 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoBrain: Continual Learning of EEG Foundation Models Across Heterogeneous BCI Tasks
Jun 01, 2026Electroencephalography (EEG) is the cornerstone of non-invasive brain-computer interfaces (BCIs), yet conventional decoding relies on fragmented, task-specific architectures that severely limit cross-task scalability. While EEG foundation models pre-trained on massive corpora promise universal brain decoding, current post-training depends on task-isolated fine-tuning. This static paradigm restricts knowledge transfer across heterogeneous tasks, hinders model scalability, and incurs computational and storage overheads that scale linearly with task count. To overcome these bottlenecks, we formulate downstream adaptation as a cross-task continual learning problem and propose EvoBrain, a dynamic, task-aware continual learning framework for unified EEG decoding. EvoBrain addresses the plasticity-stability trade-off via two complementary components: (1) Neuro-Spectral Task Normalization (NSN) aligns incoming tasks with historical statistics while recalibrating spectral responses to handle distributional and neuro-spectral shifts; and (2) Response-Affinity Distillation (RAD), combined with time-dependent replay, preserves old-task response geometry and promotes selective knowledge transfer between spectrally compatible tasks, effectively mitigating forgetting. Extensive evaluations across six distinct BCI tasks demonstrate that EvoBrain consistently surpasses state-of-the-art methods across diverse foundation backbones, optimally balancing plasticity and stability. To our knowledge, this work pioneers cross-task continual learning in the EEG domain, advancing the realization of a unified, one-for-all brain decoding system.
FairJudge: An Adaptive, Debiased, and Consistent LLM-as-a-Judge
Feb 06, 2026Existing LLM-as-a-Judge systems suffer from three fundamental limitations: limited adaptivity to task- and domain-specific evaluation criteria, systematic biases driven by non-semantic cues such as position, length, format, and model provenance, and evaluation inconsistency that leads to contradictory judgments across different evaluation modes (e.g., pointwise versus pairwise). To address these issues, we propose FairJudge, an adaptive, debiased, and consistent LLM-as-a-Judge. Unlike prior approaches that treat the judge as a static evaluator, FairJudge models judging behavior itself as a learnable and regularized policy. From a data-centric perspective, we construct a high-information-density judging dataset that explicitly injects supervision signals aligned with evaluation behavior. Building on this dataset, we adopt a curriculum-style SFT-DPO-GRPO training paradigm that progressively aligns rubric adherence, bias mitigation, and cross-mode consistency, while avoiding catastrophic forgetting. Experimental results on multiple internal and public benchmarks show that FairJudge consistently improves agreement and F1, reduces non-semantic biases, and outperforms substantially larger instruction-tuned LLMs. All resources will be publicly released after acceptance to facilitate future research.
ZPD Detector: Data Selection via Capability-Difficulty Alignment for Large Language Models
Jan 16, 2026As the cost of training large language models continues to increase and high-quality training data become increasingly scarce, selecting high-value samples or synthesizing effective training data under limited data budgets has emerged as a critical research problem. Most existing data selection methods rely on static criteria, such as difficulty, uncertainty, or heuristics, and fail to model the evolving relationship between the model and the data. Inspired by the educational theory of the Zone of Proximal Development (ZPD), we propose ZPD Detector, a data selection framework that adopts a bidirectional perspective between models and data by explicitly modeling the alignment between sample difficulty and the model's current capability. ZPD Detector integrates difficulty calibration, model capability estimation based on Item Response Theory (IRT), and a capability-difficulty matching score to dynamically identify the most informative samples at each learning stage, improving data utilization efficiency; moreover, this dynamic matching strategy provides new insights into training strategy design. All code and data will be released after our work be accepted to support reproducible researc
AgriAgent: Contract-Driven Planning and Capability-Aware Tool Orchestration in Real-World Agriculture
Jan 13, 2026Intelligent agent systems in real-world agricultural scenarios must handle diverse tasks under multimodal inputs, ranging from lightweight information understanding to complex multi-step execution. However, most existing approaches rely on a unified execution paradigm, which struggles to accommodate large variations in task complexity and incomplete tool availability commonly observed in agricultural environments. To address this challenge, we propose AgriAgent, a two-level agent framework for real-world agriculture. AgriAgent adopts a hierarchical execution strategy based on task complexity: simple tasks are handled through direct reasoning by modality-specific agents, while complex tasks trigger a contract-driven planning mechanism that formulates tasks as capability requirements and performs capability-aware tool orchestration and dynamic tool generation, enabling multi-step and verifiable execution with failure recovery. Experimental results show that AgriAgent achieves higher execution success rates and robustness on complex tasks compared to existing tool-centric agent baselines that rely on unified execution paradigms. All code, data will be released at after our work be accepted to promote reproducible research.
