 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond representational alignment with brain-guided language models for robust reasoning
Jun 10, 2026The correspondence between large language models (LLMs) and the neural mechanisms underlying human higher-order cognition remains insufficiently characterized. Given that language and reasoning in the human brain appear dissociable, an open question is whether LLMs align with neural signals from reasoning-related regions and whether such signals can improve them. Here, focusing on deductive reasoning, we show that LLM internal representations are not only partially aligned with task-fMRI activity but can also be directly enhanced by these signals. Using a neural-predictivity metric, we find that LLMs explain a substantial fraction of the explainable variance in reasoning-related regions at the aggregate level, whereas predictivity within specific reasoning types is lower, indicating both alignment and divergence. Building on this, we propose a brain-guided framework: we steer model representations along directions induced by the joint structure of model and brain representations, applying intervention at inference and fine-tuning during training. We demonstrate that task-evoked brain signals can directly enhance LLM reasoning, yielding gains orthogonal to language-only supervision across 10 LLMs (1.5B-72B), with transfer across reasoning types and up to 13\% absolute accuracy gain. Our results advance LLM-brain correspondences from correlation to guidance, establishing a brain-signal-driven pathway toward more robust and cognitively aligned AI.
Kuramoto Oscillatory Phase Encoding: Neuro-inspired Synchronization for Improved Learning Efficiency
Apr 09, 2026Spatiotemporal neural dynamics and oscillatory synchronization are widely implicated in biological information processing and have been hypothesized to support flexible coordination such as feature binding. By contrast, most deep learning architectures represent and propagate information through activation values, neglecting the joint dynamics of rate and phase. In this work, we introduce Kuramoto oscillatory Phase Encoding (KoPE) as an additional, evolving phase state to Vision Transformers, incorporating a neuro-inspired synchronization mechanism to advance learning efficiency. We show that KoPE can improve training, parameter, and data efficiency of vision models through synchronization-enhanced structure learning. Moreover, KoPE benefits tasks requiring structured understanding, including semantic and panoptic segmentation, representation alignment with language, and few-shot abstract visual reasoning (ARC-AGI). Theoretical analysis and empirical verification further suggest that KoPE can accelerate attention concentration for learning efficiency. These results indicate that synchronization can serve as a scalable, neuro-inspired mechanism for advancing state-of-the-art neural network models.
Predicting Neuromodulation Outcome for Parkinson's Disease with Generative Virtual Brain Model
Mar 31, 2026Parkinson's disease (PD) affects over ten million people worldwide. Although temporal interference (TI) and deep brain stimulation (DBS) are promising therapies, inter-individual variability limits empirical treatment selection, increasing non-negligible surgical risk and cost. Previous explorations either resort to limited statistical biomarkers that are insufficient to characterize variability, or employ AI-driven methods which is prone to overfitting and opacity. We bridge this gap with a pretraining-finetuning framework to predict outcomes directly from resting-state fMRI. Critically, a generative virtual brain foundation model, pretrained on a collective dataset (2707 subjects, 5621 sessions) to capture universal disorder patterns, was finetuned on PD cohorts receiving TI (n=51) or DBS (n=55) to yield individualized virtual brains with high fidelity to empirical functional connectivity (r=0.935). By constructing counterfactual estimations between pathological and healthy neural states within these personalized models, we predicted clinical responses (TI: AUPR=0.853; DBS: AUPR=0.915), substantially outperforming baselines. External and prospective validations (n=14, n=11) highlight the feasibility of clinical translation. Moreover, our framework provides state-dependent regional patterns linked to response, offering hypothesis-generating mechanistic insights.
A Self-Ensemble Inspired Approach for Effective Training of Binary-Weight Spiking Neural Networks
Aug 18, 2025Spiking Neural Networks (SNNs) are a promising approach to low-power applications on neuromorphic hardware due to their energy efficiency. However, training SNNs is challenging because of the non-differentiable spike generation function. To address this issue, the commonly used approach is to adopt the backpropagation through time framework, while assigning the gradient of the non-differentiable function with some surrogates. Similarly, Binary Neural Networks (BNNs) also face the non-differentiability problem and rely on approximating gradients. However, the deep relationship between these two fields and how their training techniques can benefit each other has not been systematically researched. Furthermore, training binary-weight SNNs is even more difficult. In this work, we present a novel perspective on the dynamics of SNNs and their close connection to BNNs through an analysis of the backpropagation process. We demonstrate that training a feedforward SNN can be viewed as training a self-ensemble of a binary-activation neural network with noise injection. Drawing from this new understanding of SNN dynamics, we introduce the Self-Ensemble Inspired training method for (Binary-Weight) SNNs (SEI-BWSNN), which achieves high-performance results with low latency even for the case of the 1-bit weights. Specifically, we leverage a structure of multiple shortcuts and a knowledge distillation-based training technique to improve the training of (binary-weight) SNNs. Notably, by binarizing FFN layers in a Transformer architecture, our approach achieves 82.52% accuracy on ImageNet with only 2 time steps, indicating the effectiveness of our methodology and the potential of binary-weight SNNs.
