 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWriting-RL: Advancing Long-form Writing via Adaptive Curriculum Reinforcement Learning
Jun 06, 2025Recent advances in Large Language Models (LLMs) have enabled strong performance in long-form writing, yet existing supervised fine-tuning (SFT) approaches suffer from limitations such as data saturation and restricted learning capacity bounded by teacher signals. In this work, we present Writing-RL: an Adaptive Curriculum Reinforcement Learning framework to advance long-form writing capabilities beyond SFT. The framework consists of three key components: Margin-aware Data Selection strategy that prioritizes samples with high learning potential, Pairwise Comparison Reward mechanism that provides discriminative learning signals in the absence of verifiable rewards, and Dynamic Reference Scheduling approach, which plays a particularly critical role by adaptively adjusting task difficulty based on evolving model performance. Experiments on 7B-scale writer models show that our RL framework largely improves long-form writing performance over strong SFT baselines. Furthermore, we observe that models trained with long-output RL generalize surprisingly well to long-input reasoning tasks, potentially offering a promising perspective for rethinking long-context training.
Agent-Environment Alignment via Automated Interface Generation
May 27, 2025



Large language model (LLM) agents have shown impressive reasoning capabilities in interactive decision-making tasks. These agents interact with environment through intermediate interfaces, such as predefined action spaces and interaction rules, which mediate the perception and action. However, mismatches often happen between the internal expectations of the agent regarding the influence of its issued actions and the actual state transitions in the environment, a phenomenon referred to as \textbf{agent-environment misalignment}. While prior work has invested substantially in improving agent strategies and environment design, the critical role of the interface still remains underexplored. In this work, we empirically demonstrate that agent-environment misalignment poses a significant bottleneck to agent performance. To mitigate this issue, we propose \textbf{ALIGN}, an \underline{A}uto-A\underline{l}igned \underline{I}nterface \underline{G}e\underline{n}eration framework that alleviates the misalignment by enriching the interface. Specifically, the ALIGN-generated interface enhances both the static information of the environment and the step-wise observations returned to the agent. Implemented as a lightweight wrapper, this interface achieves the alignment without modifying either the agent logic or the environment code. Experiments across multiple domains including embodied tasks, web navigation and tool-use, show consistent performance improvements, with up to a 45.67\% success rate improvement observed in ALFWorld. Meanwhile, ALIGN-generated interface can generalize across different agent architectures and LLM backbones without interface regeneration. Code and experimental results are available at https://github.com/THUNLP-MT/ALIGN.
Efficient Dynamic Clustering-Based Document Compression for Retrieval-Augmented-Generation
Apr 04, 2025



Retrieval-Augmented Generation (RAG) has emerged as a widely adopted approach for knowledge integration during large language model (LLM) inference in recent years. However, current RAG implementations face challenges in effectively addressing noise, repetition and redundancy in retrieved content, primarily due to their limited ability to exploit fine-grained inter-document relationships. To address these limitations, we propose an \textbf{E}fficient \textbf{D}ynamic \textbf{C}lustering-based document \textbf{C}ompression framework (\textbf{EDC\textsuperscript{2}-RAG}) that effectively utilizes latent inter-document relationships while simultaneously removing irrelevant information and redundant content. We validate our approach, built upon GPT-3.5, on widely used knowledge-QA and hallucination-detected datasets. The results show that this method achieves consistent performance improvements across various scenarios and experimental settings, demonstrating strong robustness and applicability. Our code and datasets can be found at https://github.com/Tsinghua-dhy/EDC-2-RAG.
AIGS: Generating Science from AI-Powered Automated Falsification
Nov 17, 2024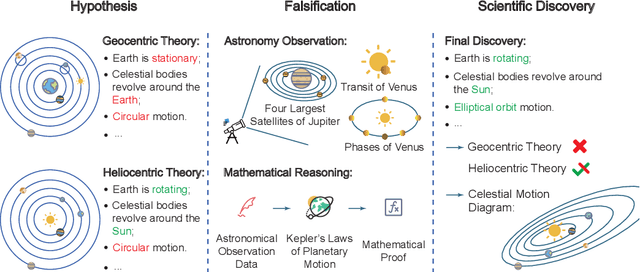

