 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Pseudo-Zeroth-Order Training of Neuromorphic Spiking Neural Networks
Jul 17, 2024



Brain-inspired neuromorphic computing with spiking neural networks (SNNs) is a promising energy-efficient computational approach. However, successfully training SNNs in a more biologically plausible and neuromorphic-hardware-friendly way is still challenging. Most recent methods leverage spatial and temporal backpropagation (BP), not adhering to neuromorphic properties. Despite the efforts of some online training methods, tackling spatial credit assignments by alternatives with comparable performance as spatial BP remains a significant problem. In this work, we propose a novel method, online pseudo-zeroth-order (OPZO) training. Our method only requires a single forward propagation with noise injection and direct top-down signals for spatial credit assignment, avoiding spatial BP's problem of symmetric weights and separate phases for layer-by-layer forward-backward propagation. OPZO solves the large variance problem of zeroth-order methods by the pseudo-zeroth-order formulation and momentum feedback connections, while having more guarantees than random feedback. Combining online training, OPZO can pave paths to on-chip SNN training. Experiments on neuromorphic and static datasets with fully connected and convolutional networks demonstrate the effectiveness of OPZO with similar performance compared with spatial BP, as well as estimated low training costs.
Hebbian Learning based Orthogonal Projection for Continual Learning of Spiking Neural Networks
Feb 19, 2024

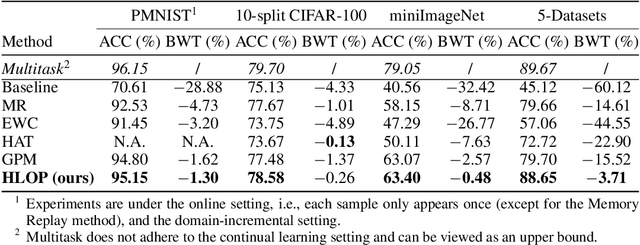

Neuromorphic computing with spiking neural networks is promising for energy-efficient artificial intelligence (AI) applications. However, different from humans who continually learn different tasks in a lifetime, neural network models suffer from catastrophic forgetting. How could neuronal operations solve this problem is an important question for AI and neuroscience. Many previous studies draw inspiration from observed neuroscience phenomena and propose episodic replay or synaptic metaplasticity, but they are not guaranteed to explicitly preserve knowledge for neuron populations. Other works focus on machine learning methods with more mathematical grounding, e.g., orthogonal projection on high dimensional spaces, but there is no neural correspondence for neuromorphic computing. In this work, we develop a new method with neuronal operations based on lateral connections and Hebbian learning, which can protect knowledge by projecting activity traces of neurons into an orthogonal subspace so that synaptic weight update will not interfere with old tasks. We show that Hebbian and anti-Hebbian learning on recurrent lateral connections can effectively extract the principal subspace of neural activities and enable orthogonal projection. This provides new insights into how neural circuits and Hebbian learning can help continual learning, and also how the concept of orthogonal projection can be realized in neuronal systems. Our method is also flexible to utilize arbitrary training methods based on presynaptic activities/traces. Experiments show that our method consistently solves forgetting for spiking neural networks with nearly zero forgetting under various supervised training methods with different error propagation approaches, and outperforms previous approaches under various settings. Our method can pave a solid path for building continual neuromorphic computing systems.