Online Pseudo-Zeroth-Order Training of Neuromorphic Spiking Neural Networks
Jul 17, 2024



Brain-inspired neuromorphic computing with spiking neural networks (SNNs) is a promising energy-efficient computational approach. However, successfully training SNNs in a more biologically plausible and neuromorphic-hardware-friendly way is still challenging. Most recent methods leverage spatial and temporal backpropagation (BP), not adhering to neuromorphic properties. Despite the efforts of some online training methods, tackling spatial credit assignments by alternatives with comparable performance as spatial BP remains a significant problem. In this work, we propose a novel method, online pseudo-zeroth-order (OPZO) training. Our method only requires a single forward propagation with noise injection and direct top-down signals for spatial credit assignment, avoiding spatial BP's problem of symmetric weights and separate phases for layer-by-layer forward-backward propagation. OPZO solves the large variance problem of zeroth-order methods by the pseudo-zeroth-order formulation and momentum feedback connections, while having more guarantees than random feedback. Combining online training, OPZO can pave paths to on-chip SNN training. Experiments on neuromorphic and static datasets with fully connected and convolutional networks demonstrate the effectiveness of OPZO with similar performance compared with spatial BP, as well as estimated low training costs.
Temporal Spiking Neural Networks with Synaptic Delay for Graph Reasoning
May 27, 2024



Spiking neural networks (SNNs) are investigated as biologically inspired models of neural computation, distinguished by their computational capability and energy efficiency due to precise spiking times and sparse spikes with event-driven computation. A significant question is how SNNs can emulate human-like graph-based reasoning of concepts and relations, especially leveraging the temporal domain optimally. This paper reveals that SNNs, when amalgamated with synaptic delay and temporal coding, are proficient in executing (knowledge) graph reasoning. It is elucidated that spiking time can function as an additional dimension to encode relation properties via a neural-generalized path formulation. Empirical results highlight the efficacy of temporal delay in relation processing and showcase exemplary performance in diverse graph reasoning tasks. The spiking model is theoretically estimated to achieve $20\times$ energy savings compared to non-spiking counterparts, deepening insights into the capabilities and potential of biologically inspired SNNs for efficient reasoning. The code is available at https://github.com/pkuxmq/GRSNN.
Hebbian Learning based Orthogonal Projection for Continual Learning of Spiking Neural Networks
Feb 19, 2024

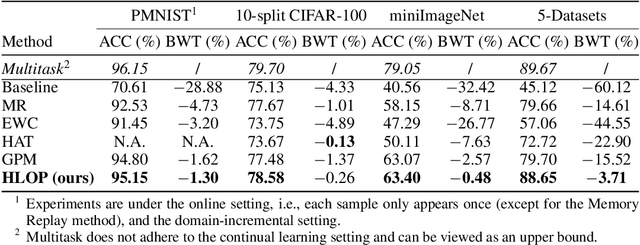

Neuromorphic computing with spiking neural networks is promising for energy-efficient artificial intelligence (AI) applications. However, different from humans who continually learn different tasks in a lifetime, neural network models suffer from catastrophic forgetting. How could neuronal operations solve this problem is an important question for AI and neuroscience. Many previous studies draw inspiration from observed neuroscience phenomena and propose episodic replay or synaptic metaplasticity, but they are not guaranteed to explicitly preserve knowledge for neuron populations. Other works focus on machine learning methods with more mathematical grounding, e.g., orthogonal projection on high dimensional spaces, but there is no neural correspondence for neuromorphic computing. In this work, we develop a new method with neuronal operations based on lateral connections and Hebbian learning, which can protect knowledge by projecting activity traces of neurons into an orthogonal subspace so that synaptic weight update will not interfere with old tasks. We show that Hebbian and anti-Hebbian learning on recurrent lateral connections can effectively extract the principal subspace of neural activities and enable orthogonal projection. This provides new insights into how neural circuits and Hebbian learning can help continual learning, and also how the concept of orthogonal projection can be realized in neuronal systems. Our method is also flexible to utilize arbitrary training methods based on presynaptic activities/traces. Experiments show that our method consistently solves forgetting for spiking neural networks with nearly zero forgetting under various supervised training methods with different error propagation approaches, and outperforms previous approaches under various settings. Our method can pave a solid path for building continual neuromorphic computing systems.
