 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Kinematic and Static Modeling of Cable-Driven Continuum Robots via Actuation-Space Energy Formulation
Sep 04, 2025Continuum robots, inspired by octopus arms and elephant trunks, combine dexterity with intrinsic compliance, making them well suited for unstructured and confined environments. Yet their continuously deformable morphology poses challenges for motion planning and control, calling for accurate but lightweight models. We propose the Lightweight Actuation Space Energy Modeling (LASEM) framework for cable driven continuum robots, which formulates actuation potential energy directly in actuation space. LASEM yields an analytical forward model derived from geometrically nonlinear beam and rod theories via Hamilton's principle, while avoiding explicit modeling of cable backbone contact. It accepts both force and displacement inputs, thereby unifying kinematic and static formulations. Assuming the friction is neglected, the framework generalizes to nonuniform geometries, arbitrary cable routings, distributed loading and axial extensibility, while remaining computationally efficient for real-time use. Numerical simulations validate its accuracy, and a semi-analytical iterative scheme is developed for inverse kinematics. To address discretization in practical robots, LASEM further reformulates the functional minimization as a numerical optimization, which also naturally incorporates cable potential energy without explicit contact modeling.
CycleGuardian: A Framework for Automatic RespiratorySound classification Based on Improved Deep clustering and Contrastive Learning
Feb 02, 2025Auscultation plays a pivotal role in early respiratory and pulmonary disease diagnosis. Despite the emergence of deep learning-based methods for automatic respiratory sound classification post-Covid-19, limited datasets impede performance enhancement. Distinguishing between normal and abnormal respiratory sounds poses challenges due to the coexistence of normal respiratory components and noise components in both types. Moreover, different abnormal respiratory sounds exhibit similar anomalous features, hindering their differentiation. Besides, existing state-of-the-art models suffer from excessive parameter size, impeding deployment on resource-constrained mobile platforms. To address these issues, we design a lightweight network CycleGuardian and propose a framework based on an improved deep clustering and contrastive learning. We first generate a hybrid spectrogram for feature diversity and grouping spectrograms to facilitating intermittent abnormal sound capture.Then, CycleGuardian integrates a deep clustering module with a similarity-constrained clustering component to improve the ability to capture abnormal features and a contrastive learning module with group mixing for enhanced abnormal feature discernment. Multi-objective optimization enhances overall performance during training. In experiments we use the ICBHI2017 dataset, following the official split method and without any pre-trained weights, our method achieves Sp: 82.06 $\%$, Se: 44.47$\%$, and Score: 63.26$\%$ with a network model size of 38M, comparing to the current model, our method leads by nearly 7$\%$, achieving the current best performances. Additionally, we deploy the network on Android devices, showcasing a comprehensive intelligent respiratory sound auscultation system.
Cosserat-Rod Based Dynamic Modeling of Soft Slender Robot Interacting with Environment
Jul 12, 2023Soft slender robots have attracted more and more research attentions in these years due to their continuity and compliance natures. However, mechanics modeling for soft robots interacting with environment is still an academic challenge because of the non-linearity of deformation and the non-smooth property of the contacts. In this work, starting from a piece-wise local strain field assumption, we propose a nonlinear dynamic model for soft robot via Cosserat rod theory using Newtonian mechanics which handles the frictional contact with environment and transfer them into the nonlinear complementary constraint (NCP) formulation. Moreover, we smooth both the contact and friction constraints in order to convert the inequality equations of NCP to the smooth equality equations. The proposed model allows us to compute the dynamic deformation and frictional contact force under common optimization framework in real time when the soft slender robot interacts with other rigid or soft bodies. In the end, the corresponding experiments are carried out which valid our proposed dynamic model.