SPIDE: A Purely Spike-based Method for Training Feedback Spiking Neural Networks
Feb 01, 2023
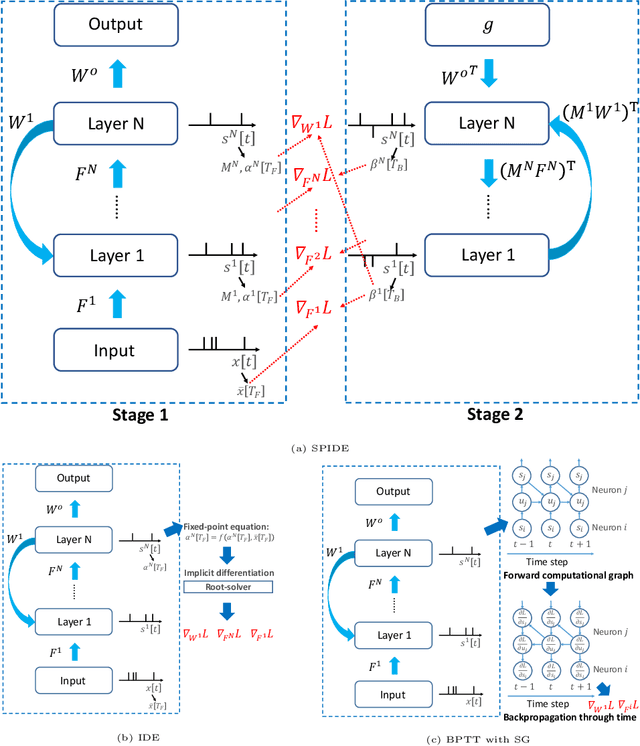
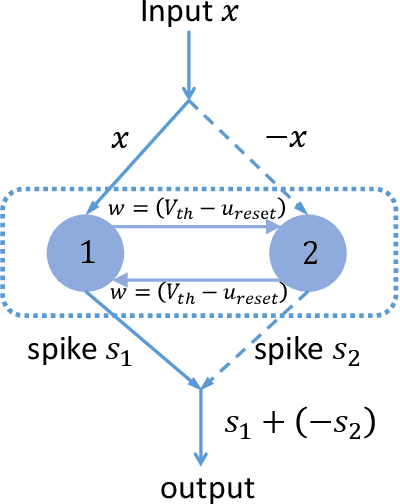

Spiking neural networks (SNNs) with event-based computation are promising brain-inspired models for energy-efficient applications on neuromorphic hardware. However, most supervised SNN training methods, such as conversion from artificial neural networks or direct training with surrogate gradients, require complex computation rather than spike-based operations of spiking neurons during training. In this paper, we study spike-based implicit differentiation on the equilibrium state (SPIDE) that extends the recently proposed training method, implicit differentiation on the equilibrium state (IDE), for supervised learning with purely spike-based computation, which demonstrates the potential for energy-efficient training of SNNs. Specifically, we introduce ternary spiking neuron couples and prove that implicit differentiation can be solved by spikes based on this design, so the whole training procedure, including both forward and backward passes, is made as event-driven spike computation, and weights are updated locally with two-stage average firing rates. Then we propose to modify the reset membrane potential to reduce the approximation error of spikes. With these key components, we can train SNNs with flexible structures in a small number of time steps and with firing sparsity during training, and the theoretical estimation of energy costs demonstrates the potential for high efficiency. Meanwhile, experiments show that even with these constraints, our trained models can still achieve competitive results on MNIST, CIFAR-10, CIFAR-100, and CIFAR10-DVS. Our code is available at https://github.com/pkuxmq/SPIDE-FSNN.
