 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocle: Hybrid Local-Global In-Context Evaluation for Long-Text Generation with Uncertainty-Based Active Learning
May 27, 2025Assessing the quality of long-form, model-generated text is challenging, even with advanced LLM-as-a-Judge methods, due to performance degradation as input length increases. To address this issue, we propose a divide-and-conquer approach, which breaks down the comprehensive evaluation task into a series of localized scoring tasks, followed by a final global assessment. This strategy allows for more granular and manageable evaluations, ensuring that each segment of the text is assessed in isolation for both coherence and quality, while also accounting for the overall structure and consistency of the entire piece. Moreover, we introduce a hybrid in-context learning approach that leverages human annotations to enhance the performance of both local and global evaluations. By incorporating human-generated feedback directly into the evaluation process, this method allows the model to better align with human judgment. Finally, we develop an uncertainty-based active learning algorithm that efficiently selects data samples for human annotation, thereby reducing annotation costs in practical scenarios. Experimental results show that the proposed evaluation framework outperforms several representative baselines, highlighting the effectiveness of our approach.
Multi-Evidence based Fact Verification via A Confidential Graph Neural Network
May 17, 2024



Fact verification tasks aim to identify the integrity of textual contents according to the truthful corpus. Existing fact verification models usually build a fully connected reasoning graph, which regards claim-evidence pairs as nodes and connects them with edges. They employ the graph to propagate the semantics of the nodes. Nevertheless, the noisy nodes usually propagate their semantics via the edges of the reasoning graph, which misleads the semantic representations of other nodes and amplifies the noise signals. To mitigate the propagation of noisy semantic information, we introduce a Confidential Graph Attention Network (CO-GAT), which proposes a node masking mechanism for modeling the nodes. Specifically, CO-GAT calculates the node confidence score by estimating the relevance between the claim and evidence pieces. Then, the node masking mechanism uses the node confidence scores to control the noise information flow from the vanilla node to the other graph nodes. CO-GAT achieves a 73.59% FEVER score on the FEVER dataset and shows the generalization ability by broadening the effectiveness to the science-specific domain.
Cross-domain Chinese Sentence Pattern Parsing
Feb 27, 2024Sentence Pattern Structure (SPS) parsing is a syntactic analysis method primarily employed in language teaching.Existing SPS parsers rely heavily on textbook corpora for training, lacking cross-domain capability.To overcome this constraint, this paper proposes an innovative approach leveraging large language models (LLMs) within a self-training framework. Partial syntactic rules from a source domain are combined with target domain sentences to dynamically generate training data, enhancing the adaptability of the parser to diverse domains.Experiments conducted on textbook and news domains demonstrate the effectiveness of the proposed method, outperforming rule-based baselines by 1.68 points on F1 metrics.
OMGEval: An Open Multilingual Generative Evaluation Benchmark for Large Language Models
Feb 21, 2024
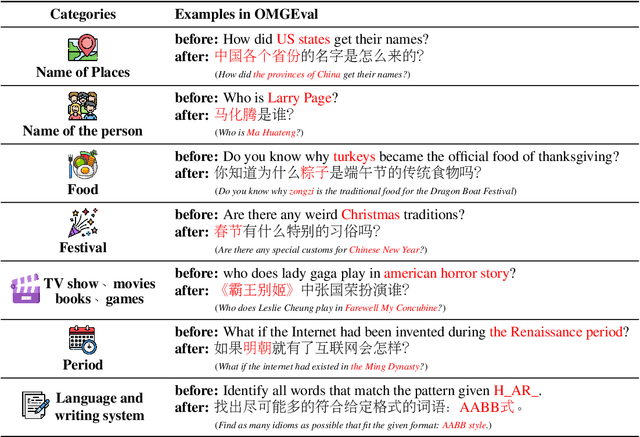

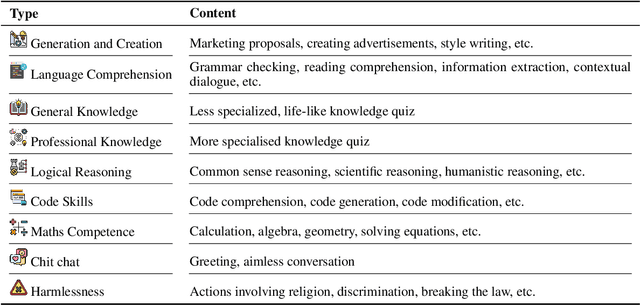
Modern large language models (LLMs) should generally benefit individuals from various cultural backgrounds around the world. However, most recent advanced generative evaluation benchmarks tailed for LLMs mainly focus on English. To this end, we introduce OMGEval, the first Open-source Multilingual Generative test set that can assess the capability of LLMs in different languages. For each language, OMGEval provides 804 open-ended questions, covering a wide range of important capabilities of LLMs, such as general knowledge, logical reasoning, and so on. Each question is rigorously verified by human annotators. Notably, to sufficiently reflect the compatibility of LLMs in different cultural backgrounds, we perform localization for each non-English language. Specifically, the current version of OMGEval includes 5 languages (i.e., Zh, Ru, Fr, Es, Ar). Following AlpacaEval, we employ GPT-4 as the adjudicator to automatically score different model outputs, which is shown closely related to human evaluation. We evaluate several representative multilingual LLMs on the proposed OMGEval, which we believe will provide a valuable reference for the community to further understand and improve the multilingual capability of LLMs. OMGEval is available at https://github.com/blcuicall/OMGEval.
UltraLink: An Open-Source Knowledge-Enhanced Multilingual Supervised Fine-tuning Dataset
Feb 18, 2024