Piecewise Linear Strain Cosserat Model for Soft Slender Manipulator
Jun 07, 2022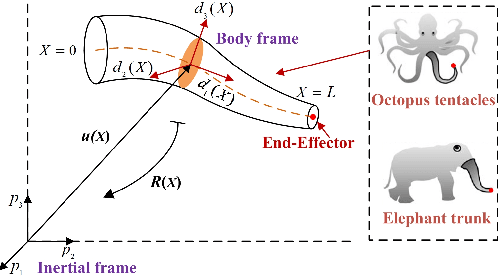
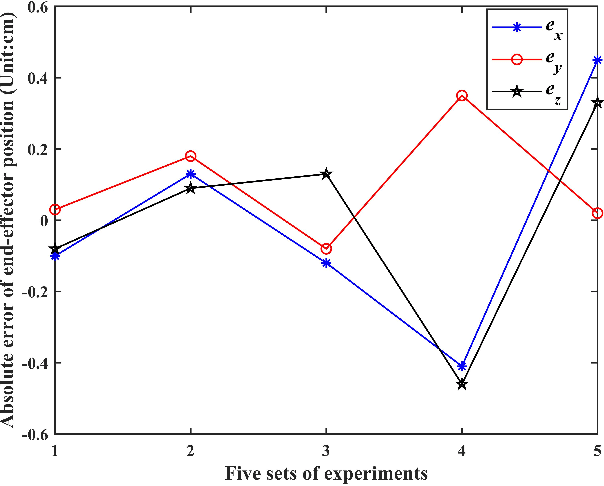
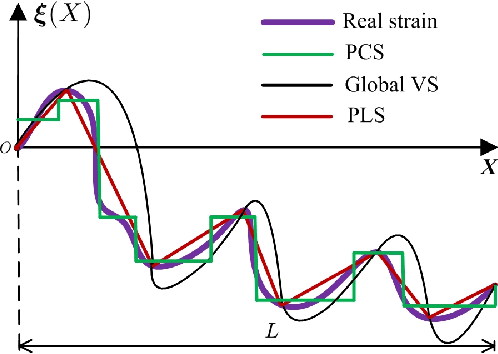
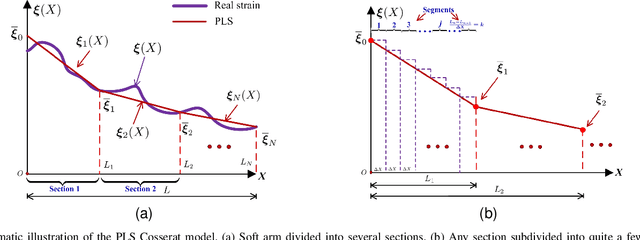
Recently soft robotics has rapidly become a novel and promising area of research with many designs and applications due to their flexible and compliant structure. However, it is more difficult to derive the nonlinear dynamic model of such soft robots. The differential kinematics and dynamics of the soft manipulator can be formulated as a set of highly nonlinear partial differential equations (PDEs) via the classic Cosserat rod theory. In this work, we propose a discrete modeling technique named piecewise linear strain (PLS) to solve the PDEs of Cosserat-based models, based on which the associated analytic models are deduced. To validate the accuracy of the proposed Cosserat model, the static model of the conical cantilever rod under gravity as a simple example is simulated by using different discretization methods. Results indicate that PLS Cosserat model is comparable to the mechanical deformation behavior of real-world soft manipulator. Finally, a parameters identification scheme for this model is established, and the simulation as well as experimental validation demonstrate that using this method can identify the model physical parameters with high accuracy.
On Convergence of Gradient Expected Sarsa($λ$)
Dec 14, 2020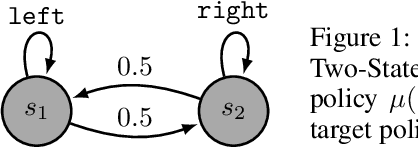
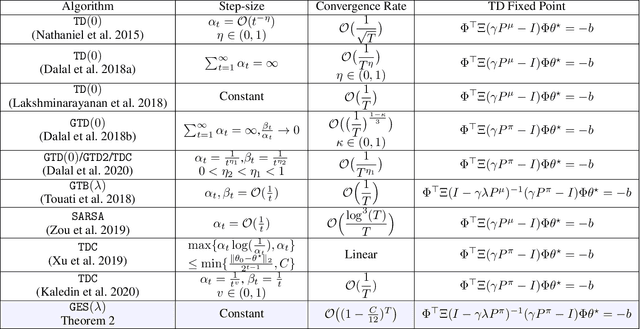
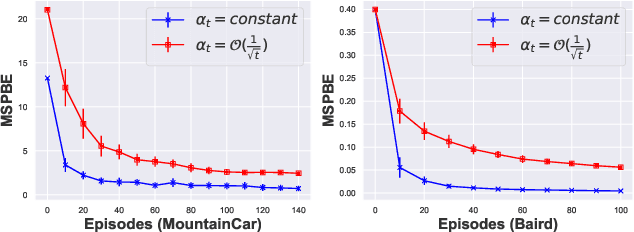
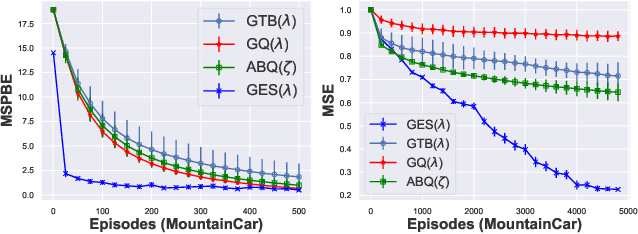
We study the convergence of $\mathtt{Expected~Sarsa}(\lambda)$ with linear function approximation. We show that applying the off-line estimate (multi-step bootstrapping) to $\mathtt{Expected~Sarsa}(\lambda)$ is unstable for off-policy learning. Furthermore, based on convex-concave saddle-point framework, we propose a convergent $\mathtt{Gradient~Expected~Sarsa}(\lambda)$ ($\mathtt{GES}(\lambda)$) algorithm. The theoretical analysis shows that our $\mathtt{GES}(\lambda)$ converges to the optimal solution at a linear convergence rate, which is comparable to extensive existing state-of-the-art gradient temporal difference learning algorithms. Furthermore, we develop a Lyapunov function technique to investigate how the step-size influences finite-time performance of $\mathtt{GES}(\lambda)$, such technique of Lyapunov function can be potentially generalized to other GTD algorithms. Finally, we conduct experiments to verify the effectiveness of our $\mathtt{GES}(\lambda)$.
