 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Correction Distillation for Structured Data Question Answering
Nov 17, 2025Structured data question answering (QA), including table QA, Knowledge Graph (KG) QA, and temporal KG QA, is a pivotal research area. Advances in large language models (LLMs) have driven significant progress in unified structural QA frameworks like TrustUQA. However, these frameworks face challenges when applied to small-scale LLMs since small-scale LLMs are prone to errors in generating structured queries. To improve the structured data QA ability of small-scale LLMs, we propose a self-correction distillation (SCD) method. In SCD, an error prompt mechanism (EPM) is designed to detect errors and provide customized error messages during inference, and a two-stage distillation strategy is designed to transfer large-scale LLMs' query-generation and error-correction capabilities to small-scale LLM. Experiments across 5 benchmarks with 3 structured data types demonstrate that our SCD achieves the best performance and superior generalization on small-scale LLM (8B) compared to other distillation methods, and closely approaches the performance of GPT4 on some datasets. Furthermore, large-scale LLMs equipped with EPM surpass the state-of-the-art results on most datasets.
Leveraging Knowledge Graph Embedding for Effective Conversational Recommendation
Aug 02, 2024



Conversational recommender system (CRS), which combines the techniques of dialogue system and recommender system, has obtained increasing interest recently. In contrast to traditional recommender system, it learns the user preference better through interactions (i.e. conversations), and then further boosts the recommendation performance. However, existing studies on CRS ignore to address the relationship among attributes, users, and items effectively, which might lead to inappropriate questions and inaccurate recommendations. In this view, we propose a knowledge graph based conversational recommender system (referred as KG-CRS). Specifically, we first integrate the user-item graph and item-attribute graph into a dynamic graph, i.e., dynamically changing during the dialogue process by removing negative items or attributes. We then learn informative embedding of users, items, and attributes by also considering propagation through neighbors on the graph. Extensive experiments on three real datasets validate the superiority of our method over the state-of-the-art approaches in terms of both the recommendation and conversation tasks.
SafetyBench: Evaluating the Safety of Large Language Models with Multiple Choice Questions
Sep 13, 2023



