.com/sail-sg/Adan.
Global Convergence of Over-parameterized Deep Equilibrium Models
May 27, 2022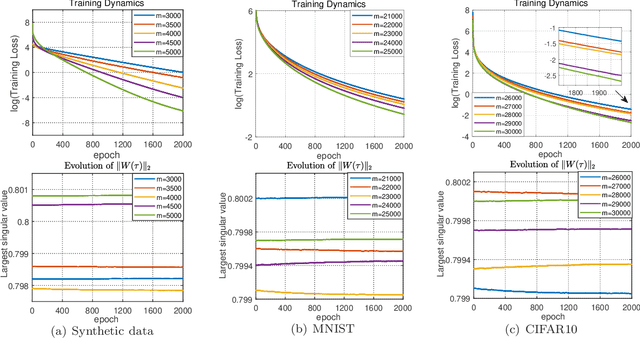
A deep equilibrium model (DEQ) is implicitly defined through an equilibrium point of an infinite-depth weight-tied model with an input-injection. Instead of infinite computations, it solves an equilibrium point directly with root-finding and computes gradients with implicit differentiation. The training dynamics of over-parameterized DEQs are investigated in this study. By supposing a condition on the initial equilibrium point, we show that the unique equilibrium point always exists during the training process, and the gradient descent is proved to converge to a globally optimal solution at a linear convergence rate for the quadratic loss function. In order to show that the required initial condition is satisfied via mild over-parameterization, we perform a fine-grained analysis on random DEQs. We propose a novel probabilistic framework to overcome the technical difficulty in the non-asymptotic analysis of infinite-depth weight-tied models.
High Quality Segmentation for Ultra High-resolution Images
Dec 26, 2021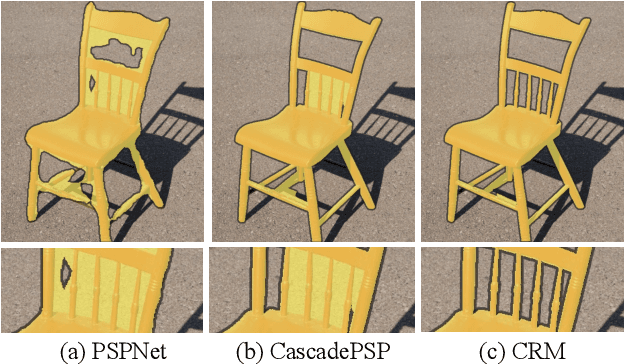
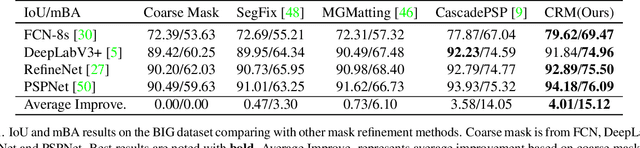
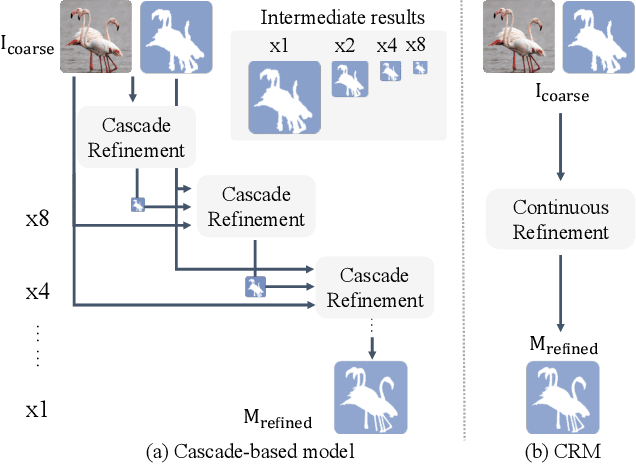
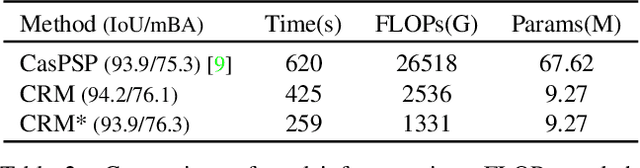
To segment 4K or 6K ultra high-resolution images needs extra computation consideration in image segmentation. Common strategies, such as down-sampling, patch cropping, and cascade model, cannot address well the balance issue between accuracy and computation cost. Motivated by the fact that humans distinguish among objects continuously from coarse to precise levels, we propose the Continuous Refinement Model~(CRM) for the ultra high-resolution segmentation refinement task. CRM continuously aligns the feature map with the refinement target and aggregates features to reconstruct these images' details. Besides, our CRM shows its significant generalization ability to fill the resolution gap between low-resolution training images and ultra high-resolution testing ones. We present quantitative performance evaluation and visualization to show that our proposed method is fast and effective on image segmentation refinement. Code will be released at https://github.com/dvlab-research/Entity.