 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindsight Hint Distillation: Scaffolded Reasoning for SWE Agents from CoT-free Answers
May 12, 2026Solving complex long-horizon tasks requires strong planning and reasoning capabilities. Although datasets with explicit chain-of-thought (CoT) rationales can substantially benefit learning, they are costly to obtain. To address this challenge, we propose Hindsight Hint Distillation (HHD), which only requires easy-to-obtain question-answer pairs without CoT annotations. Inspired by how human teachers use student mistakes to provide targeted guidance, HHD synthesizes hindsight hints from the model's own failed self-rollouts and uses them to scaffold on-policy rollouts that successfully complete the tasks. The model then self-distills these scaffolded trajectories and generalizes to new problems without hint guidance. Experiments show that HHD significantly outperforms iterative RFT and trajectory-synthesis baselines, achieving an absolute improvement of 8\% on SWE-bench Verified, while all baselines improve by only around 2\%. Notably, the reasoning strategies induced by HHD generalize effectively to out-of-distribution tasks, yielding the largest gains on SWE-bench Multilingual despite no training on multilingual data. These results demonstrate that HHD can effectively synthesize expert-like reasoning from CoT-free data and substantially improve long-horizon performance.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
AIGS: Generating Science from AI-Powered Automated Falsification
Nov 17, 2024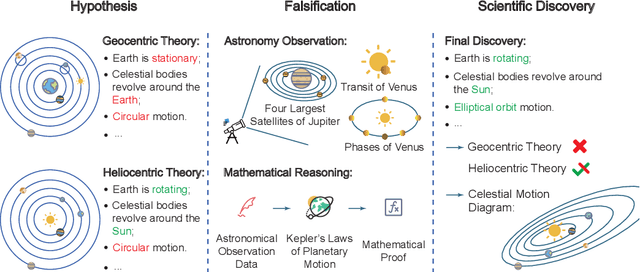

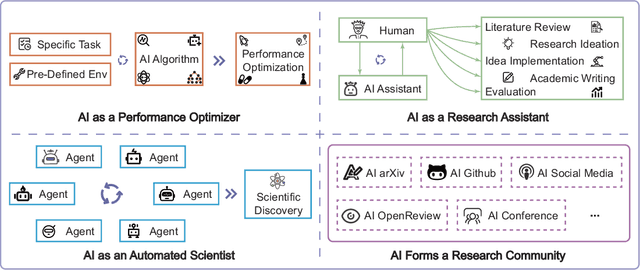

Rapid development of artificial intelligence has drastically accelerated the development of scientific discovery. Trained with large-scale observation data, deep neural networks extract the underlying patterns in an end-to-end manner and assist human researchers with highly-precised predictions in unseen scenarios. The recent rise of Large Language Models (LLMs) and the empowered autonomous agents enable scientists to gain help through interaction in different stages of their research, including but not limited to literature review, research ideation, idea implementation, and academic writing. However, AI researchers instantiated by foundation model empowered agents with full-process autonomy are still in their infancy. In this paper, we study $\textbf{AI-Generated Science}$ (AIGS), where agents independently and autonomously complete the entire research process and discover scientific laws. By revisiting the definition of scientific research, we argue that $\textit{falsification}$ is the essence of both human research process and the design of an AIGS system. Through the lens of falsification, prior systems attempting towards AI-Generated Science either lack the part in their design, or rely heavily on existing verification engines that narrow the use in specialized domains. In this work, we propose Baby-AIGS as a baby-step demonstration of a full-process AIGS system, which is a multi-agent system with agents in roles representing key research process. By introducing FalsificationAgent, which identify and then verify possible scientific discoveries, we empower the system with explicit falsification. Experiments on three tasks preliminarily show that Baby-AIGS could produce meaningful scientific discoveries, though not on par with experienced human researchers. Finally, we discuss on the limitations of current Baby-AIGS, actionable insights, and related ethical issues in detail.
