 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM: Drafting with Refined Target Features and Entropy-Adaptive Cross-Attention Fusion for Multimodal Speculative Decoding
May 25, 2025Speculative decoding (SD) has emerged as a powerful method for accelerating autoregressive generation in large language models (LLMs), yet its integration into vision-language models (VLMs) remains underexplored. We introduce DREAM, a novel speculative decoding framework tailored for VLMs that combines three key innovations: (1) a cross-attention-based mechanism to inject intermediate features from the target model into the draft model for improved alignment, (2) adaptive intermediate feature selection based on attention entropy to guide efficient draft model training, and (3) visual token compression to reduce draft model latency. DREAM enables efficient, accurate, and parallel multimodal decoding with significant throughput improvement. Experiments across a diverse set of recent popular VLMs, including LLaVA, Pixtral, SmolVLM and Gemma3, demonstrate up to 3.6x speedup over conventional decoding and significantly outperform prior SD baselines in both inference throughput and speculative draft acceptance length across a broad range of multimodal benchmarks. The code is publicly available at: https://github.com/SAI-Lab-NYU/DREAM.git
PipeSpec: Breaking Stage Dependencies in Hierarchical LLM Decoding
May 02, 2025Speculative decoding accelerates large language model inference by using smaller draft models to generate candidate tokens for parallel verification. However, current approaches are limited by sequential stage dependencies that prevent full hardware utilization. We present PipeSpec, a framework that generalizes speculative decoding to $k$ models arranged in a hierarchical pipeline, enabling asynchronous execution with lightweight coordination for prediction verification and rollback. Our analytical model characterizes token generation rates across pipeline stages and proves guaranteed throughput improvements over traditional decoding for any non-zero acceptance rate. We further derive closed-form expressions for steady-state verification probabilities that explain the empirical benefits of pipeline depth. Experimental results show that PipeSpec achieves up to 2.54$\times$ speedup while outperforming state-of-the-art methods. We validate PipeSpec across text summarization and code generation tasks using LLaMA 2 and 3 models, demonstrating that pipeline efficiency increases with model depth, providing a scalable approach to accelerating LLM inference on multi-device systems.
Speculative Decoding and Beyond: An In-Depth Review of Techniques
Feb 27, 2025Sequential dependencies present a fundamental bottleneck in deploying large-scale autoregressive models, particularly for real-time applications. While traditional optimization approaches like pruning and quantization often compromise model quality, recent advances in generation-refinement frameworks demonstrate that this trade-off can be significantly mitigated. This survey presents a comprehensive taxonomy of generation-refinement frameworks, analyzing methods across autoregressive sequence tasks. We categorize methods based on their generation strategies (from simple n-gram prediction to sophisticated draft models) and refinement mechanisms (including single-pass verification and iterative approaches). Through systematic analysis of both algorithmic innovations and system-level implementations, we examine deployment strategies across computing environments and explore applications spanning text, images, and speech generation. This systematic examination of both theoretical frameworks and practical implementations provides a foundation for future research in efficient autoregressive decoding.
Which Channel to Ask My Question? Personalized Customer Service RequestStream Routing using DeepReinforcement Learning
Nov 24, 2019
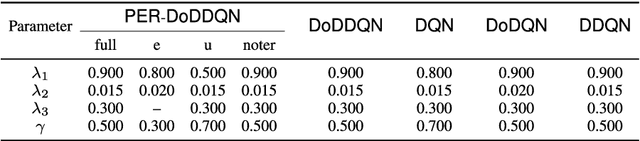

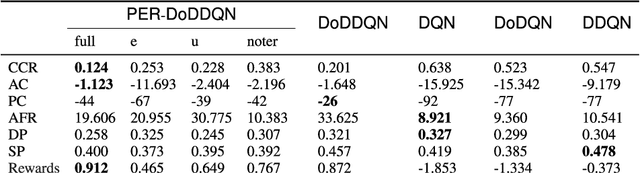
Customer services are critical to all companies, as they may directly connect to the brand reputation. Due to a great number of customers, e-commerce companies often employ multiple communication channels to answer customers' questions, for example, chatbot and hotline. On one hand, each channel has limited capacity to respond to customers' requests, on the other hand, customers have different preferences over these channels. The current production systems are mainly built based on business rules, which merely considers tradeoffs between resources and customers' satisfaction. To achieve the optimal tradeoff between resources and customers' satisfaction, we propose a new framework based on deep reinforcement learning, which directly takes both resources and user model into account. In addition to the framework, we also propose a new deep-reinforcement-learning based routing method-double dueling deep Q-learning with prioritized experience replay (PER-DoDDQN). We evaluate our proposed framework and method using both synthetic and a real customer service log data from a large financial technology company. We show that our proposed deep-reinforcement-learning based framework is superior to the existing production system. Moreover, we also show our proposed PER-DoDDQN is better than all other deep Q-learning variants in practice, which provides a more optimal routing plan. These observations suggest that our proposed method can seek the trade-off where both channel resources and customers' satisfaction are optimal.