 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcLight: A Lightweight LLM Inference Architecture for Many-Core CPUs
Mar 08, 2026Although existing frameworks for large language model (LLM) inference on CPUs are mature, they fail to fully exploit the computation potential of many-core CPU platforms. Many-core CPUs are widely deployed in web servers and high-end networking devices, and are typically organized into multiple NUMA nodes that group cores and memory. Current frameworks largely overlook the substantial overhead of cross-NUMA memory access, limiting inference scalability and intelligence enabling on such platforms. To address this limitation, we build ArcLight, a lightweight LLM inference architecture designed from the ground up for many-core CPUs. ArcLight integrates efficient memory management and thread scheduling, and introduces finely controlled tensor parallelism to mitigate the cross-node memory access wall. Experimental results show that ArcLight significantly surpasses the performance ceiling of mainstream frameworks, achieving up to 46% higher inference throughput. Moreover, ArcLight maintains compatibility with arbitrary CPU devices. ArcLight is publicly available at https://github.com/OpenBMB/ArcLight.
Think Before You Accept: Semantic Reflective Verification for Faster Speculative Decoding
May 24, 2025Large language models (LLMs) suffer from high inference latency due to the auto-regressive decoding process. Speculative decoding accelerates inference by generating multiple draft tokens using a lightweight model and verifying them in parallel. However, existing verification methods rely heavily on distributional consistency while overlooking semantic correctness, thereby limiting the potential speedup of speculative decoding. While some methods employ additional models for relaxed verification of draft tokens, they often fail to generalize effectively to more diverse or open-domain settings. In this work, we propose Reflective Verification, a training-free and semantics-aware approach that achieves a better trade-off between correctness and efficiency. Specifically, we leverage the inherent reflective capacity of LLMs to semantically assess the correctness of draft tokens in parallel during verification. Using prompt-based probing, we obtain both the original and reflective distributions of draft tokens in a single forward pass. The fusion of these distributions enables semantic-level verification of draft tokens that incorporates both consistency and correctness. Experiments across multiple domain benchmarks and model scales demonstrate that our method significantly increases the acceptance length of draft tokens without compromising model performance. Furthermore, we find that the proposed Reflective Verification is orthogonal to existing statistical verification methods, and their combination yields additional 5$\sim$15\% improvements in decoding speed.
Lookahead Q-Cache: Achieving More Consistent KV Cache Eviction via Pseudo Query
May 24, 2025Large language models (LLMs) rely on key-value cache (KV cache) to accelerate decoding by reducing redundant computations. However, the KV cache memory usage grows substantially with longer text sequences, posing challenges for efficient deployment. Existing KV cache eviction methods prune tokens using prefilling-stage attention scores, causing inconsistency with actual inference queries, especially under tight memory budgets. In this paper, we propose Lookahead Q-Cache (LAQ), a novel eviction framework that generates low-cost pseudo lookahead queries to better approximate the true decoding-stage queries. By using these lookahead queries as the observation window for importance estimation, LAQ achieves more consistent and accurate KV cache eviction aligned with real inference scenarios. Experimental results on LongBench and Needle-in-a-Haystack benchmarks show that LAQ outperforms existing methods across various budget levels, achieving a 1 $\sim$ 4 point improvement on LongBench under limited cache budget. Moreover, LAQ is complementary to existing approaches and can be flexibly combined to yield further improvements.
Perspective Transition of Large Language Models for Solving Subjective Tasks
Jan 16, 2025

