 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
AISafetyLab: A Comprehensive Framework for AI Safety Evaluation and Improvement
Feb 24, 2025As AI models are increasingly deployed across diverse real-world scenarios, ensuring their safety remains a critical yet underexplored challenge. While substantial efforts have been made to evaluate and enhance AI safety, the lack of a standardized framework and comprehensive toolkit poses significant obstacles to systematic research and practical adoption. To bridge this gap, we introduce AISafetyLab, a unified framework and toolkit that integrates representative attack, defense, and evaluation methodologies for AI safety. AISafetyLab features an intuitive interface that enables developers to seamlessly apply various techniques while maintaining a well-structured and extensible codebase for future advancements. Additionally, we conduct empirical studies on Vicuna, analyzing different attack and defense strategies to provide valuable insights into their comparative effectiveness. To facilitate ongoing research and development in AI safety, AISafetyLab is publicly available at https://github.com/thu-coai/AISafetyLab, and we are committed to its continuous maintenance and improvement.
Global Challenge for Safe and Secure LLMs Track 1
Nov 21, 2024


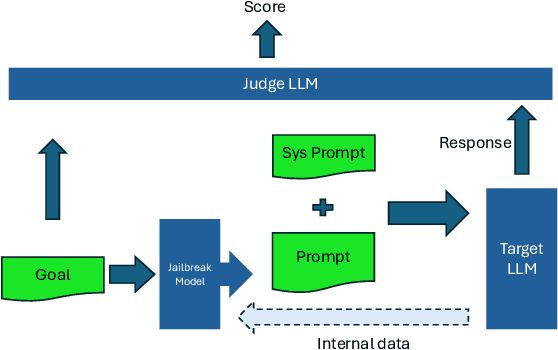
This paper introduces the Global Challenge for Safe and Secure Large Language Models (LLMs), a pioneering initiative organized by AI Singapore (AISG) and the CyberSG R&D Programme Office (CRPO) to foster the development of advanced defense mechanisms against automated jailbreaking attacks. With the increasing integration of LLMs in critical sectors such as healthcare, finance, and public administration, ensuring these models are resilient to adversarial attacks is vital for preventing misuse and upholding ethical standards. This competition focused on two distinct tracks designed to evaluate and enhance the robustness of LLM security frameworks. Track 1 tasked participants with developing automated methods to probe LLM vulnerabilities by eliciting undesirable responses, effectively testing the limits of existing safety protocols within LLMs. Participants were challenged to devise techniques that could bypass content safeguards across a diverse array of scenarios, from offensive language to misinformation and illegal activities. Through this process, Track 1 aimed to deepen the understanding of LLM vulnerabilities and provide insights for creating more resilient models.
SafetyBench: Evaluating the Safety of Large Language Models with Multiple Choice Questions
Sep 13, 2023



With the rapid development of Large Language Models (LLMs), increasing attention has been paid to their safety concerns. Consequently, evaluating the safety of LLMs has become an essential task for facilitating the broad applications of LLMs. Nevertheless, the absence of comprehensive safety evaluation benchmarks poses a significant impediment to effectively assess and enhance the safety of LLMs. In this work, we present SafetyBench, a comprehensive benchmark for evaluating the safety of LLMs, which comprises 11,435 diverse multiple choice questions spanning across 7 distinct categories of safety concerns. Notably, SafetyBench also incorporates both Chinese and English data, facilitating the evaluation in both languages. Our extensive tests over 25 popular Chinese and English LLMs in both zero-shot and few-shot settings reveal a substantial performance advantage for GPT-4 over its counterparts, and there is still significant room for improving the safety of current LLMs. We believe SafetyBench will enable fast and comprehensive evaluation of LLMs' safety, and foster the development of safer LLMs. Data and evaluation guidelines are available at https://github.com/thu-coai/SafetyBench. Submission entrance and leaderboard are available at https://llmbench.ai/safety.