 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Algorithm, Two Goals: Dual Scoring for Parameter and Data Selection in LLM Fine-Tuning
May 07, 2026In Large Language Model (LLM) fine-tuning, parameter and data selection are common strategies for reducing fine-tuning cost, yet they are typically driven by separate scoring mechanisms. When a parameter mask and data subset jointly determine restricted fine-tuning, this separation incurs redundant overhead and makes coordinated selection difficult. We cast parameter and data selection as two bilevel selection problems under a common validation objective and derive a shared local response-surrogate scoring rule. Under first- and second-order validation-improvement approximations, parameter importance and data utility emerge as column-wise and row-wise aggregations of a single gradient interaction matrix, yielding a closed-form row-column correspondence for co-extracting both signals. Building on this structure, we propose DualSFT (Dual-Selection Fine-Tuning), a one-shot dual-scoring algorithm that produces a parameter mask and data subset from shared gradient statistics. On 3B-9B LLMs, single-axis DualSFT variants strengthen target-task performance and stability-plasticity trade-offs within their comparison groups, while full DualSFT yields a more favorable joint-constrained trade-off than sequential hybrid baselines under matched budgets.
Love Me, Love My Label: Rethinking the Role of Labels in Prompt Retrieval for Visual In-Context Learning
Apr 04, 2026Visual in-context learning (VICL) enables visual foundation models to handle multiple tasks by steering them with demonstrative prompts. The choice of such prompts largely influences VICL performance, standing out as a key challenge. Prior work has made substantial progress on prompt retrieval and reranking strategies, but mainly focuses on prompt images while overlooking labels. We reveal these approaches sometimes get visually similar but label-inconsistent prompts, which potentially degrade VICL performance. On the other hand, higher label consistency between query and prompts preferably indicates stronger VICL results. Motivated by these findings, we develop a framework named LaPR (Label-aware Prompt Retrieval), which highlights the role of labels in prompt selection. Our framework first designs an image-label joint representation for prompts to incorporate label cues explicitly. Besides, to handle unavailable query labels at test time, we introduce a mixture-of-expert mechanism to the dual encoders with query-adaptive routing. Each expert is expected to capture a specific label mode, while the router infers query-adaptive mixture weights and helps to learn label-aware representation. We carefully design alternative optimization for experts and router, with a VICL performance-guided contrastive loss and a label-guided contrastive loss, respectively. Extensive experiments show promising and consistent improvement of LaPR on in-context segmentation, detection, and colorization tasks. Moreover, LaPR generalizes well across feature extractors and cross-fold scenarios, suggesting the importance of label utilization in prompt retrieval for VICL. Code is available at https://github.com/luotc-why/CVPR26-LaPR.
GloPath: An Entity-Centric Foundation Model for Glomerular Lesion Assessment and Clinicopathological Insights
Mar 03, 2026Glomerular pathology is central to the diagnosis and prognosis of renal diseases, yet the heterogeneity of glomerular morphology and fine-grained lesion patterns remain challenging for current AI approaches. We present GloPath, an entity-centric foundation model trained on over one million glomeruli extracted from 14,049 renal biopsy specimens using multi-scale and multi-view self-supervised learning. GloPath addresses two major challenges in nephropathology: glomerular lesion assessment and clinicopathological insights discovery. For lesion assessment, GloPath was benchmarked across three independent cohorts on 52 tasks, including lesion recognition, grading, few-shot classification, and cross-modality diagnosis-outperforming state-of-the-art methods in 42 tasks (80.8%). In the large-scale real-world study, it achieved an ROC-AUC of 91.51% for lesion recognition, demonstrating strong robustness in routine clinical settings. For clinicopathological insights, GloPath systematically revealed statistically significant associations between glomerular morphological parameters and clinical indicators across 224 morphology-clinical variable pairs, demonstrating its capacity to connect tissue-level pathology with patient-level outcomes. Together, these results position GloPath as a scalable and interpretable platform for glomerular lesion assessment and clinicopathological discovery, representing a step toward clinically translatable AI in renal pathology.