ReAct Meets ActRe: Autonomous Annotation of Agent Trajectories for Contrastive Self-Training
Mar 25, 2024Language agents have demonstrated autonomous decision-making abilities by reasoning with foundation models. Recently, efforts have been made to train language agents for performance improvement, with multi-step reasoning and action trajectories as the training data. However, collecting such trajectories still requires considerable human effort, by either artificial annotation or implementations of diverse prompting frameworks. In this work, we propose A$^3$T, a framework that enables the Autonomous Annotation of Agent Trajectories in the style of ReAct. The central role is an ActRe prompting agent, which explains the reason for an arbitrary action. When randomly sampling an external action, the ReAct-style agent could query the ActRe agent with the action to obtain its textual rationales. Novel trajectories are then synthesized by prepending the posterior reasoning from ActRe to the sampled action. In this way, the ReAct-style agent executes multiple trajectories for the failed tasks, and selects the successful ones to supplement its failed trajectory for contrastive self-training. Realized by policy gradient methods with binarized rewards, the contrastive self-training with accumulated trajectories facilitates a closed loop for multiple rounds of language agent self-improvement. We conduct experiments using QLoRA fine-tuning with the open-sourced Mistral-7B-Instruct-v0.2. In AlfWorld, the agent trained with A$^3$T obtains a 1-shot success rate of 96%, and 100% success with 4 iterative rounds. In WebShop, the 1-shot performance of the A$^3$T agent matches human average, and 4 rounds of iterative refinement lead to the performance approaching human experts. A$^3$T agents significantly outperform existing techniques, including prompting with GPT-4, advanced agent frameworks, and fully fine-tuned LLMs.
PANDA: Preference Adaptation for Enhancing Domain-Specific Abilities of LLMs
Feb 20, 2024While Large language models (LLMs) have demonstrated considerable capabilities across various natural language tasks, they often fall short of the performance achieved by domain-specific state-of-the-art models. One potential approach to enhance domain-specific capabilities of LLMs involves fine-tuning them using corresponding datasets. However, this method can be both resource and time-intensive, and not applicable to closed-source commercial LLMs. In this paper, we propose Preference Adaptation for Enhancing Domain-specific Abilities of LLMs (PANDA), a method designed to augment the domain-specific capabilities of LLMs by leveraging insights from the response preference of expert models without requiring fine-tuning. Our experimental results reveal that PANDA significantly enhances the domain-specific ability of LLMs on text classification and interactive decision tasks. Moreover, LLM with PANDA even outperforms the expert model that being learned on 4 tasks of ScienceWorld. This finding highlights the potential of exploring tuning-free approaches to achieve weak-to-strong generalization.
Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models
Feb 19, 2024State-of-the-art Large Multi-Modal Models (LMMs) have demonstrated exceptional capabilities in vision-language tasks. Despite their advanced functionalities, the performances of LMMs are still limited in challenging scenarios that require complex reasoning with multiple levels of visual information. Existing prompting techniques for LMMs focus on either improving textual reasoning or leveraging tools for image preprocessing, lacking a simple and general visual prompting scheme to promote vision-language coordination in LMMs. In this work, we propose Scaffold prompting that scaffolds coordinates to promote vision-language coordination. Specifically, Scaffold overlays a dot matrix within the image as visual information anchors and leverages multi-dimensional coordinates as textual positional references. Extensive experiments on a wide range of challenging vision-language tasks demonstrate the superiority of Scaffold over GPT-4V with the textual CoT prompting. Our code is released in https://github.com/leixy20/Scaffold.
OneBit: Towards Extremely Low-bit Large Language Models
Feb 17, 2024Model quantification uses low bit-width values to represent the weight matrices of models, which is a promising approach to reduce both storage and computational overheads of deploying highly anticipated LLMs. However, existing quantization methods suffer severe performance degradation when the bit-width is extremely reduced, and thus focus on utilizing 4-bit or 8-bit values to quantize models. This paper boldly quantizes the weight matrices of LLMs to 1-bit, paving the way for the extremely low bit-width deployment of LLMs. For this target, we introduce a 1-bit quantization-aware training (QAT) framework named OneBit, including a novel 1-bit parameter representation method to better quantize LLMs as well as an effective parameter initialization method based on matrix decomposition to improve the convergence speed of the QAT framework. Sufficient experimental results indicate that OneBit achieves good performance (at least 83% of the non-quantized performance) with robust training processes when only using 1-bit weight matrices.