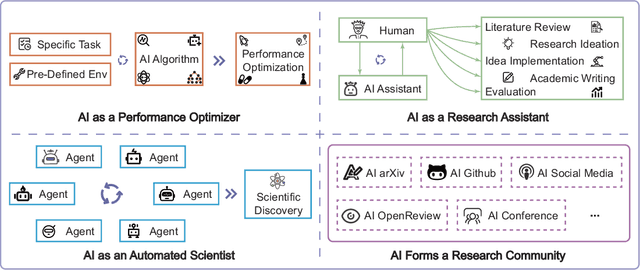

Rapid development of artificial intelligence has drastically accelerated the development of scientific discovery. Trained with large-scale observation data, deep neural networks extract the underlying patterns in an end-to-end manner and assist human researchers with highly-precised predictions in unseen scenarios. The recent rise of Large Language Models (LLMs) and the empowered autonomous agents enable scientists to gain help through interaction in different stages of their research, including but not limited to literature review, research ideation, idea implementation, and academic writing. However, AI researchers instantiated by foundation model empowered agents with full-process autonomy are still in their infancy. In this paper, we study $\textbf{AI-Generated Science}$ (AIGS), where agents independently and autonomously complete the entire research process and discover scientific laws. By revisiting the definition of scientific research, we argue that $\textit{falsification}$ is the essence of both human research process and the design of an AIGS system. Through the lens of falsification, prior systems attempting towards AI-Generated Science either lack the part in their design, or rely heavily on existing verification engines that narrow the use in specialized domains. In this work, we propose Baby-AIGS as a baby-step demonstration of a full-process AIGS system, which is a multi-agent system with agents in roles representing key research process. By introducing FalsificationAgent, which identify and then verify possible scientific discoveries, we empower the system with explicit falsification. Experiments on three tasks preliminarily show that Baby-AIGS could produce meaningful scientific discoveries, though not on par with experienced human researchers. Finally, we discuss on the limitations of current Baby-AIGS, actionable insights, and related ethical issues in detail.
A Cause-Effect Look at Alleviating Hallucination of Knowledge-grounded Dialogue Generation
Apr 04, 2024Empowered by the large-scale pretrained language models, existing dialogue systems have demonstrated impressive performance conducting fluent and natural-sounding conversations. However, they are still plagued by the hallucination problem, causing unpredictable factual errors in the generated responses. Recently, knowledge-grounded dialogue generation models, that intentionally invoke external knowledge resources to more informative responses, are also proven to be effective in reducing hallucination. Following the idea of getting high-quality knowledge, a few efforts have achieved pretty good performance on this issue. As some inevitable knowledge noises may also lead to hallucinations, it is emergent to investigate the reason and future directions for building noise-tolerant methods in KGD tasks. In this paper, we analyze the causal story behind this problem with counterfactual reasoning methods. Based on the causal effect analysis, we propose a possible solution for alleviating the hallucination in KGD by exploiting the dialogue-knowledge interaction. Experimental results of our example implementation show that this method can reduce hallucination without disrupting other dialogue performance, while keeping adaptive to different generation models. We hope our efforts can support and call for more attention to developing lightweight techniques towards robust and trusty dialogue systems.
Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models
Feb 19, 2024State-of-the-art Large Multi-Modal Models (LMMs) have demonstrated exceptional capabilities in vision-language tasks. Despite their advanced functionalities, the performances of LMMs are still limited in challenging scenarios that require complex reasoning with multiple levels of visual information. Existing prompting techniques for LMMs focus on either improving textual reasoning or leveraging tools for image preprocessing, lacking a simple and general visual prompting scheme to promote vision-language coordination in LMMs. In this work, we propose Scaffold prompting that scaffolds coordinates to promote vision-language coordination. Specifically, Scaffold overlays a dot matrix within the image as visual information anchors and leverages multi-dimensional coordinates as textual positional references. Extensive experiments on a wide range of challenging vision-language tasks demonstrate the superiority of Scaffold over GPT-4V with the textual CoT prompting. Our code is released in https://github.com/leixy20/Scaffold.
AlignBench: Benchmarking Chinese Alignment of Large Language Models
Dec 05, 2023