AgriGPT-Omni: A Unified Speech-Vision-Text Framework for Multilingual Agricultural Intelligence
Dec 11, 2025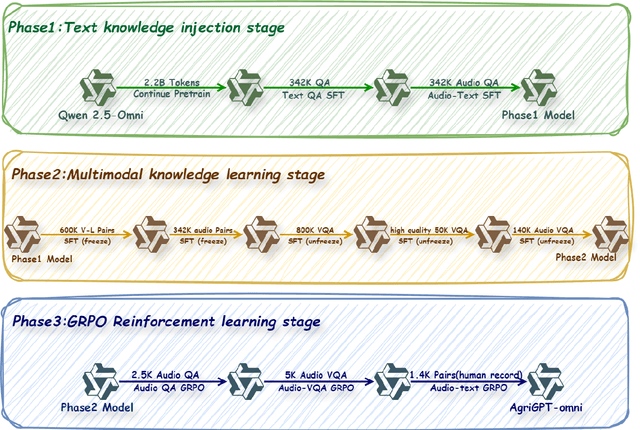
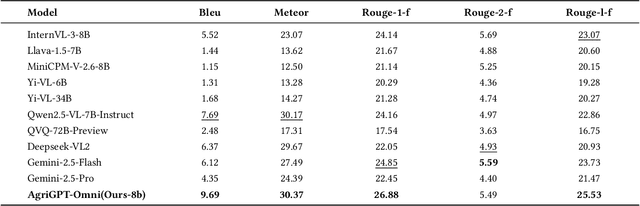
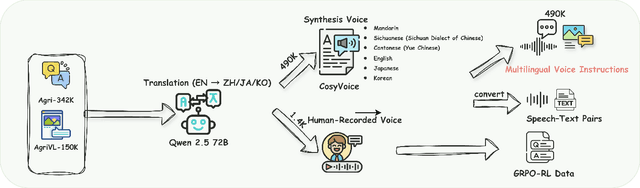
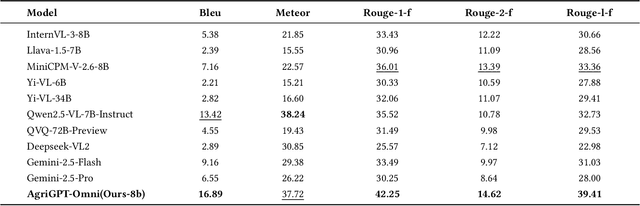
Despite rapid advances in multimodal large language models, agricultural applications remain constrained by the lack of multilingual speech data, unified multimodal architectures, and comprehensive evaluation benchmarks. To address these challenges, we present AgriGPT-Omni, an agricultural omni-framework that integrates speech, vision, and text in a unified framework. First, we construct a scalable data synthesis and collection pipeline that converts agricultural texts and images into training data, resulting in the largest agricultural speech dataset to date, including 492K synthetic and 1.4K real speech samples across six languages. Second, based on this, we train the first agricultural omni-model via a three-stage paradigm: textual knowledge injection, progressive multimodal alignment, and GRPO-based reinforcement learning, enabling unified reasoning across languages and modalities. Third, we propose AgriBench-Omni-2K, the first tri-modal benchmark for agriculture, covering diverse speech-vision-text tasks and multilingual slices, with standardized protocols and reproducible tools. Experiments show that AgriGPT-Omni significantly outperforms general-purpose baselines on multilingual and multimodal reasoning as well as real-world speech understanding. All models, data, benchmarks, and code will be released to promote reproducible research, inclusive agricultural intelligence, and sustainable AI development for low-resource regions.