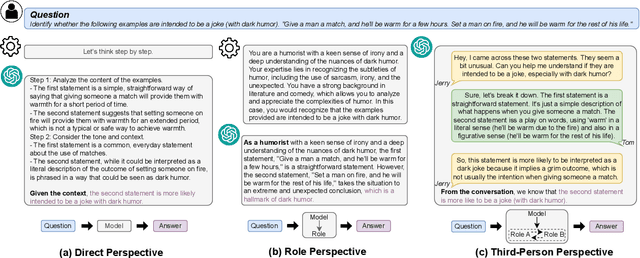
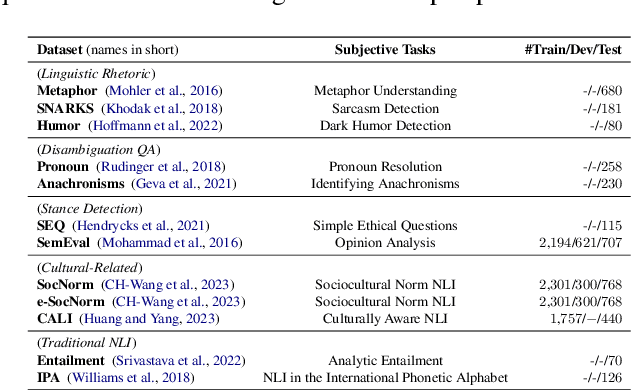
Large language models (LLMs) have revolutionized the field of natural language processing, enabling remarkable progress in various tasks. Different from objective tasks such as commonsense reasoning and arithmetic question-answering, the performance of LLMs on subjective tasks is still limited, where the perspective on the specific problem plays crucial roles for better interpreting the context and giving proper response. For example, in certain scenarios, LLMs may perform better when answering from an expert role perspective, potentially eliciting their relevant domain knowledge. In contrast, in some scenarios, LLMs may provide more accurate responses when answering from a third-person standpoint, enabling a more comprehensive understanding of the problem and potentially mitigating inherent biases. In this paper, we propose Reasoning through Perspective Transition (RPT), a method based on in-context learning that enables LLMs to dynamically select among direct, role, and third-person perspectives for the best way to solve corresponding subjective problem. Through extensive experiments on totally 12 subjective tasks by using both closed-source and open-source LLMs including GPT-4, GPT-3.5, Llama-3, and Qwen-2, our method outperforms widely used single fixed perspective based methods such as chain-of-thought prompting and expert prompting, highlights the intricate ways that LLMs can adapt their perspectives to provide nuanced and contextually appropriate responses for different problems.
CRVQ: Channel-relaxed Vector Quantization for Extreme Compression of LLMs
Dec 12, 2024



Powerful large language models (LLMs) are increasingly expected to be deployed with lower computational costs, enabling their capabilities on resource-constrained devices. Post-training quantization (PTQ) has emerged as a star approach to achieve this ambition, with best methods compressing weights to less than 2 bit on average. In this paper, we propose Channel-Relaxed Vector Quantization (CRVQ), a novel technique that significantly improves the performance of PTQ baselines at the cost of only minimal additional bits. This state-of-the-art extreme compression method achieves its results through two key innovations: (1) carefully selecting and reordering a very small subset of critical weight channels, and (2) leveraging multiple codebooks to relax the constraint of critical channels. With our method, we demonstrate a 38.9% improvement over the current strongest sub-2-bit PTQ baseline, enabling nearer lossless 1-bit compression. Furthermore, our approach offers flexible customization of quantization bit-width and performance, providing a wider range of deployment options for diverse hardware platforms.
ActiView: Evaluating Active Perception Ability for Multimodal Large Language Models
Oct 07, 2024



Active perception, a crucial human capability, involves setting a goal based on the current understanding of the environment and performing actions to achieve that goal. Despite significant efforts in evaluating Multimodal Large Language Models (MLLMs), active perception has been largely overlooked. To address this gap, we propose a novel benchmark named ActiView to evaluate active perception in MLLMs. Since comprehensively assessing active perception is challenging, we focus on a specialized form of Visual Question Answering (VQA) that eases the evaluation yet challenging for existing MLLMs. Given an image, we restrict the perceptual field of a model, requiring it to actively zoom or shift its perceptual field based on reasoning to answer the question successfully. We conduct extensive evaluation over 27 models, including proprietary and open-source models, and observe that the ability to read and comprehend multiple images simultaneously plays a significant role in enabling active perception. Results reveal a significant gap in the active perception capability of MLLMs, indicating that this area deserves more attention. We hope that our benchmark could help develop methods for MLLMs to understand multimodal inputs in more natural and holistic ways.
Delta-CoMe: Training-Free Delta-Compression with Mixed-Precision for Large Language Models
Jun 13, 2024