FiDi-RL: Incorporating Deep Reinforcement Learning with Finite-Difference Policy Search for Efficient Learning of Continuous Control
Jul 10, 2019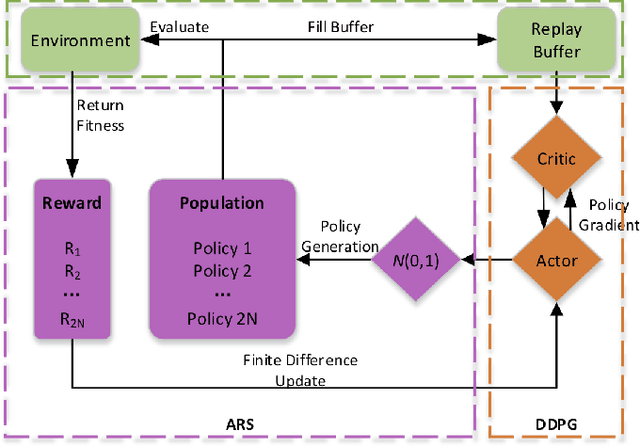
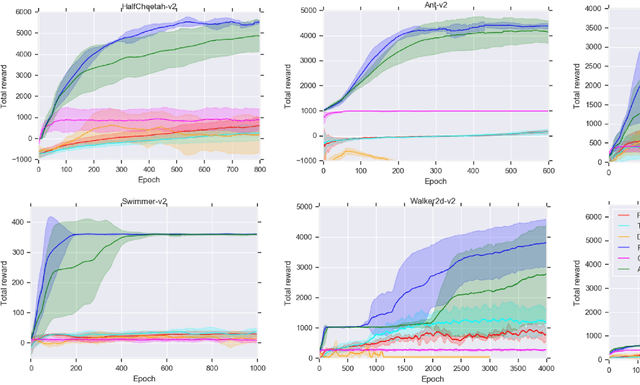
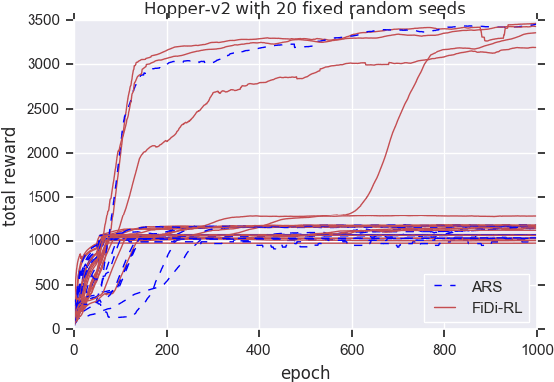
In recent years significant progress has been made in dealing with challenging problems using reinforcement learning.Despite its great success, reinforcement learning still faces challenge in continuous control tasks. Conventional methods always compute the derivatives of the optimal goal with a costly computation resources, and are inefficient, unstable and lack of robust-ness when dealing with such tasks. Alternatively, derivative-based methods treat the optimization process as a blackbox and show robustness and stability in learning continuous control tasks, but not data efficient in learning. The combination of both methods so as to get the best of the both has raised attention. However, most of the existing combination works adopt complex neural networks (NNs) as the policy for control. The double-edged sword of deep NNs can yield better performance, but also makes it difficult for parameter tuning and computation. To this end, in this paper we presents a novel method called FiDi-RL, which incorporates deep RL with Finite-Difference (FiDi) policy search.FiDi-RL combines Deep Deterministic Policy Gradients (DDPG)with Augment Random Search (ARS) and aims at improving the data efficiency of ARS. The empirical results show that FiDi-RL can improves the performance and stability of ARS, and provide competitive results against some existing deep reinforcement learning methods