Online Training Through Time for Spiking Neural Networks
Oct 09, 2022

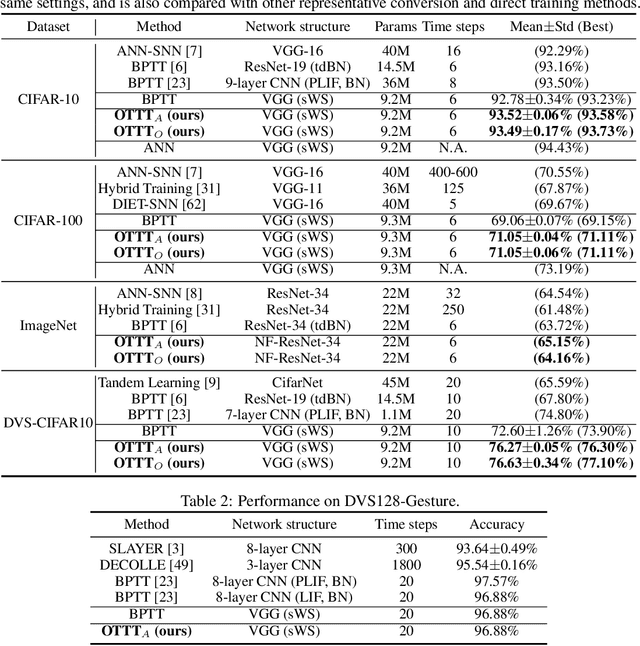
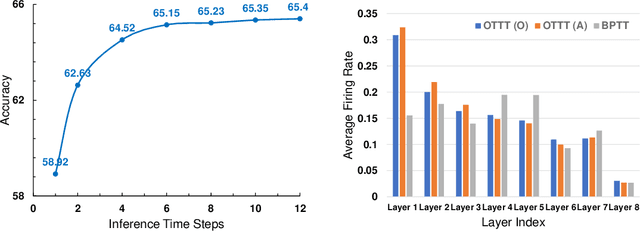
Spiking neural networks (SNNs) are promising brain-inspired energy-efficient models. Recent progress in training methods has enabled successful deep SNNs on large-scale tasks with low latency. Particularly, backpropagation through time (BPTT) with surrogate gradients (SG) is popularly used to achieve high performance in a very small number of time steps. However, it is at the cost of large memory consumption for training, lack of theoretical clarity for optimization, and inconsistency with the online property of biological learning and rules on neuromorphic hardware. Other works connect spike representations of SNNs with equivalent artificial neural network formulation and train SNNs by gradients from equivalent mappings to ensure descent directions. But they fail to achieve low latency and are also not online. In this work, we propose online training through time (OTTT) for SNNs, which is derived from BPTT to enable forward-in-time learning by tracking presynaptic activities and leveraging instantaneous loss and gradients. Meanwhile, we theoretically analyze and prove that gradients of OTTT can provide a similar descent direction for optimization as gradients based on spike representations under both feedforward and recurrent conditions. OTTT only requires constant training memory costs agnostic to time steps, avoiding the significant memory costs of BPTT for GPU training. Furthermore, the update rule of OTTT is in the form of three-factor Hebbian learning, which could pave a path for online on-chip learning. With OTTT, it is the first time that two mainstream supervised SNN training methods, BPTT with SG and spike representation-based training, are connected, and meanwhile in a biologically plausible form. Experiments on CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS demonstrate the superior performance of our method on large-scale static and neuromorphic datasets in small time steps.
Global Convergence of Over-parameterized Deep Equilibrium Models
May 27, 2022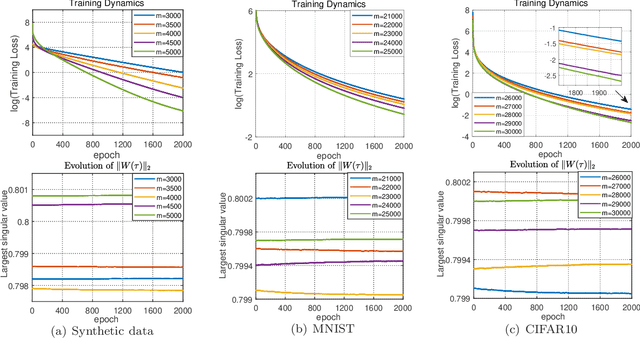
A deep equilibrium model (DEQ) is implicitly defined through an equilibrium point of an infinite-depth weight-tied model with an input-injection. Instead of infinite computations, it solves an equilibrium point directly with root-finding and computes gradients with implicit differentiation. The training dynamics of over-parameterized DEQs are investigated in this study. By supposing a condition on the initial equilibrium point, we show that the unique equilibrium point always exists during the training process, and the gradient descent is proved to converge to a globally optimal solution at a linear convergence rate for the quadratic loss function. In order to show that the required initial condition is satisfied via mild over-parameterization, we perform a fine-grained analysis on random DEQs. We propose a novel probabilistic framework to overcome the technical difficulty in the non-asymptotic analysis of infinite-depth weight-tied models.