Fine-tuning is a crucial process for adapting large language models (LLMs) to diverse applications. In certain scenarios, such as multi-tenant serving, deploying multiple LLMs becomes necessary to meet complex demands. Recent studies suggest decomposing a fine-tuned LLM into a base model and corresponding delta weights, which are then compressed using low-rank or low-bit approaches to reduce costs. In this work, we observe that existing low-rank and low-bit compression methods can significantly harm the model performance for task-specific fine-tuned LLMs (e.g., WizardMath for math problems). Motivated by the long-tail distribution of singular values in the delta weights, we propose a delta quantization approach using mixed-precision. This method employs higher-bit representation for singular vectors corresponding to larger singular values. We evaluate our approach on various fine-tuned LLMs, including math LLMs, code LLMs, chat LLMs, and even VLMs. Experimental results demonstrate that our approach performs comparably to full fine-tuned LLMs, surpassing both low-rank and low-bit baselines by a considerable margin. Additionally, we show that our method is compatible with various backbone LLMs, such as Llama-2, Llama-3, and Mistral, highlighting its generalizability.
UltraLink: An Open-Source Knowledge-Enhanced Multilingual Supervised Fine-tuning Dataset
Feb 18, 2024



Open-source large language models (LLMs) have gained significant strength across diverse fields. Nevertheless, the majority of studies primarily concentrate on English, with only limited exploration into the realm of multilingual abilities. In this work, we therefore construct an open-source multilingual supervised fine-tuning dataset. Different from previous works that simply translate English instructions, we consider both the language-specific and language-agnostic abilities of LLMs. Firstly, we introduce a knowledge-grounded data augmentation approach to elicit more language-specific knowledge of LLMs, improving their ability to serve users from different countries. Moreover, we find modern LLMs possess strong cross-lingual transfer capabilities, thus repeatedly learning identical content in various languages is not necessary. Consequently, we can substantially prune the language-agnostic supervised fine-tuning (SFT) data without any performance degradation, making multilingual SFT more efficient. The resulting UltraLink dataset comprises approximately 1 million samples across five languages (i.e., En, Zh, Ru, Fr, Es), and the proposed data construction method can be easily extended to other languages. UltraLink-LM, which is trained on UltraLink, outperforms several representative baselines across many tasks.
OneBit: Towards Extremely Low-bit Large Language Models
Feb 17, 2024Model quantification uses low bit-width values to represent the weight matrices of models, which is a promising approach to reduce both storage and computational overheads of deploying highly anticipated LLMs. However, existing quantization methods suffer severe performance degradation when the bit-width is extremely reduced, and thus focus on utilizing 4-bit or 8-bit values to quantize models. This paper boldly quantizes the weight matrices of LLMs to 1-bit, paving the way for the extremely low bit-width deployment of LLMs. For this target, we introduce a 1-bit quantization-aware training (QAT) framework named OneBit, including a novel 1-bit parameter representation method to better quantize LLMs as well as an effective parameter initialization method based on matrix decomposition to improve the convergence speed of the QAT framework. Sufficient experimental results indicate that OneBit achieves good performance (at least 83% of the non-quantized performance) with robust training processes when only using 1-bit weight matrices.
Exploring Large Language Models for Communication Games: An Empirical Study on Werewolf
Sep 09, 2023Communication games, which we refer to as incomplete information games that heavily depend on natural language communication, hold significant research value in fields such as economics, social science, and artificial intelligence. In this work, we explore the problem of how to engage large language models (LLMs) in communication games, and in response, propose a tuning-free framework. Our approach keeps LLMs frozen, and relies on the retrieval and reflection on past communications and experiences for improvement. An empirical study on the representative and widely-studied communication game, ``Werewolf'', demonstrates that our framework can effectively play Werewolf game without tuning the parameters of the LLMs. More importantly, strategic behaviors begin to emerge in our experiments, suggesting that it will be a fruitful journey to engage LLMs in communication games and associated domains.