 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleGuardian: A Framework for Automatic RespiratorySound classification Based on Improved Deep clustering and Contrastive Learning
Feb 02, 2025Auscultation plays a pivotal role in early respiratory and pulmonary disease diagnosis. Despite the emergence of deep learning-based methods for automatic respiratory sound classification post-Covid-19, limited datasets impede performance enhancement. Distinguishing between normal and abnormal respiratory sounds poses challenges due to the coexistence of normal respiratory components and noise components in both types. Moreover, different abnormal respiratory sounds exhibit similar anomalous features, hindering their differentiation. Besides, existing state-of-the-art models suffer from excessive parameter size, impeding deployment on resource-constrained mobile platforms. To address these issues, we design a lightweight network CycleGuardian and propose a framework based on an improved deep clustering and contrastive learning. We first generate a hybrid spectrogram for feature diversity and grouping spectrograms to facilitating intermittent abnormal sound capture.Then, CycleGuardian integrates a deep clustering module with a similarity-constrained clustering component to improve the ability to capture abnormal features and a contrastive learning module with group mixing for enhanced abnormal feature discernment. Multi-objective optimization enhances overall performance during training. In experiments we use the ICBHI2017 dataset, following the official split method and without any pre-trained weights, our method achieves Sp: 82.06 $\%$, Se: 44.47$\%$, and Score: 63.26$\%$ with a network model size of 38M, comparing to the current model, our method leads by nearly 7$\%$, achieving the current best performances. Additionally, we deploy the network on Android devices, showcasing a comprehensive intelligent respiratory sound auscultation system.
Policy Gradient for Robust Markov Decision Processes
Oct 29, 2024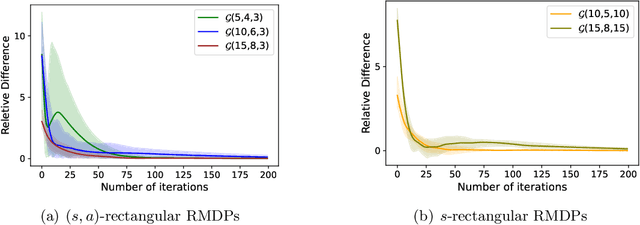
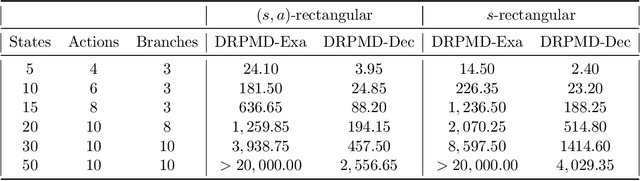
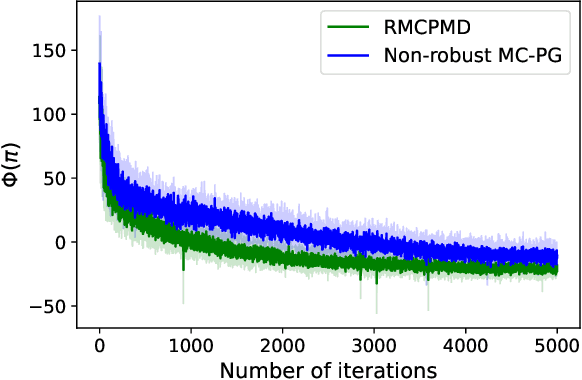
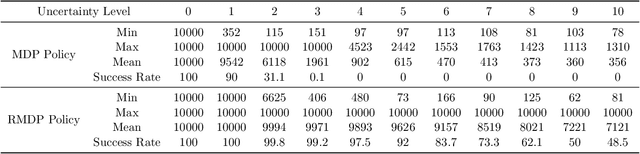
We develop a generic policy gradient method with the global optimality guarantee for robust Markov Decision Processes (MDPs). While policy gradient methods are widely used for solving dynamic decision problems due to their scalable and efficient nature, adapting these methods to account for model ambiguity has been challenging, often making it impractical to learn robust policies. This paper introduces a novel policy gradient method, Double-Loop Robust Policy Mirror Descent (DRPMD), for solving robust MDPs. DRPMD employs a general mirror descent update rule for the policy optimization with adaptive tolerance per iteration, guaranteeing convergence to a globally optimal policy. We provide a comprehensive analysis of DRPMD, including new convergence results under both direct and softmax parameterizations, and provide novel insights into the inner problem solution through Transition Mirror Ascent (TMA). Additionally, we propose innovative parametric transition kernels for both discrete and continuous state-action spaces, broadening the applicability of our approach. Empirical results validate the robustness and global convergence of DRPMD across various challenging robust MDP settings.
On the Convergence of Policy Gradient in Robust MDPs
Dec 20, 2022


Robust Markov decision processes (RMDPs) are promising models that provide reliable policies under ambiguities in model parameters. As opposed to nominal Markov decision processes (MDPs), however, the state-of-the-art solution methods for RMDPs are limited to value-based methods, such as value iteration and policy iteration. This paper proposes Double-Loop Robust Policy Gradient (DRPG), the first generic policy gradient method for RMDPs with a global convergence guarantee in tabular problems. Unlike value-based methods, DRPG does not rely on dynamic programming techniques. In particular, the inner-loop robust policy evaluation problem is solved via projected gradient descent. Finally, our experimental results demonstrate the performance of our algorithm and verify our theoretical guarantees.