Towards Unified Alignment Between Agents, Humans, and Environment
Feb 14, 2024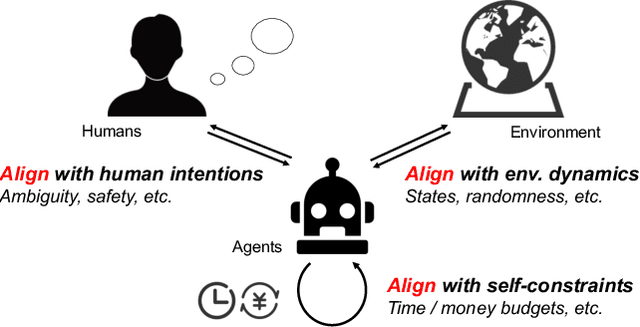
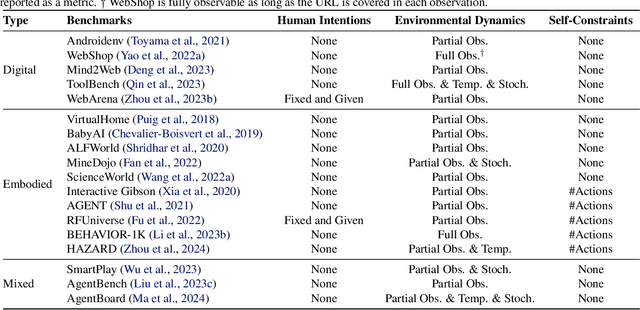
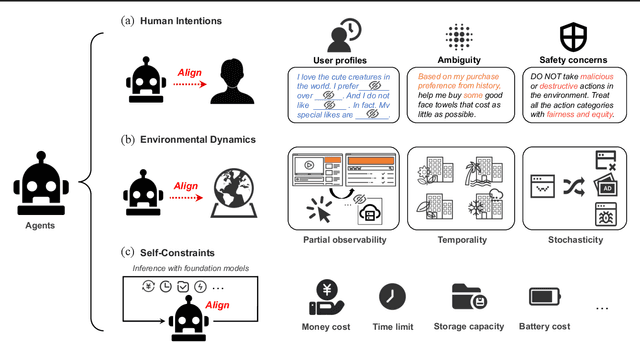

The rapid progress of foundation models has led to the prosperity of autonomous agents, which leverage the universal capabilities of foundation models to conduct reasoning, decision-making, and environmental interaction. However, the efficacy of agents remains limited when operating in intricate, realistic environments. In this work, we introduce the principles of $\mathbf{U}$nified $\mathbf{A}$lignment for $\mathbf{A}$gents ($\mathbf{UA}^2$), which advocate for the simultaneous alignment of agents with human intentions, environmental dynamics, and self-constraints such as the limitation of monetary budgets. From the perspective of $\mathbf{UA}^2$, we review the current agent research and highlight the neglected factors in existing agent benchmarks and method candidates. We also conduct proof-of-concept studies by introducing realistic features to WebShop, including user profiles to demonstrate intentions, personalized reranking for complex environmental dynamics, and runtime cost statistics to reflect self-constraints. We then follow the principles of $\mathbf{UA}^2$ to propose an initial design of our agent, and benchmark its performance with several candidate baselines in the retrofitted WebShop. The extensive experimental results further prove the importance of the principles of $\mathbf{UA}^2$. Our research sheds light on the next steps of autonomous agent research with improved general problem-solving abilities.