From Low-Rank Features to Encoding Mismatch: Rethinking Feature Distillation in Vision Transformers
Nov 19, 2025Feature-map knowledge distillation (KD) is highly effective for convolutional networks but often fails for Vision Transformers (ViTs). To understand this failure and guide method design, we conduct a two-view representation analysis of ViTs. First, a layer-wise Singular Value Decomposition (SVD) of full feature matrices shows that final-layer representations are globally low-rank: for CaiT-S24, only $121/61/34/14$ dimensions suffice to capture $99\%/95\%/90\%/80\%$ of the energy. In principle, this suggests that a compact student plus a simple linear projector should be enough for feature alignment, contradicting the weak empirical performance of standard feature KD. To resolve this paradox, we introduce a token-level Spectral Energy Pattern (SEP) analysis that measures how each token uses channel capacity. SEP reveals that, despite the global low-rank structure, individual tokens distribute energy over most channels, forming a high-bandwidth encoding pattern. This results in an encoding mismatch between wide teachers and narrow students. Motivated by this insight, we propose two minimal, mismatch-driven strategies: (1) post-hoc feature lifting with a lightweight projector retained during inference, or (2) native width alignment that widens only the student's last block to the teacher's width. On ImageNet-1K, these strategies reactivate simple feature-map distillation in ViTs, raising DeiT-Tiny accuracy from $74.86\%$ to $77.53\%$ and $78.23\%$ when distilling from CaiT-S24, while also improving standalone students trained without any teacher. Our analysis thus explains why ViT feature distillation fails and shows how exploiting low-rank structure yields effective, interpretable remedies and concrete design guidance for compact ViTs.
Distillation Dynamics: Towards Understanding Feature-Based Distillation in Vision Transformers
Nov 15, 2025While feature-based knowledge distillation has proven highly effective for compressing CNNs, these techniques unexpectedly fail when applied to Vision Transformers (ViTs), often performing worse than simple logit-based distillation. We provide the first comprehensive analysis of this phenomenon through a novel analytical framework termed as "distillation dynamics", combining frequency spectrum analysis, information entropy metrics, and activation magnitude tracking. Our investigation reveals that ViTs exhibit a distinctive U-shaped information processing pattern: initial compression followed by expansion. We identify the root cause of negative transfer in feature distillation: a fundamental representational paradigm mismatch between teacher and student models. Through frequency-domain analysis, we show that teacher models employ distributed, high-dimensional encoding strategies in later layers that smaller student models cannot replicate due to limited channel capacity. This mismatch causes late-layer feature alignment to actively harm student performance. Our findings reveal that successful knowledge transfer in ViTs requires moving beyond naive feature mimicry to methods that respect these fundamental representational constraints, providing essential theoretical guidance for designing effective ViTs compression strategies. All source code and experimental logs are provided at https://github.com/thy960112/Distillation-Dynamics.
