 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDuo: Universal Dual Optimization Framework for Online Matching
May 28, 2025Online resource allocation under budget constraints critically depends on proper modeling of user arrival dynamics. Classical approaches employ stochastic user arrival models to derive near-optimal solutions through fractional matching formulations of exposed users for downstream allocation tasks. However, this is no longer a reasonable assumption when the environment changes dynamically. In this work, We propose the Universal Dual optimization framework UDuo, a novel paradigm that fundamentally rethinks online allocation through three key innovations: (i) a temporal user arrival representation vector that explicitly captures distribution shifts in user arrival patterns and resource consumption dynamics, (ii) a resource pacing learner with adaptive allocation policies that generalize to heterogeneous constraint scenarios, and (iii) an online time-series forecasting approach for future user arrival distributions that achieves asymptotically optimal solutions with constraint feasibility guarantees in dynamic environments. Experimental results show that UDuo achieves higher efficiency and faster convergence than the traditional stochastic arrival model in real-world pricing while maintaining rigorous theoretical validity for general online allocation problems.
FairRec: Fairness Testing for Deep Recommender Systems
Apr 14, 2023



Deep learning-based recommender systems (DRSs) are increasingly and widely deployed in the industry, which brings significant convenience to people's daily life in different ways. However, recommender systems are also shown to suffer from multiple issues,e.g., the echo chamber and the Matthew effect, of which the notation of "fairness" plays a core role.While many fairness notations and corresponding fairness testing approaches have been developed for traditional deep classification models, they are essentially hardly applicable to DRSs. One major difficulty is that there still lacks a systematic understanding and mapping between the existing fairness notations and the diverse testing requirements for deep recommender systems, not to mention further testing or debugging activities. To address the gap, we propose FairRec, a unified framework that supports fairness testing of DRSs from multiple customized perspectives, e.g., model utility, item diversity, item popularity, etc. We also propose a novel, efficient search-based testing approach to tackle the new challenge, i.e., double-ended discrete particle swarm optimization (DPSO) algorithm, to effectively search for hidden fairness issues in the form of certain disadvantaged groups from a vast number of candidate groups. Given the testing report, by adopting a simple re-ranking mitigation strategy on these identified disadvantaged groups, we show that the fairness of DRSs can be significantly improved. We conducted extensive experiments on multiple industry-level DRSs adopted by leading companies. The results confirm that FairRec is effective and efficient in identifying the deeply hidden fairness issues, e.g., achieving 95% testing accuracy with half to 1/8 time.