Global Convergence of Over-parameterized Deep Equilibrium Models
May 27, 2022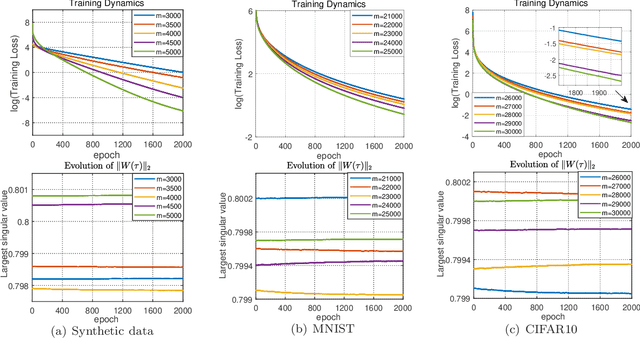
A deep equilibrium model (DEQ) is implicitly defined through an equilibrium point of an infinite-depth weight-tied model with an input-injection. Instead of infinite computations, it solves an equilibrium point directly with root-finding and computes gradients with implicit differentiation. The training dynamics of over-parameterized DEQs are investigated in this study. By supposing a condition on the initial equilibrium point, we show that the unique equilibrium point always exists during the training process, and the gradient descent is proved to converge to a globally optimal solution at a linear convergence rate for the quadratic loss function. In order to show that the required initial condition is satisfied via mild over-parameterization, we perform a fine-grained analysis on random DEQs. We propose a novel probabilistic framework to overcome the technical difficulty in the non-asymptotic analysis of infinite-depth weight-tied models.
Optimization Induced Equilibrium Networks
Jun 07, 2021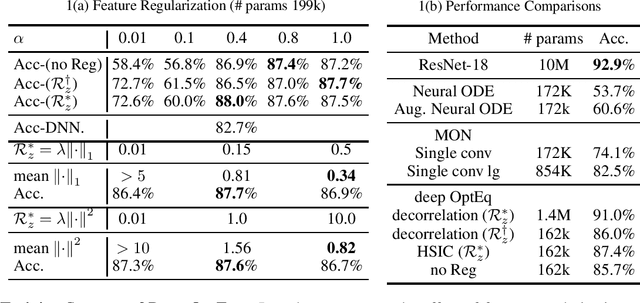


Implicit equilibrium models, i.e., deep neural networks (DNNs) defined by implicit equations, have been becoming more and more attractive recently. In this paper, we investigate an emerging question: can an implicit equilibrium model's equilibrium point be regarded as the solution of an optimization problem? To this end, we first decompose DNNs into a new class of unit layer that is the proximal operator of an implicit convex function while keeping its output unchanged. Then, the equilibrium model of the unit layer can be derived, named Optimization Induced Equilibrium Networks (OptEq), which can be easily extended to deep layers. The equilibrium point of OptEq can be theoretically connected to the solution of its corresponding convex optimization problem with explicit objectives. Based on this, we can flexibly introduce prior properties to the equilibrium points: 1) modifying the underlying convex problems explicitly so as to change the architectures of OptEq; and 2) merging the information into the fixed point iteration, which guarantees to choose the desired equilibrium point when the fixed point set is non-singleton. We show that deep OptEq outperforms previous implicit models even with fewer parameters. This work establishes the first step towards the optimization-guided design of deep models.
Implicit Normalizing Flows
Mar 17, 2021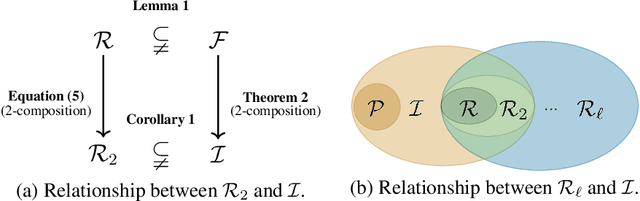
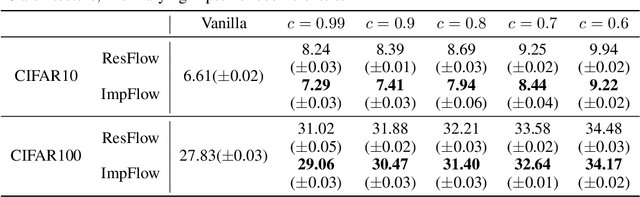
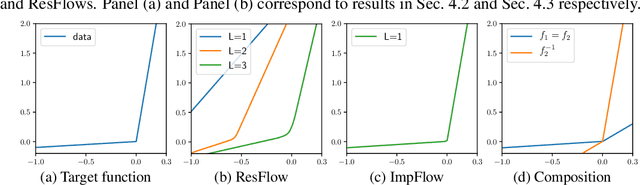
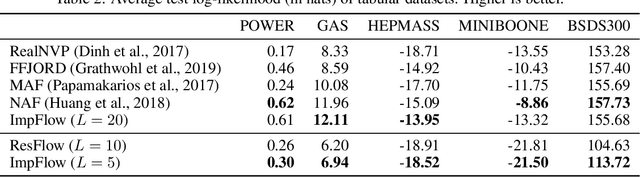
Normalizing flows define a probability distribution by an explicit invertible transformation $\boldsymbol{\mathbf{z}}=f(\boldsymbol{\mathbf{x}})$. In this work, we present implicit normalizing flows (ImpFlows), which generalize normalizing flows by allowing the mapping to be implicitly defined by the roots of an equation $F(\boldsymbol{\mathbf{z}}, \boldsymbol{\mathbf{x}})= \boldsymbol{\mathbf{0}}$. ImpFlows build on residual flows (ResFlows) with a proper balance between expressiveness and tractability. Through theoretical analysis, we show that the function space of ImpFlow is strictly richer than that of ResFlows. Furthermore, for any ResFlow with a fixed number of blocks, there exists some function that ResFlow has a non-negligible approximation error. However, the function is exactly representable by a single-block ImpFlow. We propose a scalable algorithm to train and draw samples from ImpFlows. Empirically, we evaluate ImpFlow on several classification and density modeling tasks, and ImpFlow outperforms ResFlow with a comparable amount of parameters on all the benchmarks.