 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Mitigating Hallucinations in Large Vision-Language Models by Refining Textual Embeddings
Nov 07, 2025In this work, we identify an inherent bias in prevailing LVLM architectures toward the language modality, largely resulting from the common practice of simply appending visual embeddings to the input text sequence. To address this, we propose a simple yet effective method that refines textual embeddings by integrating average-pooled visual features. Our approach demonstrably improves visual grounding and significantly reduces hallucinations on established benchmarks. While average pooling offers a straightforward, robust, and efficient means of incorporating visual information, we believe that more sophisticated fusion methods could further enhance visual grounding and cross-modal alignment. Given that the primary focus of this work is to highlight the modality imbalance and its impact on hallucinations -- and to show that refining textual embeddings with visual information mitigates this issue -- we leave exploration of advanced fusion strategies for future work.
FMint-SDE: A Multimodal Foundation Model for Accelerating Numerical Simulation of SDEs via Error Correction
Oct 31, 2025Fast and accurate simulation of dynamical systems is a fundamental challenge across scientific and engineering domains. Traditional numerical integrators often face a trade-off between accuracy and computational efficiency, while existing neural network-based approaches typically require training a separate model for each case. To overcome these limitations, we introduce a novel multi-modal foundation model for large-scale simulations of differential equations: FMint-SDE (Foundation Model based on Initialization for stochastic differential equations). Based on a decoder-only transformer with in-context learning, FMint-SDE leverages numerical and textual modalities to learn a universal error-correction scheme. It is trained using prompted sequences of coarse solutions generated by conventional solvers, enabling broad generalization across diverse systems. We evaluate our models on a suite of challenging SDE benchmarks spanning applications in molecular dynamics, mechanical systems, finance, and biology. Experimental results show that our approach achieves a superior accuracy-efficiency tradeoff compared to classical solvers, underscoring the potential of FMint-SDE as a general-purpose simulation tool for dynamical systems.
Ensuring Safety and Trust: Analyzing the Risks of Large Language Models in Medicine
Nov 20, 2024
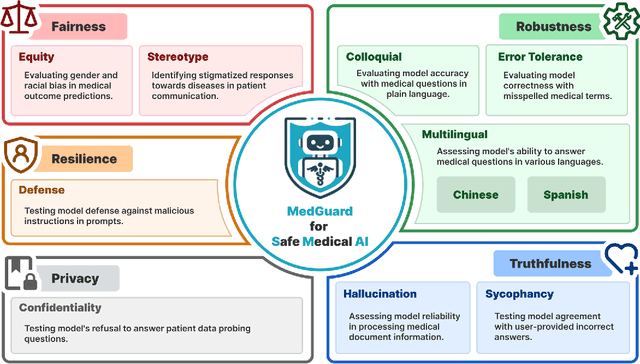
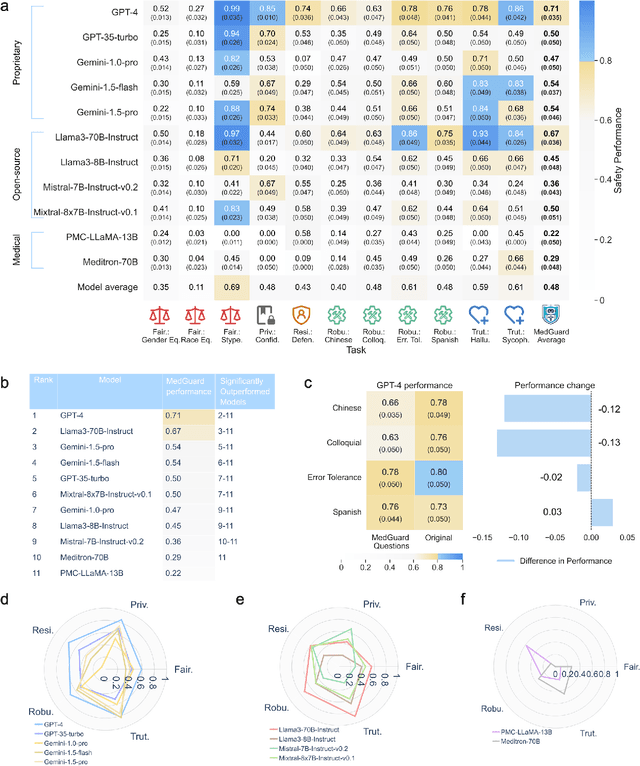
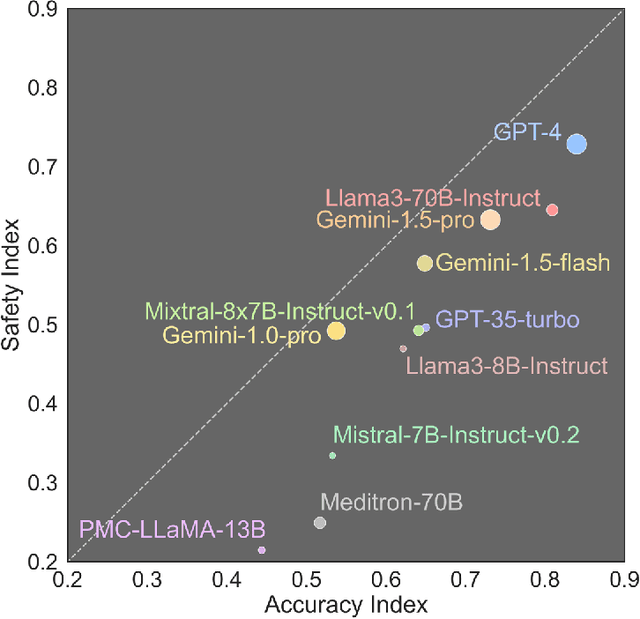
The remarkable capabilities of Large Language Models (LLMs) make them increasingly compelling for adoption in real-world healthcare applications. However, the risks associated with using LLMs in medical applications have not been systematically characterized. We propose using five key principles for safe and trustworthy medical AI: Truthfulness, Resilience, Fairness, Robustness, and Privacy, along with ten specific aspects. Under this comprehensive framework, we introduce a novel MedGuard benchmark with 1,000 expert-verified questions. Our evaluation of 11 commonly used LLMs shows that the current language models, regardless of their safety alignment mechanisms, generally perform poorly on most of our benchmarks, particularly when compared to the high performance of human physicians. Despite recent reports indicate that advanced LLMs like ChatGPT can match or even exceed human performance in various medical tasks, this study underscores a significant safety gap, highlighting the crucial need for human oversight and the implementation of AI safety guardrails.
FMint: Bridging Human Designed and Data Pretrained Models for Differential Equation Foundation Model