HookMIL: Revisiting Context Modeling in Multiple Instance Learning for Computational Pathology
Dec 20, 2025Multiple Instance Learning (MIL) has enabled weakly supervised analysis of whole-slide images (WSIs) in computational pathology. However, traditional MIL approaches often lose crucial contextual information, while transformer-based variants, though more expressive, suffer from quadratic complexity and redundant computations. To address these limitations, we propose HookMIL, a context-aware and computationally efficient MIL framework that leverages compact, learnable hook tokens for structured contextual aggregation. These tokens can be initialized from (i) key-patch visual features, (ii) text embeddings from vision-language pathology models, and (iii) spatially grounded features from spatial transcriptomics-vision models. This multimodal initialization enables Hook Tokens to incorporate rich textual and spatial priors, accelerating convergence and enhancing representation quality. During training, Hook tokens interact with instances through bidirectional attention with linear complexity. To further promote specialization, we introduce a Hook Diversity Loss that encourages each token to focus on distinct histopathological patterns. Additionally, a hook-to-hook communication mechanism refines contextual interactions while minimizing redundancy. Extensive experiments on four public pathology datasets demonstrate that HookMIL achieves state-of-the-art performance, with improved computational efficiency and interpretability. Codes are available at https://github.com/lingxitong/HookMIL.
Learning to Pose Problems: Reasoning-Driven and Solver-Adaptive Data Synthesis for Large Reasoning Models
Nov 13, 2025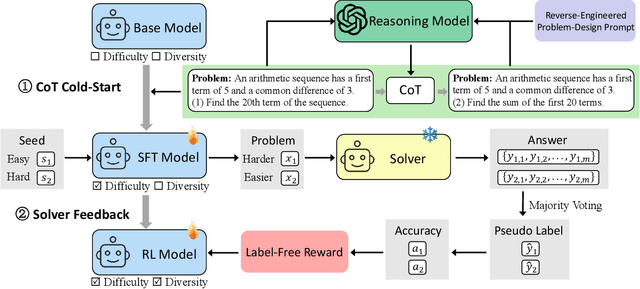
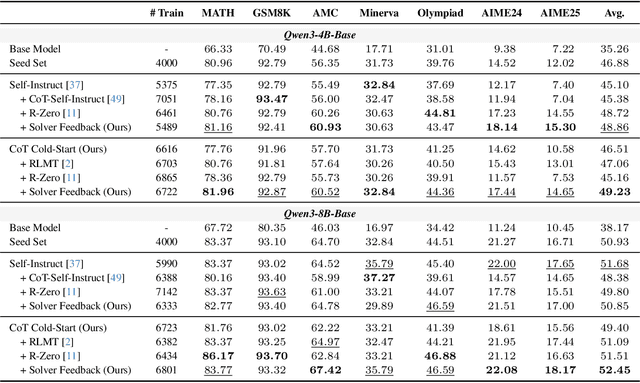

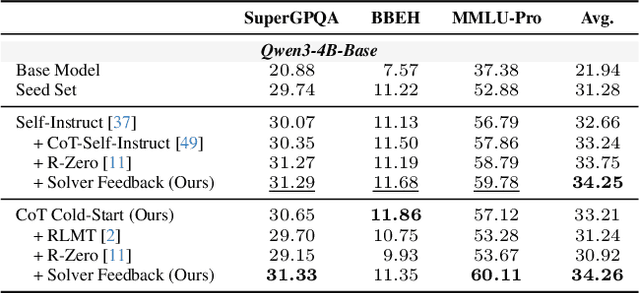
Data synthesis for training large reasoning models offers a scalable alternative to limited, human-curated datasets, enabling the creation of high-quality data. However, existing approaches face several challenges: (i) indiscriminate generation that ignores the solver's ability and yields low-value problems, or reliance on complex data pipelines to balance problem difficulty; and (ii) a lack of reasoning in problem generation, leading to shallow problem variants. In this paper, we develop a problem generator that reasons explicitly to plan problem directions before synthesis and adapts difficulty to the solver's ability. Specifically, we construct related problem pairs and augment them with intermediate problem-design CoT produced by a reasoning model. These data bootstrap problem-design strategies from the generator. Then, we treat the solver's feedback on synthetic problems as a reward signal, enabling the generator to calibrate difficulty and produce complementary problems near the edge of the solver's competence. Extensive experiments on 10 mathematical and general reasoning benchmarks show that our method achieves an average improvement of 2.5% and generalizes to both language and vision-language models. Moreover, a solver trained on the synthesized data provides improved rewards for continued generator training, enabling co-evolution and yielding a further 0.7% performance gain. Our code will be made publicly available here.