Towards Memory- and Time-Efficient Backpropagation for Training Spiking Neural Networks
Mar 07, 2023



Spiking Neural Networks (SNNs) are promising energy-efficient models for neuromorphic computing. For training the non-differentiable SNN models, the backpropagation through time (BPTT) with surrogate gradients (SG) method has achieved high performance. However, this method suffers from considerable memory cost and training time during training. In this paper, we propose the Spatial Learning Through Time (SLTT) method that can achieve high performance while greatly improving training efficiency compared with BPTT. First, we show that the backpropagation of SNNs through the temporal domain contributes just a little to the final calculated gradients. Thus, we propose to ignore the unimportant routes in the computational graph during backpropagation. The proposed method reduces the number of scalar multiplications and achieves a small memory occupation that is independent of the total time steps. Furthermore, we propose a variant of SLTT, called SLTT-K, that allows backpropagation only at K time steps, then the required number of scalar multiplications is further reduced and is independent of the total time steps. Experiments on both static and neuromorphic datasets demonstrate superior training efficiency and performance of our SLTT. In particular, our method achieves state-of-the-art accuracy on ImageNet, while the memory cost and training time are reduced by more than 70% and 50%, respectively, compared with BPTT.
SPIDE: A Purely Spike-based Method for Training Feedback Spiking Neural Networks
Feb 01, 2023
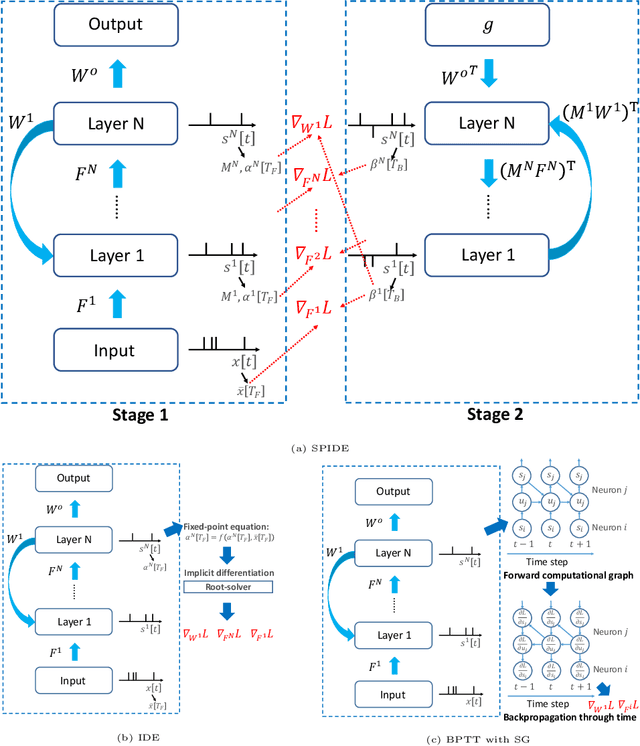
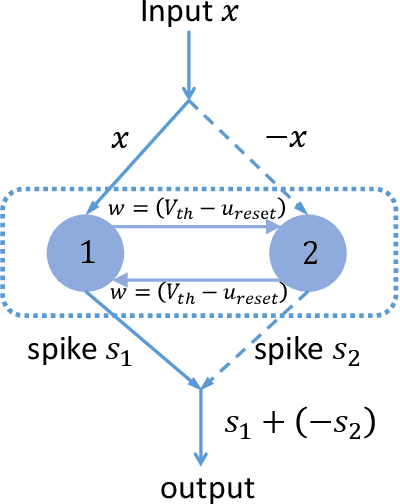

Spiking neural networks (SNNs) with event-based computation are promising brain-inspired models for energy-efficient applications on neuromorphic hardware. However, most supervised SNN training methods, such as conversion from artificial neural networks or direct training with surrogate gradients, require complex computation rather than spike-based operations of spiking neurons during training. In this paper, we study spike-based implicit differentiation on the equilibrium state (SPIDE) that extends the recently proposed training method, implicit differentiation on the equilibrium state (IDE), for supervised learning with purely spike-based computation, which demonstrates the potential for energy-efficient training of SNNs. Specifically, we introduce ternary spiking neuron couples and prove that implicit differentiation can be solved by spikes based on this design, so the whole training procedure, including both forward and backward passes, is made as event-driven spike computation, and weights are updated locally with two-stage average firing rates. Then we propose to modify the reset membrane potential to reduce the approximation error of spikes. With these key components, we can train SNNs with flexible structures in a small number of time steps and with firing sparsity during training, and the theoretical estimation of energy costs demonstrates the potential for high efficiency. Meanwhile, experiments show that even with these constraints, our trained models can still achieve competitive results on MNIST, CIFAR-10, CIFAR-100, and CIFAR10-DVS. Our code is available at https://github.com/pkuxmq/SPIDE-FSNN.