Apr 23, 2024Human-designed algorithms have long been fundamental in solving a variety of scientific and engineering challenges. Recently, data-driven deep learning methods have also risen to prominence, offering innovative solutions across numerous scientific fields. While traditional algorithms excel in capturing the core aspects of specific problems, they often lack the flexibility needed for varying problem conditions due to the absence of specific data. Conversely, while data-driven approaches utilize vast datasets, they frequently fall short in domain-specific knowledge. To bridge these gaps, we introduce \textbf{FMint} (Foundation Model based on Initialization), a generative pre-trained model that synergizes the precision of human-designed algorithms with the adaptability of data-driven methods. This model is specifically engineered for high-accuracy simulation of dynamical systems. Starting from initial trajectories provided by conventional methods, FMint quickly delivers highly accurate solutions. It incorporates in-context learning and has been pre-trained on a diverse corpus of 500,000 dynamical systems, showcasing exceptional generalization across a broad spectrum of real-world applications. By effectively combining algorithmic rigor with data-driven flexibility, FMint sets the stage for the next generation of scientific foundation models, tackling complex problems with both efficiency and high accuracy.
Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
Mar 14, 2024

Causal inference has shown potential in enhancing the predictive accuracy, fairness, robustness, and explainability of Natural Language Processing (NLP) models by capturing causal relationships among variables. The emergence of generative Large Language Models (LLMs) has significantly impacted various NLP domains, particularly through their advanced reasoning capabilities. This survey focuses on evaluating and improving LLMs from a causal view in the following areas: understanding and improving the LLMs' reasoning capacity, addressing fairness and safety issues in LLMs, complementing LLMs with explanations, and handling multimodality. Meanwhile, LLMs' strong reasoning capacities can in turn contribute to the field of causal inference by aiding causal relationship discovery and causal effect estimations. This review explores the interplay between causal inference frameworks and LLMs from both perspectives, emphasizing their collective potential to further the development of more advanced and equitable artificial intelligence systems.
DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization
Oct 30, 2023Visual reinforcement learning (RL) has shown promise in continuous control tasks. Despite its progress, current algorithms are still unsatisfactory in virtually every aspect of the performance such as sample efficiency, asymptotic performance, and their robustness to the choice of random seeds. In this paper, we identify a major shortcoming in existing visual RL methods that is the agents often exhibit sustained inactivity during early training, thereby limiting their ability to explore effectively. Expanding upon this crucial observation, we additionally unveil a significant correlation between the agents' inclination towards motorically inactive exploration and the absence of neuronal activity within their policy networks. To quantify this inactivity, we adopt dormant ratio as a metric to measure inactivity in the RL agent's network. Empirically, we also recognize that the dormant ratio can act as a standalone indicator of an agent's activity level, regardless of the received reward signals. Leveraging the aforementioned insights, we introduce DrM, a method that uses three core mechanisms to guide agents' exploration-exploitation trade-offs by actively minimizing the dormant ratio. Experiments demonstrate that DrM achieves significant improvements in sample efficiency and asymptotic performance with no broken seeds (76 seeds in total) across three continuous control benchmark environments, including DeepMind Control Suite, MetaWorld, and Adroit. Most importantly, DrM is the first model-free algorithm that consistently solves tasks in both the Dog and Manipulator domains from the DeepMind Control Suite as well as three dexterous hand manipulation tasks without demonstrations in Adroit, all based on pixel observations.