Focusing Attention: Towards Accurate Text Recognition in Natural Images
Oct 17, 2017
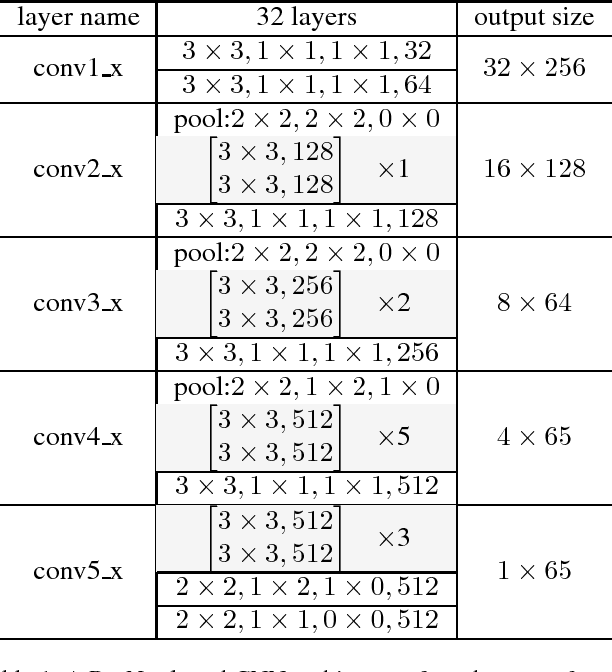
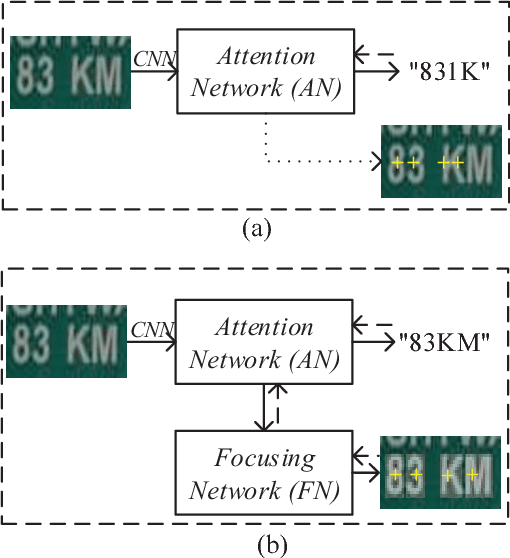
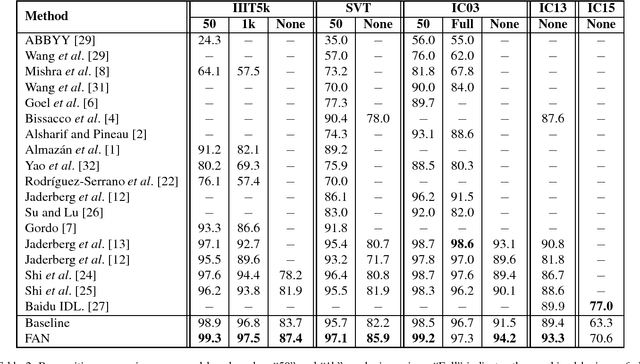
Scene text recognition has been a hot research topic in computer vision due to its various applications. The state of the art is the attention-based encoder-decoder framework that learns the mapping between input images and output sequences in a purely data-driven way. However, we observe that existing attention-based methods perform poorly on complicated and/or low-quality images. One major reason is that existing methods cannot get accurate alignments between feature areas and targets for such images. We call this phenomenon "attention drift". To tackle this problem, in this paper we propose the FAN (the abbreviation of Focusing Attention Network) method that employs a focusing attention mechanism to automatically draw back the drifted attention. FAN consists of two major components: an attention network (AN) that is responsible for recognizing character targets as in the existing methods, and a focusing network (FN) that is responsible for adjusting attention by evaluating whether AN pays attention properly on the target areas in the images. Furthermore, different from the existing methods, we adopt a ResNet-based network to enrich deep representations of scene text images. Extensive experiments on various benchmarks, including the IIIT5k, SVT and ICDAR datasets, show that the FAN method substantially outperforms the existing methods.