Invertible Rescaling Network and Its Extensions
Oct 09, 2022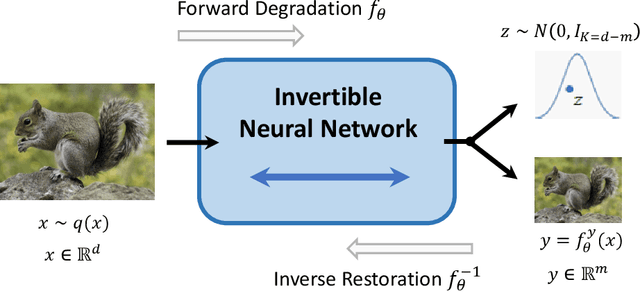
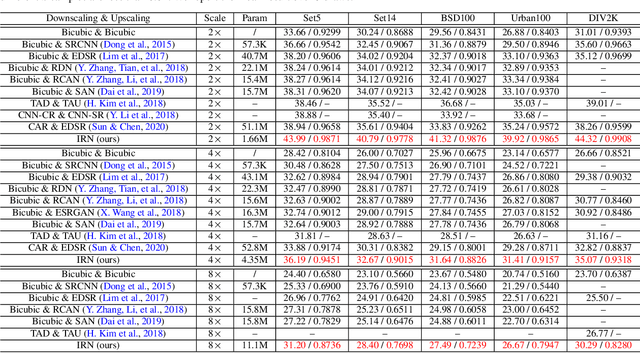
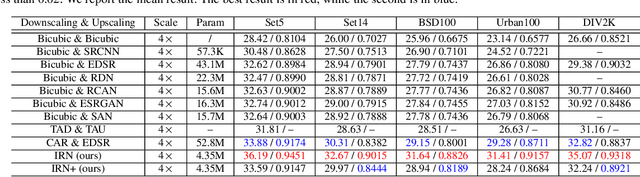
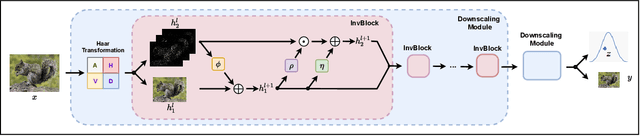
Image rescaling is a commonly used bidirectional operation, which first downscales high-resolution images to fit various display screens or to be storage- and bandwidth-friendly, and afterward upscales the corresponding low-resolution images to recover the original resolution or the details in the zoom-in images. However, the non-injective downscaling mapping discards high-frequency contents, leading to the ill-posed problem for the inverse restoration task. This can be abstracted as a general image degradation-restoration problem with information loss. In this work, we propose a novel invertible framework to handle this general problem, which models the bidirectional degradation and restoration from a new perspective, i.e. invertible bijective transformation. The invertibility enables the framework to model the information loss of pre-degradation in the form of distribution, which could mitigate the ill-posed problem during post-restoration. To be specific, we develop invertible models to generate valid degraded images and meanwhile transform the distribution of lost contents to the fixed distribution of a latent variable during the forward degradation. Then restoration is made tractable by applying the inverse transformation on the generated degraded image together with a randomly-drawn latent variable. We start from image rescaling and instantiate the model as Invertible Rescaling Network (IRN), which can be easily extended to the similar decolorization-colorization task. We further propose to combine the invertible framework with existing degradation methods such as image compression for wider applications. Experimental results demonstrate the significant improvement of our model over existing methods in terms of both quantitative and qualitative evaluations of upscaling and colorizing reconstruction from downscaled and decolorized images, and rate-distortion of image compression.