EMOD: A Unified EEG Emotion Representation Framework Leveraging V-A Guided Contrastive Learning
Nov 14, 2025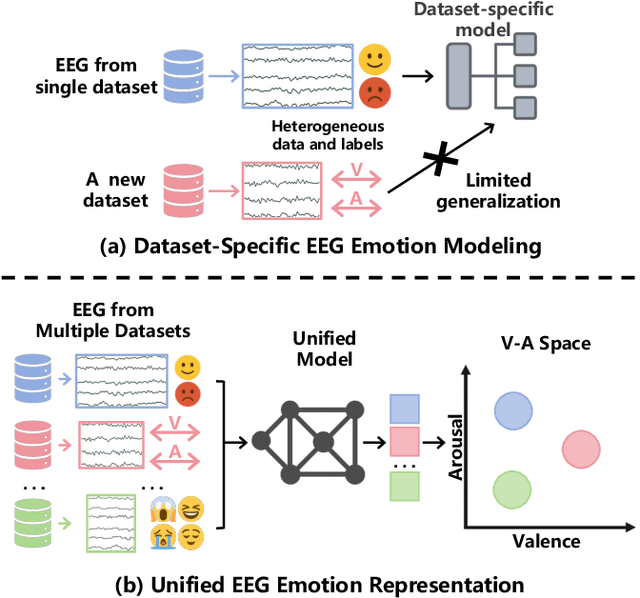



Emotion recognition from EEG signals is essential for affective computing and has been widely explored using deep learning. While recent deep learning approaches have achieved strong performance on single EEG emotion datasets, their generalization across datasets remains limited due to the heterogeneity in annotation schemes and data formats. Existing models typically require dataset-specific architectures tailored to input structure and lack semantic alignment across diverse emotion labels. To address these challenges, we propose EMOD: A Unified EEG Emotion Representation Framework Leveraging Valence-Arousal (V-A) Guided Contrastive Learning. EMOD learns transferable and emotion-aware representations from heterogeneous datasets by bridging both semantic and structural gaps. Specifically, we project discrete and continuous emotion labels into a unified V-A space and formulate a soft-weighted supervised contrastive loss that encourages emotionally similar samples to cluster in the latent space. To accommodate variable EEG formats, EMOD employs a flexible backbone comprising a Triple-Domain Encoder followed by a Spatial-Temporal Transformer, enabling robust extraction and integration of temporal, spectral, and spatial features. We pretrain EMOD on 8 public EEG datasets and evaluate its performance on three benchmark datasets. Experimental results show that EMOD achieves the state-of-the-art performance, demonstrating strong adaptability and generalization across diverse EEG-based emotion recognition scenarios.
EEGAgent: A Unified Framework for Automated EEG Analysis Using Large Language Models
Nov 13, 2025Scalable and generalizable analysis of brain activity is essential for advancing both clinical diagnostics and cognitive research. Electroencephalography (EEG), a non-invasive modality with high temporal resolution, has been widely used for brain states analysis. However, most existing EEG models are usually tailored for individual specific tasks, limiting their utility in realistic scenarios where EEG analysis often involves multi-task and continuous reasoning. In this work, we introduce EEGAgent, a general-purpose framework that leverages large language models (LLMs) to schedule and plan multiple tools to automatically complete EEG-related tasks. EEGAgent is capable of performing the key functions: EEG basic information perception, spatiotemporal EEG exploration, EEG event detection, interaction with users, and EEG report generation. To realize these capabilities, we design a toolbox composed of different tools for EEG preprocessing, feature extraction, event detection, etc. These capabilities were evaluated on public datasets, and our EEGAgent can support flexible and interpretable EEG analysis, highlighting its potential for real-world clinical applications.
Kunlun Anomaly Troubleshooter: Enabling Kernel-Level Anomaly Detection and Causal Reasoning for Large Model Distributed Inference
Nov 08, 2025Anomaly troubleshooting for large model distributed inference (LMDI) remains a critical challenge. Resolving anomalies such as inference performance degradation or latency jitter in distributed system demands significant manual efforts from domain experts, resulting in extremely time-consuming diagnosis processes with relatively low accuracy. In this paper, we introduce Kunlun Anomaly Troubleshooter (KAT), the first anomaly troubleshooting framework tailored for LMDI. KAT addresses this problem through two core innovations. First, KAT exploits the synchronicity and consistency of GPU workers, innovatively leverages function trace data to precisely detect kernel-level anomalies and associated hardware components at nanosecond resolution. Second, KAT integrates these detection results into a domain-adapted LLM, delivering systematic causal reasoning and natural language interpretation of complex anomaly symptoms. Evaluations conducted in Alibaba Cloud Service production environment indicate that KAT achieves over 0.884 precision and 0.936 recall in anomaly detection, providing detail anomaly insights that significantly narrow down the diagnostic scope and improve both the efficiency and success rate of troubleshooting.