Open-source large language models (LLMs) have gained significant strength across diverse fields. Nevertheless, the majority of studies primarily concentrate on English, with only limited exploration into the realm of multilingual abilities. In this work, we therefore construct an open-source multilingual supervised fine-tuning dataset. Different from previous works that simply translate English instructions, we consider both the language-specific and language-agnostic abilities of LLMs. Firstly, we introduce a knowledge-grounded data augmentation approach to elicit more language-specific knowledge of LLMs, improving their ability to serve users from different countries. Moreover, we find modern LLMs possess strong cross-lingual transfer capabilities, thus repeatedly learning identical content in various languages is not necessary. Consequently, we can substantially prune the language-agnostic supervised fine-tuning (SFT) data without any performance degradation, making multilingual SFT more efficient. The resulting UltraLink dataset comprises approximately 1 million samples across five languages (i.e., En, Zh, Ru, Fr, Es), and the proposed data construction method can be easily extended to other languages. UltraLink-LM, which is trained on UltraLink, outperforms several representative baselines across many tasks.
LegalDuet: Learning Effective Representations for Legal Judgment Prediction through a Dual-View Legal Clue Reasoning
Jan 27, 2024



Most existing Legal Judgment Prediction (LJP) models focus on discovering the legal triggers in the criminal fact description. However, in real-world scenarios, a professional judge not only needs to assimilate the law case experience that thrives on past sentenced legal judgments but also depends on the professional legal grounded reasoning that learned from professional legal knowledge. In this paper, we propose a LegalDuet model, which pretrains language models to learn a tailored embedding space for making legal judgments. It proposes a dual-view legal clue reasoning mechanism, which derives from two reasoning chains of judges: 1) Law Case Reasoning, which makes legal judgments according to the judgment experiences learned from analogy/confusing legal cases; 2) Legal Ground Reasoning, which lies in matching the legal clues between criminal cases and legal decisions. Our experiments show that LegalDuet achieves state-of-the-art performance on the CAIL2018 dataset and outperforms baselines with about 4% improvements on average. Our dual-view reasoning based pretraining can capture critical legal clues to learn a tailored embedding space to distinguish criminal cases. It reduces LegalDuet's uncertainty during prediction and brings pretraining advances to the confusing/low frequent charges. All codes are available at https://github.com/NEUIR/LegalDuet.
MCTS: A Multi-Reference Chinese Text Simplification Dataset
Jun 05, 2023Text simplification aims to make the text easier to understand by applying rewriting transformations. There has been very little research on Chinese text simplification for a long time. The lack of generic evaluation data is an essential reason for this phenomenon. In this paper, we introduce MCTS, a multi-reference Chinese text simplification dataset. We describe the annotation process of the dataset and provide a detailed analysis of it. Furthermore, we evaluate the performance of some unsupervised methods and advanced large language models. We hope to build a basic understanding of Chinese text simplification through the foundational work and provide references for future research. We release our data at https://github.com/blcuicall/mcts.
Cost-efficient Crowdsourcing for Span-based Sequence Labeling: Worker Selection and Data Augmentation
May 11, 2023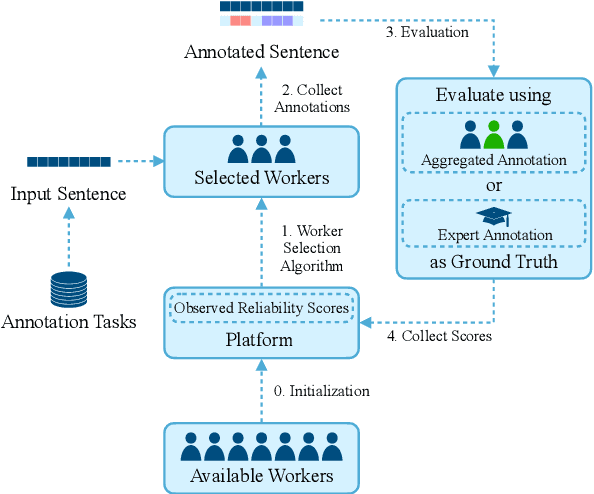

