 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Versatile Coding Agents in Synthetic Environments
Dec 13, 2025Prior works on training software engineering agents have explored utilizing existing resources such as issues on GitHub repositories to construct software engineering tasks and corresponding test suites. These approaches face two key limitations: (1) their reliance on pre-existing GitHub repositories offers limited flexibility, and (2) their primary focus on issue resolution tasks restricts their applicability to the much wider variety of tasks a software engineer must handle. To overcome these challenges, we introduce SWE-Playground, a novel pipeline for generating environments and trajectories which supports the training of versatile coding agents. Unlike prior efforts, SWE-Playground synthetically generates projects and tasks from scratch with strong language models and agents, eliminating reliance on external data sources. This allows us to tackle a much wider variety of coding tasks, such as reproducing issues by generating unit tests and implementing libraries from scratch. We demonstrate the effectiveness of this approach on three distinct benchmarks, and results indicate that SWE-Playground produces trajectories with dense training signal, enabling agents to reach comparable performance with significantly fewer trajectories than previous works.
CoSpace: Benchmarking Continuous Space Perception Ability for Vision-Language Models
Mar 18, 2025Vision-Language Models (VLMs) have recently witnessed significant progress in visual comprehension. As the permitting length of image context grows, VLMs can now comprehend a broader range of views and spaces. Current benchmarks provide insightful analysis of VLMs in tasks involving complex visual instructions following, multi-image understanding and spatial reasoning. However, they usually focus on spatially irrelevant images or discrete images captured from varied viewpoints. The compositional characteristic of images captured from a static viewpoint remains underestimated. We term this characteristic as Continuous Space Perception. When observing a scene from a static viewpoint while shifting orientations, it produces a series of spatially continuous images, enabling the reconstruction of the entire space. In this paper, we present CoSpace, a multi-image visual understanding benchmark designed to assess the Continuous Space perception ability for VLMs. CoSpace contains 2,918 images and 1,626 question-answer pairs, covering seven types of tasks. We conduct evaluation across 19 proprietary and open-source VLMs. Results reveal that there exist pitfalls on the continuous space perception ability for most of the evaluated models, including proprietary ones. Interestingly, we find that the main discrepancy between open-source and proprietary models lies not in accuracy but in the consistency of responses. We believe that enhancing the ability of continuous space perception is essential for VLMs to perform effectively in real-world tasks and encourage further research to advance this capability.
AIGS: Generating Science from AI-Powered Automated Falsification
Nov 17, 2024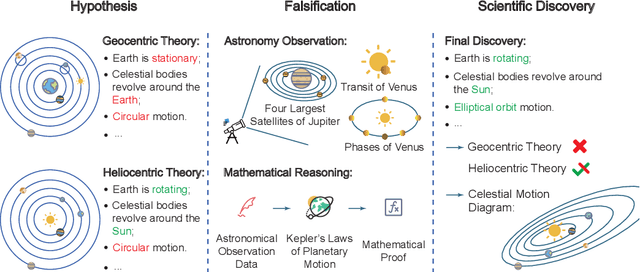

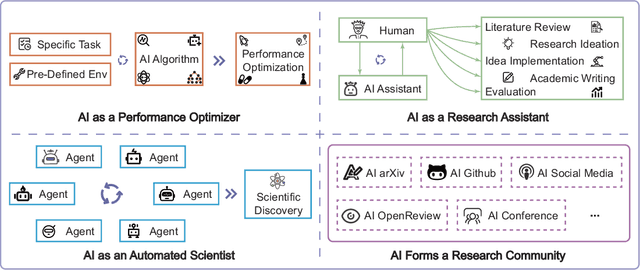

Rapid development of artificial intelligence has drastically accelerated the development of scientific discovery. Trained with large-scale observation data, deep neural networks extract the underlying patterns in an end-to-end manner and assist human researchers with highly-precised predictions in unseen scenarios. The recent rise of Large Language Models (LLMs) and the empowered autonomous agents enable scientists to gain help through interaction in different stages of their research, including but not limited to literature review, research ideation, idea implementation, and academic writing. However, AI researchers instantiated by foundation model empowered agents with full-process autonomy are still in their infancy. In this paper, we study $\textbf{AI-Generated Science}$ (AIGS), where agents independently and autonomously complete the entire research process and discover scientific laws. By revisiting the definition of scientific research, we argue that $\textit{falsification}$ is the essence of both human research process and the design of an AIGS system. Through the lens of falsification, prior systems attempting towards AI-Generated Science either lack the part in their design, or rely heavily on existing verification engines that narrow the use in specialized domains. In this work, we propose Baby-AIGS as a baby-step demonstration of a full-process AIGS system, which is a multi-agent system with agents in roles representing key research process. By introducing FalsificationAgent, which identify and then verify possible scientific discoveries, we empower the system with explicit falsification. Experiments on three tasks preliminarily show that Baby-AIGS could produce meaningful scientific discoveries, though not on par with experienced human researchers. Finally, we discuss on the limitations of current Baby-AIGS, actionable insights, and related ethical issues in detail.
Browse and Concentrate: Comprehending Multimodal Content via prior-LLM Context Fusion
Feb 19, 2024With the bloom of Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) that incorporate LLMs with pre-trained vision models have recently demonstrated impressive performance across diverse vision-language tasks. However, they fall short to comprehend context involving multiple images. A primary reason for this shortcoming is that the visual features for each images are encoded individually by frozen encoders before feeding into the LLM backbone, lacking awareness of other images and the multimodal instructions. We term this issue as prior-LLM modality isolation and propose a two phase paradigm, browse-and-concentrate, to enable in-depth multimodal context fusion prior to feeding the features into LLMs. This paradigm initially "browses" through the inputs for essential insights, and then revisits the inputs to "concentrate" on crucial details, guided by these insights, to achieve a more comprehensive understanding of the multimodal inputs. Additionally, we develop training strategies specifically to enhance the understanding of multi-image inputs. Our method markedly boosts the performance on 7 multi-image scenarios, contributing to increments on average accuracy by 2.13% and 7.60% against strong MLLMs baselines with 3B and 11B LLMs, respectively.