Alignment has become a critical step for instruction-tuned Large Language Models (LLMs) to become helpful assistants. However, effective evaluation of alignment for emerging Chinese LLMs is still significantly lacking, calling for real-scenario grounded, open-ended, challenging and automatic evaluations tailored for alignment. To fill in this gap, we introduce AlignBench, a comprehensive multi-dimensional benchmark for evaluating LLMs' alignment in Chinese. Equipped with a human-in-the-loop data curation pipeline, our benchmark employs a rule-calibrated multi-dimensional LLM-as-Judge with Chain-of-Thought to generate explanations and final ratings as evaluations, ensuring high reliability and interpretability. Furthermore, we report AlignBench evaluated by CritiqueLLM, a dedicated Chinese evaluator LLM that recovers 95% of GPT-4's evaluation ability. We will provide public APIs for evaluating AlignBench with CritiqueLLM to facilitate the evaluation of LLMs' Chinese alignment. All evaluation codes, data, and LLM generations are available at \url{https://github.com/THUDM/AlignBench}.
CritiqueLLM: Scaling LLM-as-Critic for Effective and Explainable Evaluation of Large Language Model Generation
Nov 30, 2023Since the natural language processing (NLP) community started to make large language models (LLMs), such as GPT-4, act as a critic to evaluate the quality of generated texts, most of them only train a critique generation model of a specific scale on specific datasets. We argue that a comprehensive investigation on the key factor of LLM-based evaluation models, such as scaling properties, is lacking, so that it is still inconclusive whether these models have potential to replace GPT-4's evaluation in practical scenarios. In this paper, we propose a new critique generation model called CritiqueLLM, which includes a dialogue-based prompting method for high-quality referenced / reference-free evaluation data. Experimental results show that our model can achieve comparable evaluation performance to GPT-4 especially in system-level correlations, and even outperform GPT-4 in 3 out of 8 tasks in a challenging reference-free setting. We conduct detailed analysis to show promising scaling properties of our model in the quality of generated critiques. We also demonstrate that our generated critiques can act as scalable feedback to directly improve the generation quality of LLMs.
SafetyBench: Evaluating the Safety of Large Language Models with Multiple Choice Questions
Sep 13, 2023



With the rapid development of Large Language Models (LLMs), increasing attention has been paid to their safety concerns. Consequently, evaluating the safety of LLMs has become an essential task for facilitating the broad applications of LLMs. Nevertheless, the absence of comprehensive safety evaluation benchmarks poses a significant impediment to effectively assess and enhance the safety of LLMs. In this work, we present SafetyBench, a comprehensive benchmark for evaluating the safety of LLMs, which comprises 11,435 diverse multiple choice questions spanning across 7 distinct categories of safety concerns. Notably, SafetyBench also incorporates both Chinese and English data, facilitating the evaluation in both languages. Our extensive tests over 25 popular Chinese and English LLMs in both zero-shot and few-shot settings reveal a substantial performance advantage for GPT-4 over its counterparts, and there is still significant room for improving the safety of current LLMs. We believe SafetyBench will enable fast and comprehensive evaluation of LLMs' safety, and foster the development of safer LLMs. Data and evaluation guidelines are available at https://github.com/thu-coai/SafetyBench. Submission entrance and leaderboard are available at https://llmbench.ai/safety.
AgentBench: Evaluating LLMs as Agents
Aug 07, 2023



Large Language Models (LLMs) are becoming increasingly smart and autonomous, targeting real-world pragmatic missions beyond traditional NLP tasks. As a result, there has been an urgent need to evaluate LLMs as agents on challenging tasks in interactive environments. We present AgentBench, a multi-dimensional evolving benchmark that currently consists of 8 distinct environments to assess LLM-as-Agent's reasoning and decision-making abilities in a multi-turn open-ended generation setting. Our extensive test over 25 LLMs (including APIs and open-sourced models) shows that, while top commercial LLMs present a strong ability of acting as agents in complex environments, there is a significant disparity in performance between them and open-sourced competitors. It also serves as a component of an ongoing project with wider coverage and deeper consideration towards systematic LLM evaluation. Datasets, environments, and an integrated evaluation package for AgentBench are released at https://github.com/THUDM/AgentBench