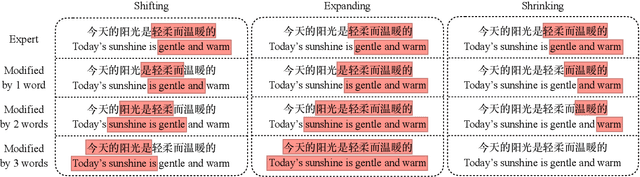
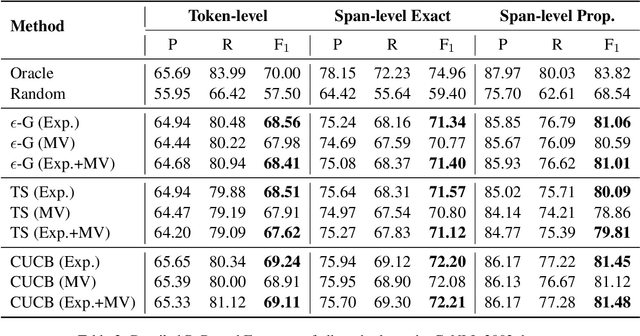
This paper introduces a novel worker selection algorithm, enhancing annotation quality and reducing costs in challenging span-based sequence labeling tasks in Natural Language Processing (NLP). Unlike previous studies targeting simpler tasks, this study contends with the complexities of label interdependencies in sequence labeling tasks. The proposed algorithm utilizes a Combinatorial Multi-Armed Bandit (CMAB) approach for worker selection. The challenge of dealing with imbalanced and small-scale datasets, which hinders offline simulation of worker selection, is tackled using an innovative data augmentation method termed shifting, expanding, and shrinking (SES). The SES method is designed specifically for sequence labeling tasks. Rigorous testing on CoNLL 2003 NER and Chinese OEI datasets showcased the algorithm's efficiency, with an increase in F1 score up to 100.04% of the expert-only baseline, alongside cost savings up to 65.97%. The paper also encompasses a dataset-independent test emulating annotation evaluation through a Bernoulli distribution, which still led to an impressive 97.56% F1 score of the expert baseline and 59.88% cost savings. This research addresses and overcomes numerous obstacles in worker selection for complex NLP tasks.
Lexical Complexity Controlled Sentence Generation
Nov 26, 2022Text generation rarely considers the control of lexical complexity, which limits its more comprehensive practical application. We introduce a novel task of lexical complexity controlled sentence generation, which aims at keywords to sentence generation with desired complexity levels. It has enormous potential in domains such as grade reading, language teaching and acquisition. The challenge of this task is to generate fluent sentences only using the words of given complexity levels. We propose a simple but effective approach for this task based on complexity embedding. Compared with potential solutions, our approach fuses the representations of the word complexity levels into the model to get better control of lexical complexity. And we demonstrate the feasibility of the approach for both training models from scratch and fine-tuning the pre-trained models. To facilitate the research, we develop two datasets in English and Chinese respectively, on which extensive experiments are conducted. Results show that our approach better controls lexical complexity and generates higher quality sentences than baseline methods.
COMPILING: A Benchmark Dataset for Chinese Complexity Controllable Definition Generation
Sep 29, 2022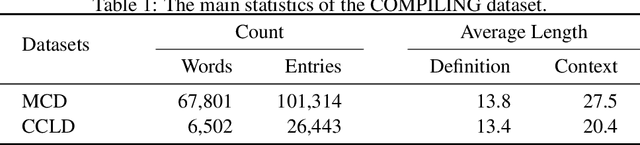
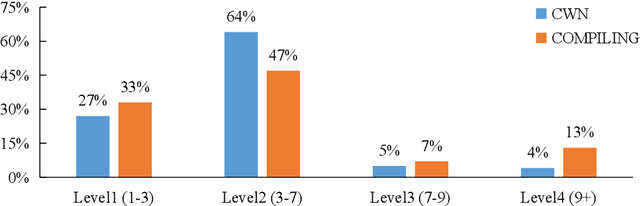
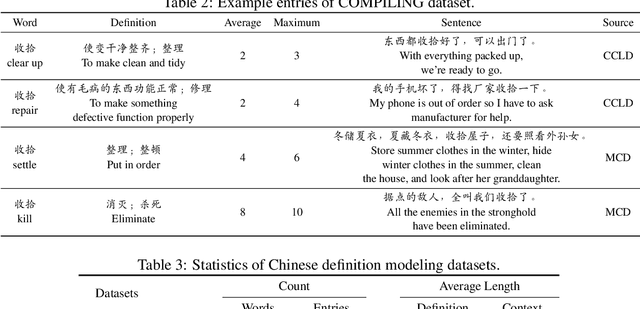
The definition generation task aims to generate a word's definition within a specific context automatically. However, owing to the lack of datasets for different complexities, the definitions produced by models tend to keep the same complexity level. This paper proposes a novel task of generating definitions for a word with controllable complexity levels. Correspondingly, we introduce COMPILING, a dataset given detailed information about Chinese definitions, and each definition is labeled with its complexity levels. The COMPILING dataset includes 74,303 words and 106,882 definitions. To the best of our knowledge, it is the largest dataset of the Chinese definition generation task. We select various representative generation methods as baselines for this task and conduct evaluations, which illustrates that our dataset plays an outstanding role in assisting models in generating different complexity-level definitions. We believe that the COMPILING dataset will benefit further research in complexity controllable definition generation.