Task-Specific Zero-shot Quantization-Aware Training for Object Detection
Jul 22, 2025Quantization is a key technique to reduce network size and computational complexity by representing the network parameters with a lower precision. Traditional quantization methods rely on access to original training data, which is often restricted due to privacy concerns or security challenges. Zero-shot Quantization (ZSQ) addresses this by using synthetic data generated from pre-trained models, eliminating the need for real training data. Recently, ZSQ has been extended to object detection. However, existing methods use unlabeled task-agnostic synthetic images that lack the specific information required for object detection, leading to suboptimal performance. In this paper, we propose a novel task-specific ZSQ framework for object detection networks, which consists of two main stages. First, we introduce a bounding box and category sampling strategy to synthesize a task-specific calibration set from the pre-trained network, reconstructing object locations, sizes, and category distributions without any prior knowledge. Second, we integrate task-specific training into the knowledge distillation process to restore the performance of quantized detection networks. Extensive experiments conducted on the MS-COCO and Pascal VOC datasets demonstrate the efficiency and state-of-the-art performance of our method. Our code is publicly available at: https://github.com/DFQ-Dojo/dfq-toolkit .
A Simple Linear Patch Revives Layer-Pruned Large Language Models
May 30, 2025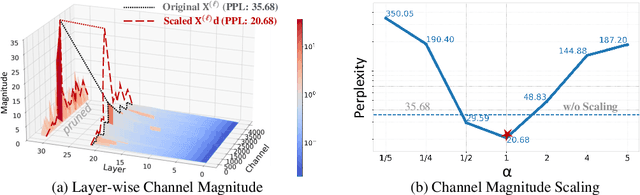
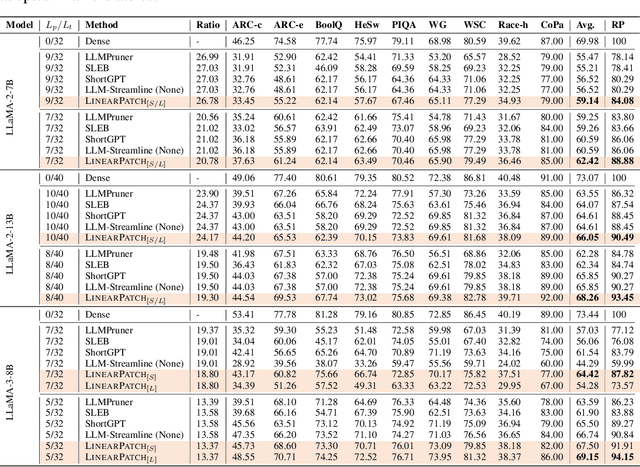
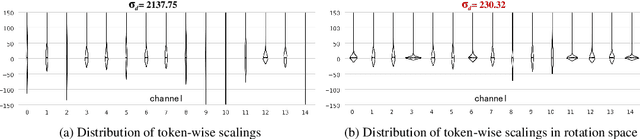
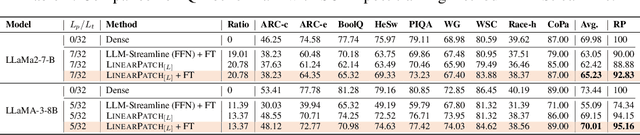
Layer pruning has become a popular technique for compressing large language models (LLMs) due to its simplicity. However, existing layer pruning methods often suffer from significant performance drops. We identify that this degradation stems from the mismatch of activation magnitudes across layers and tokens at the pruning interface. To address this, we propose LinearPatch, a simple plug-and-play technique to revive the layer-pruned LLMs. The proposed method adopts Hadamard transformation to suppress massive outliers in particular tokens, and channel-wise scaling to align the activation magnitudes. These operations can be fused into a single matrix, which functions as a patch to bridge the pruning interface with negligible inference overhead. LinearPatch retains up to 94.15% performance of the original model when pruning 5 layers of LLaMA-3-8B on the question answering benchmark, surpassing existing state-of-the-art methods by 4%. In addition, the patch matrix can be further optimized with memory efficient offline knowledge distillation. With only 5K samples, the retained performance of LinearPatch can be further boosted to 95.16% within 30 minutes on a single computing card.