Training Feedback Spiking Neural Networks by Implicit Differentiation on the Equilibrium State
Sep 29, 2021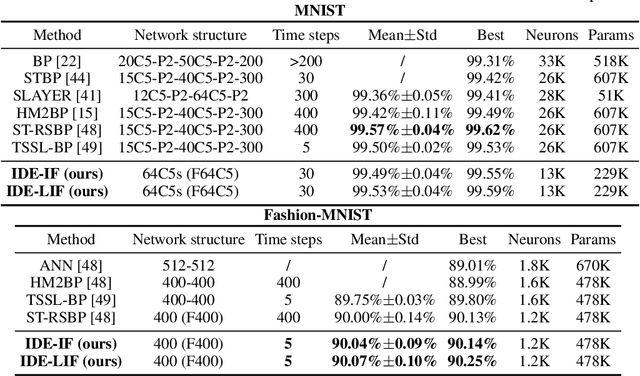
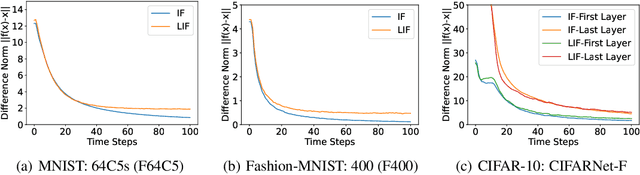
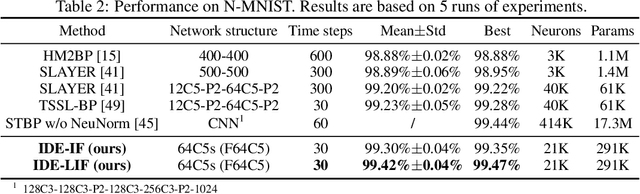
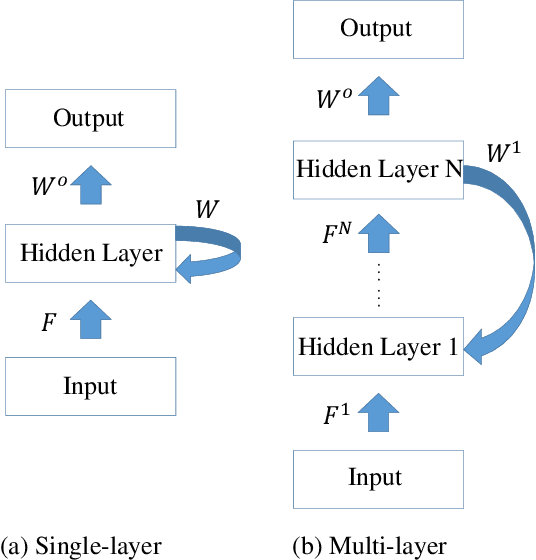
Spiking neural networks (SNNs) are brain-inspired models that enable energy-efficient implementation on neuromorphic hardware. However, the supervised training of SNNs remains a hard problem due to the discontinuity of the spiking neuron model. Most existing methods imitate the backpropagation framework and feedforward architectures for artificial neural networks, and use surrogate derivatives or compute gradients with respect to the spiking time to deal with the problem. These approaches either accumulate approximation errors or only propagate information limitedly through existing spikes, and usually require information propagation along time steps with large memory costs and biological implausibility. In this work, we consider feedback spiking neural networks, which are more brain-like, and propose a novel training method that does not rely on the exact reverse of the forward computation. First, we show that the average firing rates of SNNs with feedback connections would gradually evolve to an equilibrium state along time, which follows a fixed-point equation. Then by viewing the forward computation of feedback SNNs as a black-box solver for this equation, and leveraging the implicit differentiation on the equation, we can compute the gradient for parameters without considering the exact forward procedure. In this way, the forward and backward procedures are decoupled and therefore the problem of non-differentiable spiking functions is avoided. We also briefly discuss the biological plausibility of implicit differentiation, which only requires computing another equilibrium. Extensive experiments on MNIST, Fashion-MNIST, N-MNIST, CIFAR-10, and CIFAR-100 demonstrate the superior performance of our method for feedback models with fewer neurons and parameters in a small number of time steps. Our code is avaiable at https://github.com/pkuxmq/IDE-FSNN.