 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Reinforcement Learning for Content Moderation with Large Language Models
Dec 23, 2025
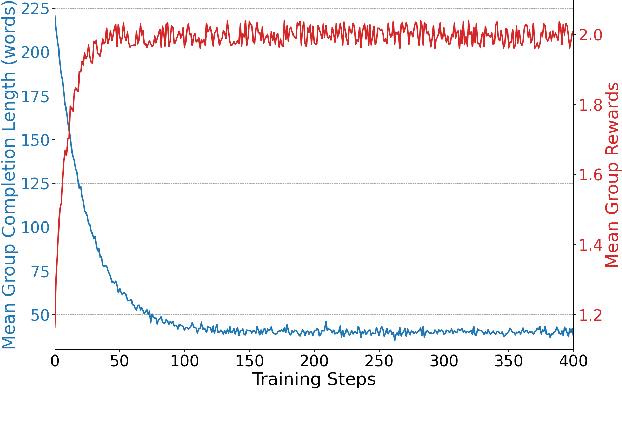
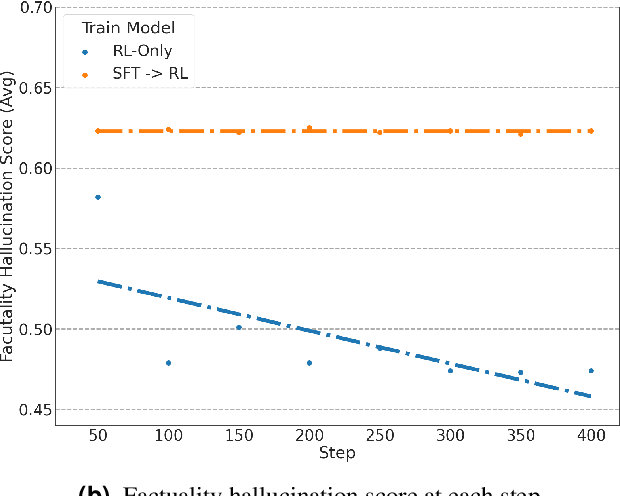
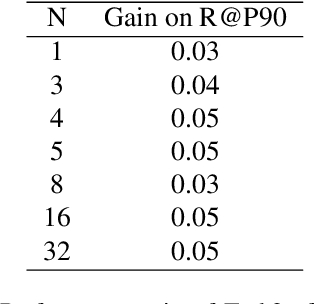
Content moderation at scale remains one of the most pressing challenges in today's digital ecosystem, where billions of user- and AI-generated artifacts must be continuously evaluated for policy violations. Although recent advances in large language models (LLMs) have demonstrated strong potential for policy-grounded moderation, the practical challenges of training these systems to achieve expert-level accuracy in real-world settings remain largely unexplored, particularly in regimes characterized by label sparsity, evolving policy definitions, and the need for nuanced reasoning beyond shallow pattern matching. In this work, we present a comprehensive empirical investigation of scaling reinforcement learning (RL) for content classification, systematically evaluating multiple RL training recipes and reward-shaping strategies-including verifiable rewards and LLM-as-judge frameworks-to transform general-purpose language models into specialized, policy-aligned classifiers across three real-world content moderation tasks. Our findings provide actionable insights for industrial-scale moderation systems, demonstrating that RL exhibits sigmoid-like scaling behavior in which performance improves smoothly with increased training data, rollouts, and optimization steps before gradually saturating. Moreover, we show that RL substantially improves performance on tasks requiring complex policy-grounded reasoning while achieving up to 100x higher data efficiency than supervised fine-tuning, making it particularly effective in domains where expert annotations are scarce or costly.
Towards Unified Alignment Between Agents, Humans, and Environment
Feb 14, 2024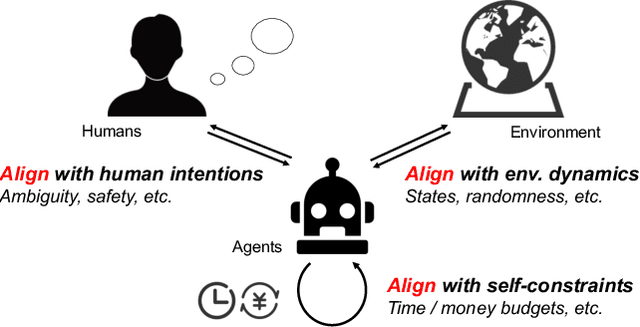
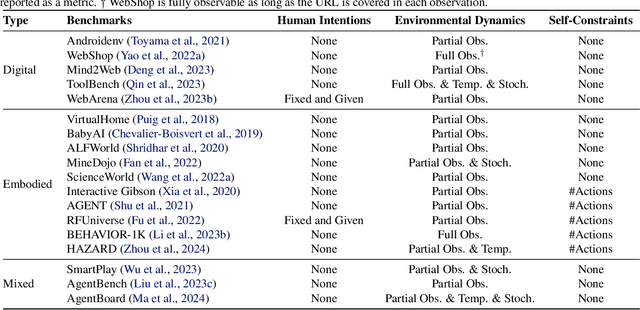
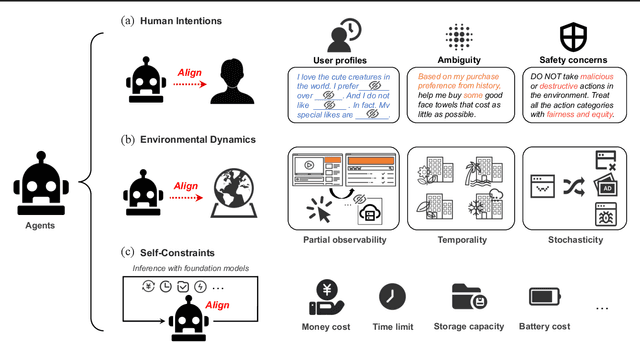

The rapid progress of foundation models has led to the prosperity of autonomous agents, which leverage the universal capabilities of foundation models to conduct reasoning, decision-making, and environmental interaction. However, the efficacy of agents remains limited when operating in intricate, realistic environments. In this work, we introduce the principles of $\mathbf{U}$nified $\mathbf{A}$lignment for $\mathbf{A}$gents ($\mathbf{UA}^2$), which advocate for the simultaneous alignment of agents with human intentions, environmental dynamics, and self-constraints such as the limitation of monetary budgets. From the perspective of $\mathbf{UA}^2$, we review the current agent research and highlight the neglected factors in existing agent benchmarks and method candidates. We also conduct proof-of-concept studies by introducing realistic features to WebShop, including user profiles to demonstrate intentions, personalized reranking for complex environmental dynamics, and runtime cost statistics to reflect self-constraints. We then follow the principles of $\mathbf{UA}^2$ to propose an initial design of our agent, and benchmark its performance with several candidate baselines in the retrofitted WebShop. The extensive experimental results further prove the importance of the principles of $\mathbf{UA}^2$. Our research sheds light on the next steps of autonomous agent research with improved general problem-solving abilities.