Agent Aggregator with Mask Denoise Mechanism for Histopathology Whole Slide Image Analysis
Sep 18, 2024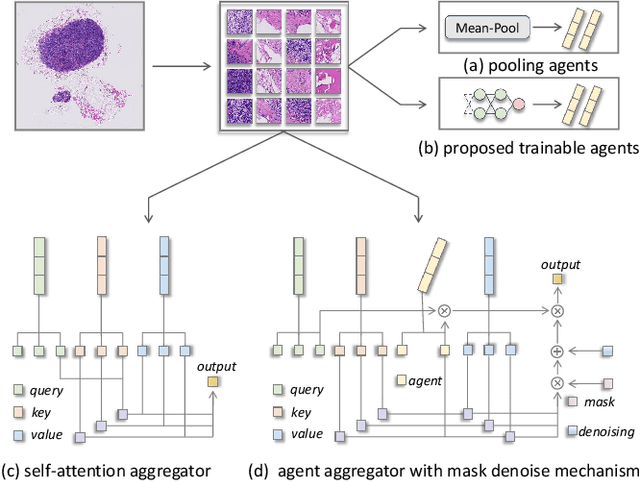
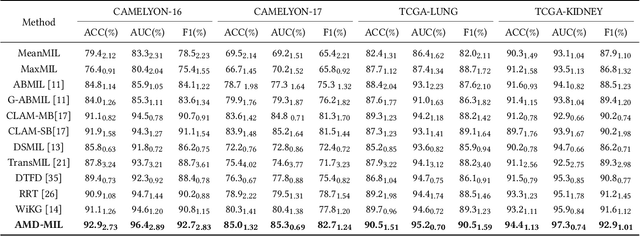
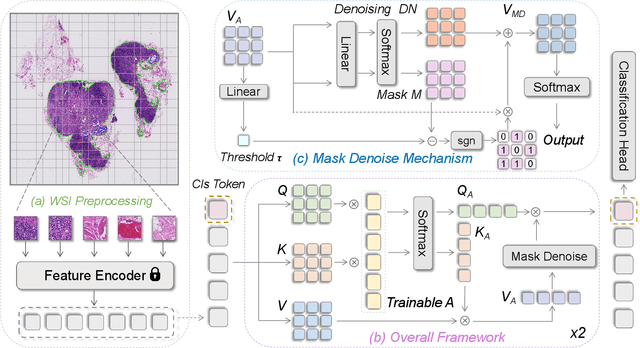
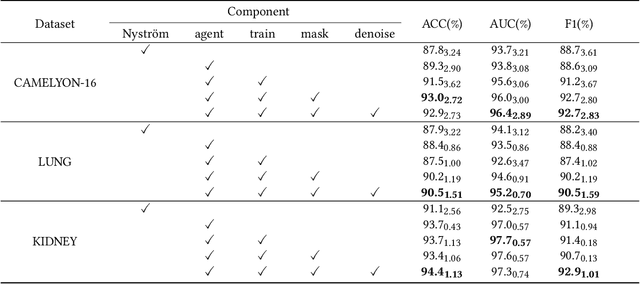
Histopathology analysis is the gold standard for medical diagnosis. Accurate classification of whole slide images (WSIs) and region-of-interests (ROIs) localization can assist pathologists in diagnosis. The gigapixel resolution of WSI and the absence of fine-grained annotations make direct classification and analysis challenging. In weakly supervised learning, multiple instance learning (MIL) presents a promising approach for WSI classification. The prevailing strategy is to use attention mechanisms to measure instance importance for classification. However, attention mechanisms fail to capture inter-instance information, and self-attention causes quadratic computational complexity. To address these challenges, we propose AMD-MIL, an agent aggregator with a mask denoise mechanism. The agent token acts as an intermediate variable between the query and key for computing instance importance. Mask and denoising matrices, mapped from agents-aggregated value, dynamically mask low-contribution representations and eliminate noise. AMD-MIL achieves better attention allocation by adjusting feature representations, capturing micro-metastases in cancer, and improving interpretability. Extensive experiments on CAMELYON-16, CAMELYON-17, TCGA-KIDNEY, and TCGA-LUNG show AMD-MIL's superiority over state-of-the-art methods.
Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models
Feb 19, 2024State-of-the-art Large Multi-Modal Models (LMMs) have demonstrated exceptional capabilities in vision-language tasks. Despite their advanced functionalities, the performances of LMMs are still limited in challenging scenarios that require complex reasoning with multiple levels of visual information. Existing prompting techniques for LMMs focus on either improving textual reasoning or leveraging tools for image preprocessing, lacking a simple and general visual prompting scheme to promote vision-language coordination in LMMs. In this work, we propose Scaffold prompting that scaffolds coordinates to promote vision-language coordination. Specifically, Scaffold overlays a dot matrix within the image as visual information anchors and leverages multi-dimensional coordinates as textual positional references. Extensive experiments on a wide range of challenging vision-language tasks demonstrate the superiority of Scaffold over GPT-4V with the textual CoT prompting. Our code is released in https://github.com/leixy20/Scaffold.
Towards Unified Alignment Between Agents, Humans, and Environment
Feb 14, 2024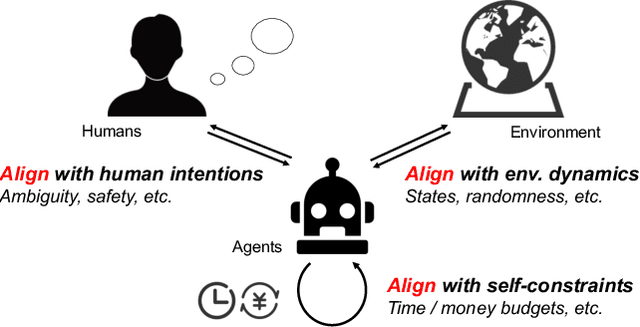
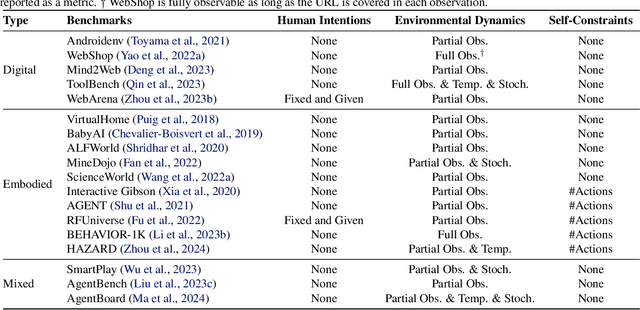
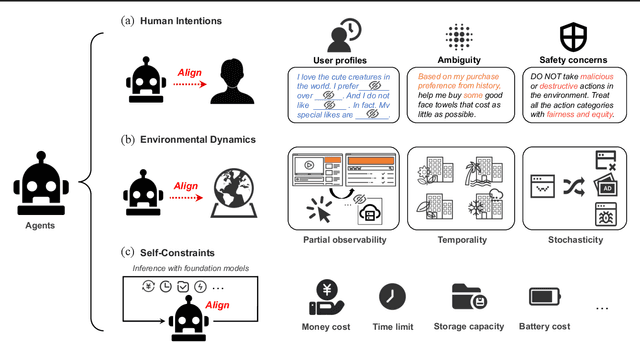

The rapid progress of foundation models has led to the prosperity of autonomous agents, which leverage the universal capabilities of foundation models to conduct reasoning, decision-making, and environmental interaction. However, the efficacy of agents remains limited when operating in intricate, realistic environments. In this work, we introduce the principles of $\mathbf{U}$nified $\mathbf{A}$lignment for $\mathbf{A}$gents ($\mathbf{UA}^2$), which advocate for the simultaneous alignment of agents with human intentions, environmental dynamics, and self-constraints such as the limitation of monetary budgets. From the perspective of $\mathbf{UA}^2$, we review the current agent research and highlight the neglected factors in existing agent benchmarks and method candidates. We also conduct proof-of-concept studies by introducing realistic features to WebShop, including user profiles to demonstrate intentions, personalized reranking for complex environmental dynamics, and runtime cost statistics to reflect self-constraints. We then follow the principles of $\mathbf{UA}^2$ to propose an initial design of our agent, and benchmark its performance with several candidate baselines in the retrofitted WebShop. The extensive experimental results further prove the importance of the principles of $\mathbf{UA}^2$. Our research sheds light on the next steps of autonomous agent research with improved general problem-solving abilities.