Adversarial Robust Memory-Based Continual Learner
Nov 29, 2023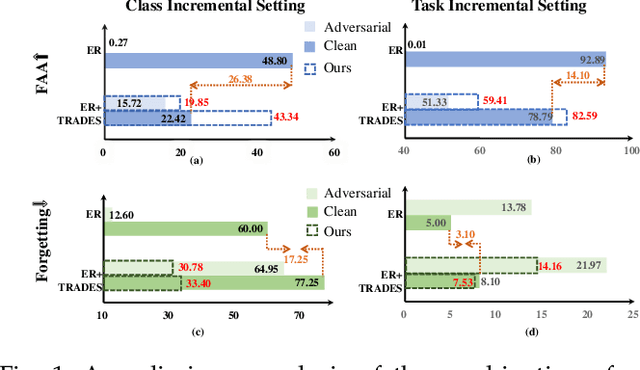
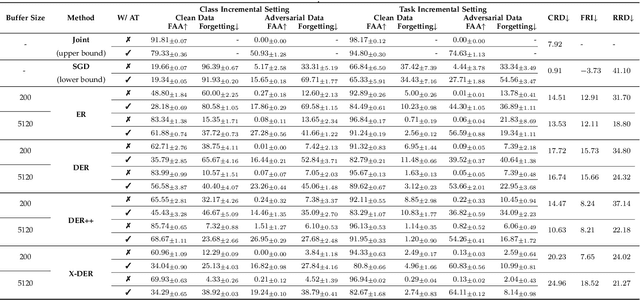
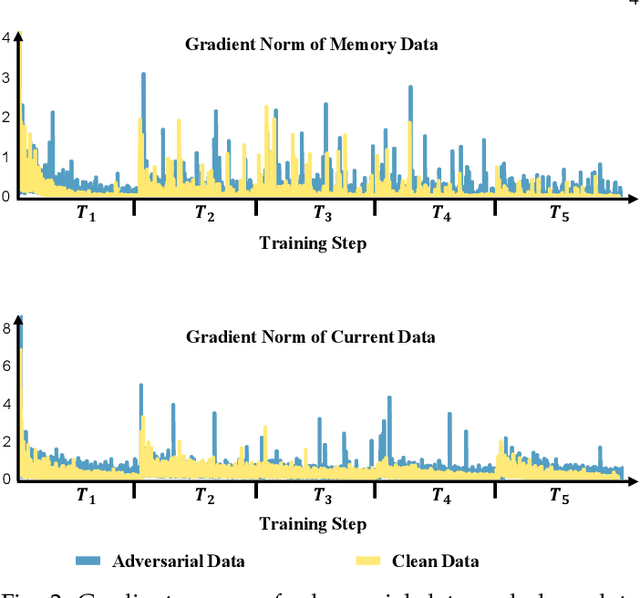
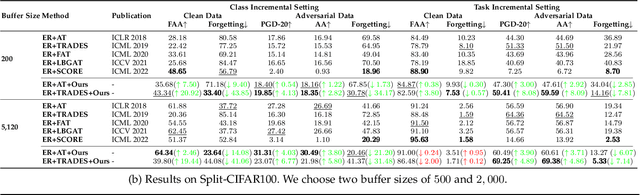
Despite the remarkable advances that have been made in continual learning, the adversarial vulnerability of such methods has not been fully discussed. We delve into the adversarial robustness of memory-based continual learning algorithms and observe limited robustness improvement by directly applying adversarial training techniques. Preliminary studies reveal the twin challenges for building adversarial robust continual learners: accelerated forgetting in continual learning and gradient obfuscation in adversarial robustness. In this study, we put forward a novel adversarial robust memory-based continual learner that adjusts data logits to mitigate the forgetting of pasts caused by adversarial samples. Furthermore, we devise a gradient-based data selection mechanism to overcome the gradient obfuscation caused by limited stored data. The proposed approach can widely integrate with existing memory-based continual learning as well as adversarial training algorithms in a plug-and-play way. Extensive experiments on Split-CIFAR10/100 and Split-Tiny-ImageNet demonstrate the effectiveness of our approach, achieving up to 8.13% higher accuracy for adversarial data.