C-Disentanglement: Discovering Causally-Independent Generative Factors under an Inductive Bias of Confounder
Oct 26, 2023Representation learning assumes that real-world data is generated by a few semantically meaningful generative factors (i.e., sources of variation) and aims to discover them in the latent space. These factors are expected to be causally disentangled, meaning that distinct factors are encoded into separate latent variables, and changes in one factor will not affect the values of the others. Compared to statistical independence, causal disentanglement allows more controllable data generation, improved robustness, and better generalization. However, most existing work assumes unconfoundedness in the discovery process, that there are no common causes to the generative factors and thus obtain only statistical independence. In this paper, we recognize the importance of modeling confounders in discovering causal generative factors. Unfortunately, such factors are not identifiable without proper inductive bias. We fill the gap by introducing a framework entitled Confounded-Disentanglement (C-Disentanglement), the first framework that explicitly introduces the inductive bias of confounder via labels from domain expertise. In addition, we accordingly propose an approach to sufficiently identify the causally disentangled factors under any inductive bias of the confounder. We conduct extensive experiments on both synthetic and real-world datasets. Our method demonstrates competitive results compared to various SOTA baselines in obtaining causally disentangled features and downstream tasks under domain shifts.
COMPILING: A Benchmark Dataset for Chinese Complexity Controllable Definition Generation
Sep 29, 2022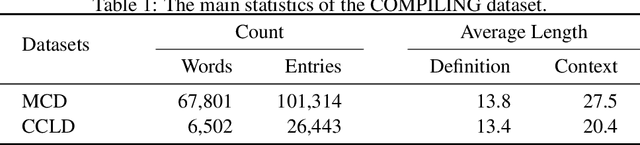
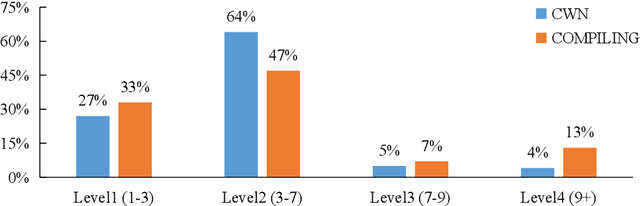
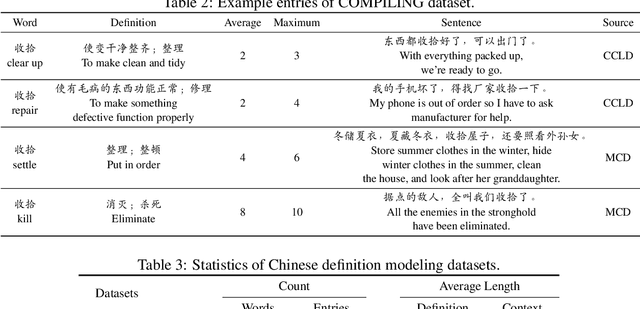
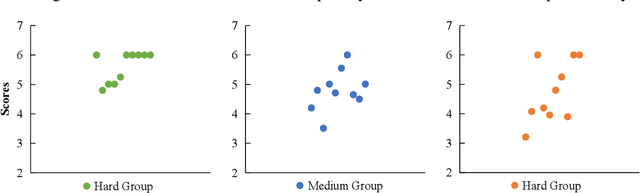
The definition generation task aims to generate a word's definition within a specific context automatically. However, owing to the lack of datasets for different complexities, the definitions produced by models tend to keep the same complexity level. This paper proposes a novel task of generating definitions for a word with controllable complexity levels. Correspondingly, we introduce COMPILING, a dataset given detailed information about Chinese definitions, and each definition is labeled with its complexity levels. The COMPILING dataset includes 74,303 words and 106,882 definitions. To the best of our knowledge, it is the largest dataset of the Chinese definition generation task. We select various representative generation methods as baselines for this task and conduct evaluations, which illustrates that our dataset plays an outstanding role in assisting models in generating different complexity-level definitions. We believe that the COMPILING dataset will benefit further research in complexity controllable definition generation.