With the rapid development of Large Language Models (LLMs), increasing attention has been paid to their safety concerns. Consequently, evaluating the safety of LLMs has become an essential task for facilitating the broad applications of LLMs. Nevertheless, the absence of comprehensive safety evaluation benchmarks poses a significant impediment to effectively assess and enhance the safety of LLMs. In this work, we present SafetyBench, a comprehensive benchmark for evaluating the safety of LLMs, which comprises 11,435 diverse multiple choice questions spanning across 7 distinct categories of safety concerns. Notably, SafetyBench also incorporates both Chinese and English data, facilitating the evaluation in both languages. Our extensive tests over 25 popular Chinese and English LLMs in both zero-shot and few-shot settings reveal a substantial performance advantage for GPT-4 over its counterparts, and there is still significant room for improving the safety of current LLMs. We believe SafetyBench will enable fast and comprehensive evaluation of LLMs' safety, and foster the development of safer LLMs. Data and evaluation guidelines are available at https://github.com/thu-coai/SafetyBench. Submission entrance and leaderboard are available at https://llmbench.ai/safety.
DAN: Dual-View Representation Learning for Adapting Stance Classifiers to New Domains
Mar 13, 2020
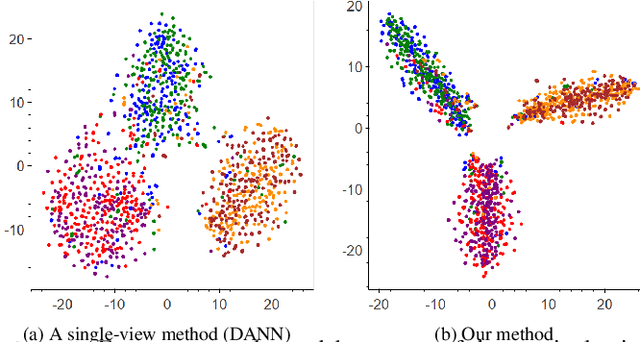
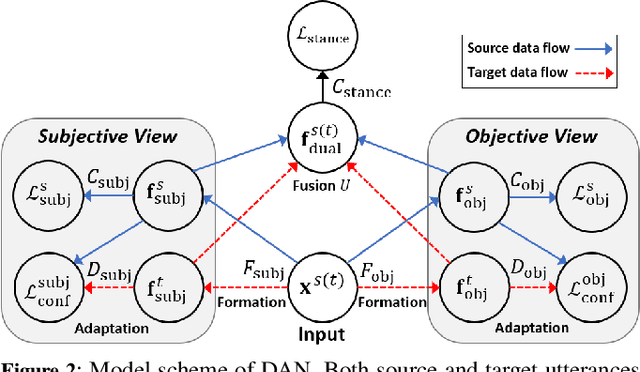
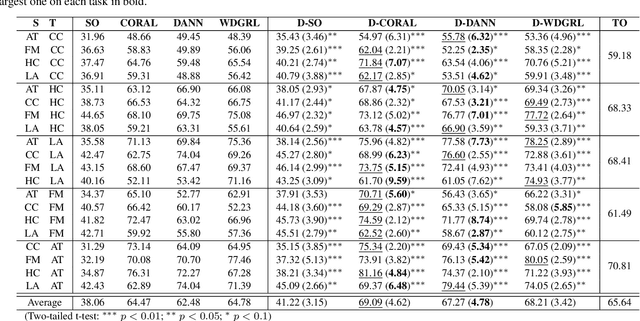
We address the issue of having a limited number of annotations for stance classification in a new domain, by adapting out-of-domain classifiers with domain adaptation. Existing approaches often align different domains in a single, global feature space (or view), which may fail to fully capture the richness of the languages used for expressing stances, leading to reduced adaptability on stance data. In this paper, we identify two major types of stance expressions that are linguistically distinct, and we propose a tailored dual-view adaptation network (DAN) to adapt these expressions across domains. The proposed model first learns a separate view for domain transfer in each expression channel and then selects the best adapted parts of both views for optimal transfer. We find that the learned view features can be more easily aligned and more stance-discriminative in either or both views, leading to more transferable overall features after combining the views. Results from extensive experiments show that our method can enhance the state-of-the-art single-view methods in matching stance data across different domains, and that it consistently improves those methods on various adaptation tasks.
Which Channel to Ask My Question? Personalized Customer Service RequestStream Routing using DeepReinforcement Learning
Nov 24, 2019
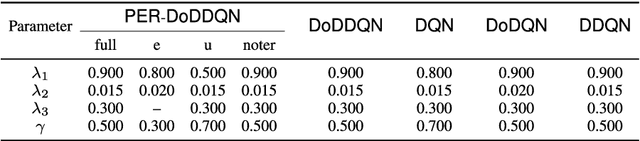

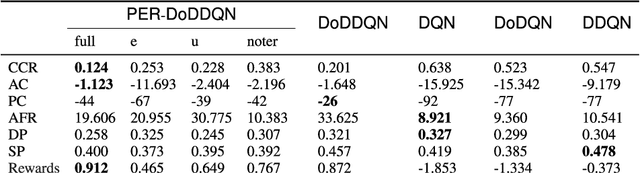
Customer services are critical to all companies, as they may directly connect to the brand reputation. Due to a great number of customers, e-commerce companies often employ multiple communication channels to answer customers' questions, for example, chatbot and hotline. On one hand, each channel has limited capacity to respond to customers' requests, on the other hand, customers have different preferences over these channels. The current production systems are mainly built based on business rules, which merely considers tradeoffs between resources and customers' satisfaction. To achieve the optimal tradeoff between resources and customers' satisfaction, we propose a new framework based on deep reinforcement learning, which directly takes both resources and user model into account. In addition to the framework, we also propose a new deep-reinforcement-learning based routing method-double dueling deep Q-learning with prioritized experience replay (PER-DoDDQN). We evaluate our proposed framework and method using both synthetic and a real customer service log data from a large financial technology company. We show that our proposed deep-reinforcement-learning based framework is superior to the existing production system. Moreover, we also show our proposed PER-DoDDQN is better than all other deep Q-learning variants in practice, which provides a more optimal routing plan. These observations suggest that our proposed method can seek the trade-off where both channel resources and customers' satisfaction are optimal.