Thompson Sampling for Unimodal Bandits
Jun 16, 2021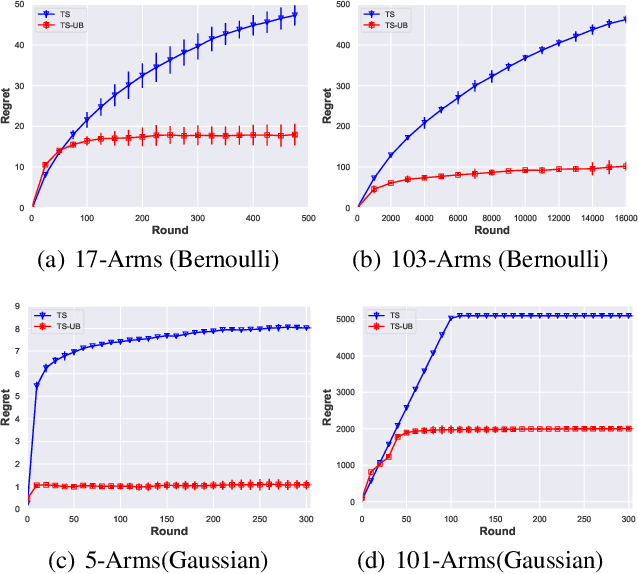
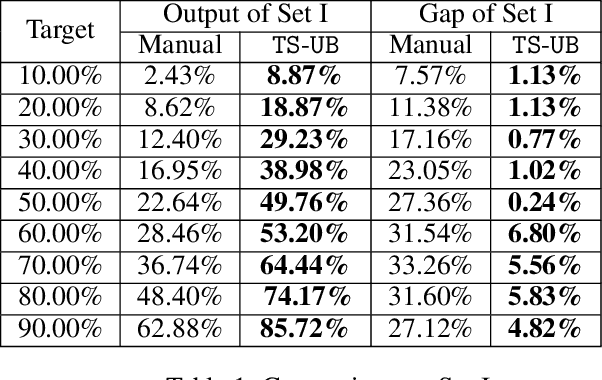
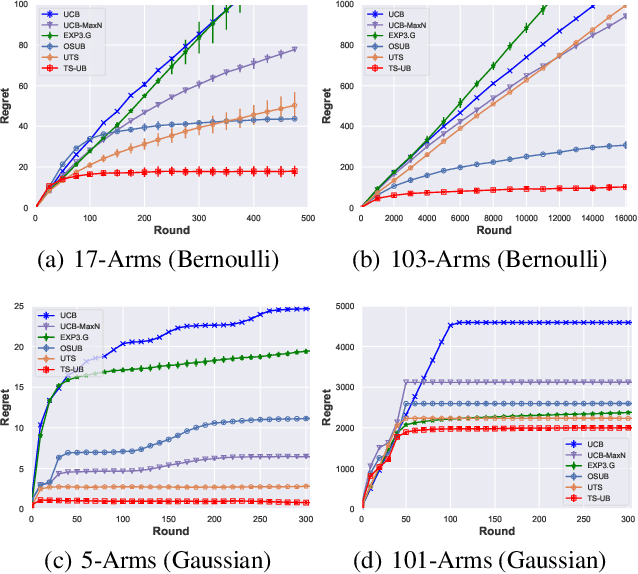
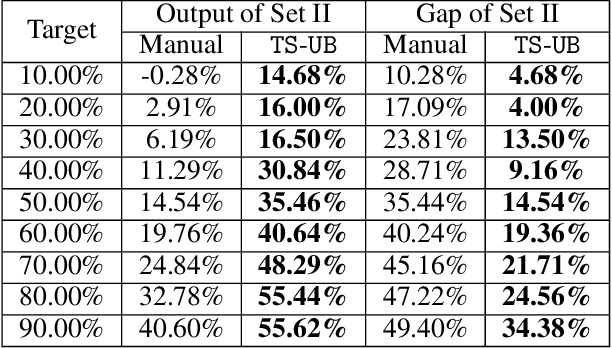
In this paper, we propose a Thompson Sampling algorithm for \emph{unimodal} bandits, where the expected reward is unimodal over the partially ordered arms. To exploit the unimodal structure better, at each step, instead of exploration from the entire decision space, our algorithm makes decision according to posterior distribution only in the neighborhood of the arm that has the highest empirical mean estimate. We theoretically prove that, for Bernoulli rewards, the regret of our algorithm reaches the lower bound of unimodal bandits, thus it is asymptotically optimal. For Gaussian rewards, the regret of our algorithm is $\mathcal{O}(\log T)$, which is far better than standard Thompson Sampling algorithms. Extensive experiments demonstrate the effectiveness of the proposed algorithm on both synthetic data sets and the real-world applications.
Which Channel to Ask My Question? Personalized Customer Service RequestStream Routing using DeepReinforcement Learning
Nov 24, 2019
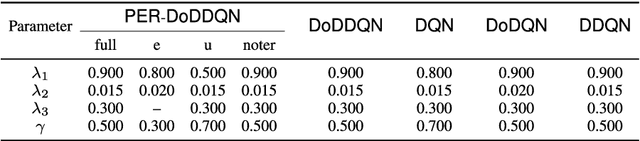

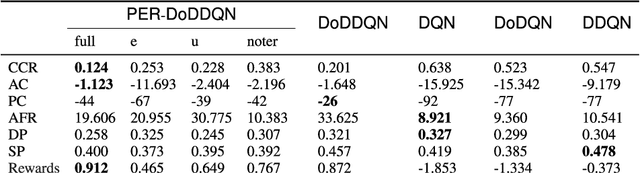
Customer services are critical to all companies, as they may directly connect to the brand reputation. Due to a great number of customers, e-commerce companies often employ multiple communication channels to answer customers' questions, for example, chatbot and hotline. On one hand, each channel has limited capacity to respond to customers' requests, on the other hand, customers have different preferences over these channels. The current production systems are mainly built based on business rules, which merely considers tradeoffs between resources and customers' satisfaction. To achieve the optimal tradeoff between resources and customers' satisfaction, we propose a new framework based on deep reinforcement learning, which directly takes both resources and user model into account. In addition to the framework, we also propose a new deep-reinforcement-learning based routing method-double dueling deep Q-learning with prioritized experience replay (PER-DoDDQN). We evaluate our proposed framework and method using both synthetic and a real customer service log data from a large financial technology company. We show that our proposed deep-reinforcement-learning based framework is superior to the existing production system. Moreover, we also show our proposed PER-DoDDQN is better than all other deep Q-learning variants in practice, which provides a more optimal routing plan. These observations suggest that our proposed method can seek the trade-off where both channel resources and customers' satisfaction are optimal.
Artificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
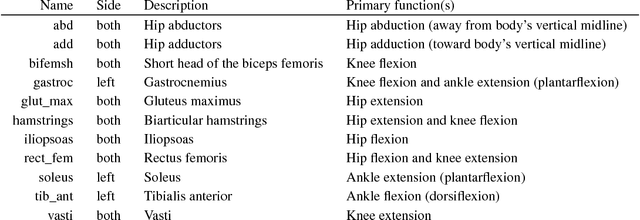
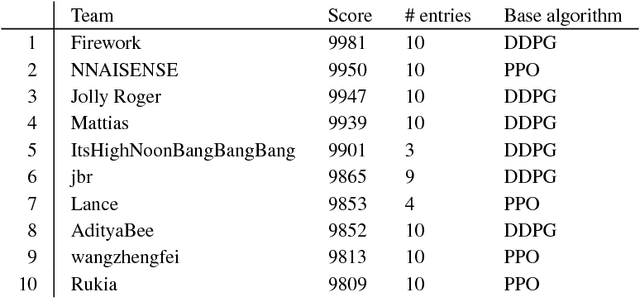

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Inference Aided Reinforcement Learning for Incentive Mechanism Design in Crowdsourcing
Jun 01, 2018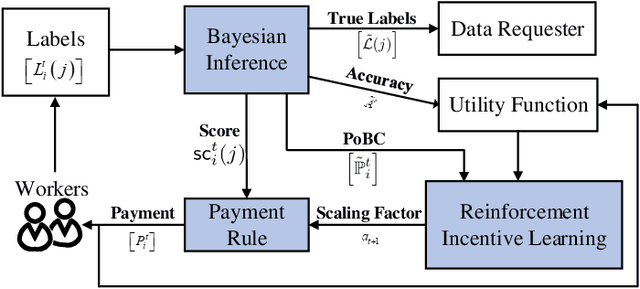
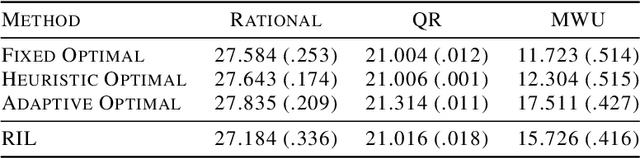
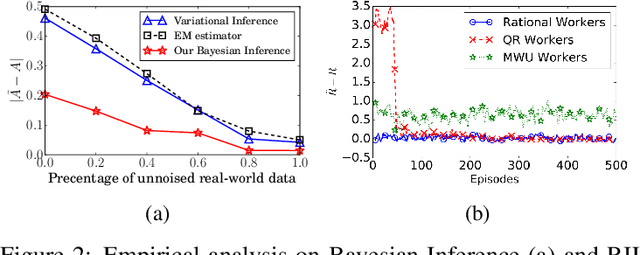
Incentive mechanisms for crowdsourcing are designed to incentivize financially self-interested workers to generate and report high-quality labels. Existing mechanisms are often developed as one-shot static solutions, assuming a certain level of knowledge about worker models (expertise levels, costs of exerting efforts, etc.). In this paper, we propose a novel inference aided reinforcement mechanism that learns to incentivize high-quality data sequentially and requires no such prior assumptions. Specifically, we first design a Gibbs sampling augmented Bayesian inference algorithm to estimate workers' labeling strategies from the collected labels at each step. Then we propose a reinforcement incentive learning (RIL) method, building on top of the above estimates, to uncover how workers respond to different payments. RIL dynamically determines the payment without accessing any ground-truth labels. We theoretically prove that RIL is able to incentivize rational workers to provide high-quality labels. Empirical results show that our mechanism performs consistently well under both rational and non-fully rational (adaptive learning) worker models. Besides, the payments offered by RIL are more robust and have lower variances compared to the existing one-shot mechanisms.