 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkRouter: Efficient Reasoning via Routing Thinking between Latent and Discrete Spaces
Feb 12, 2026Recent work explores latent reasoning to improve reasoning efficiency by replacing explicit reasoning trajectories with continuous representations in a latent space, yet its effectiveness varies across settings. Analysis of model confidence dynamics under latent reasoning reveals that thinking trajectories ending in incorrect answers contain fewer low-confidence steps than those ending in correct answers. Meanwhile, we suggest that soft embeddings aggregated by multiple low-confidence thinking alternatives may introduce and propagate noise, leading to high confidence in unreliable reasoning trajectories. Motivated by these observations, ThinkRouter, an inference-time confidence-aware routing mechanism is proposed to avoid high confidence and noise for efficient reasoning. ThinkRouter routes thinking to the discrete token space when model confidence is low, and to the latent space otherwise. Extensive experiments on STEM reasoning and coding benchmarks across diverse large reasoning models demonstrate that ThinkRouter outperforms explicit CoT, random routing, and latent reasoning baselines in terms of accuracy, achieving an average improvement of 19.70 points in Pass@1, while reducing generation length by up to 15.55%. Further comprehensive analysis reveals that ThinkRouter can calibrate errors arising from explicit CoT and latent reasoning, and accelerates end-of-thinking token generation by globally lowering model confidence.
Gesturing Toward Abstraction: Multimodal Convention Formation in Collaborative Physical Tasks
Feb 09, 2026A quintessential feature of human intelligence is the ability to create ad hoc conventions over time to achieve shared goals efficiently. We investigate how communication strategies evolve through repeated collaboration as people coordinate on shared procedural abstractions. To this end, we conducted an online unimodal study (n = 98) using natural language to probe abstraction hierarchies. In a follow-up lab study (n = 40), we examined how multimodal communication (speech and gestures) changed during physical collaboration. Pairs used augmented reality to isolate their partner's hand and voice; one participant viewed a 3D virtual tower and sent instructions to the other, who built the physical tower. Participants became faster and more accurate by establishing linguistic and gestural abstractions and using cross-modal redundancy to emphasize key changes from previous interactions. Based on these findings, we extend probabilistic models of convention formation to multimodal settings, capturing shifts in modality preferences. Our findings and model provide building blocks for designing convention-aware intelligent agents situated in the physical world.
* Accepted at the 2026 CHI Conference on Human Factors in Computing Systems (CHI 2026). 15 pages
Atom: Efficient On-Device Video-Language Pipelines Through Modular Reuse
Dec 18, 2025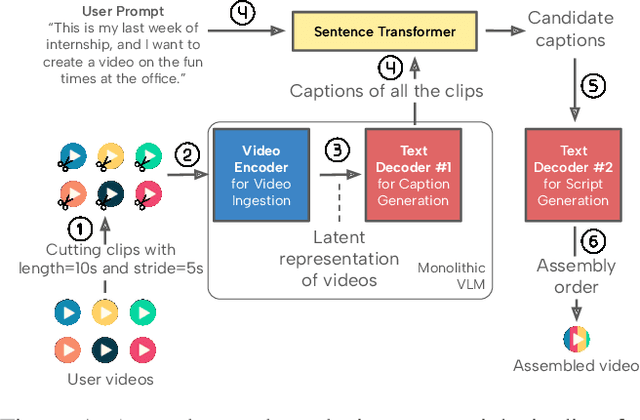
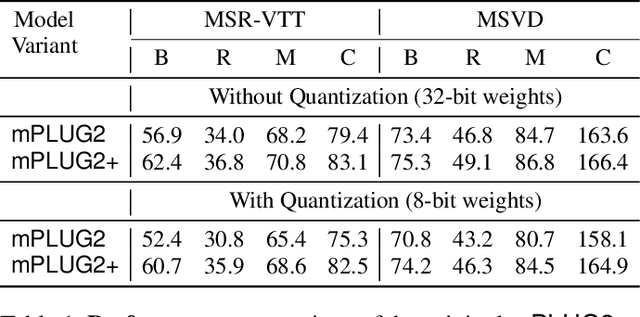
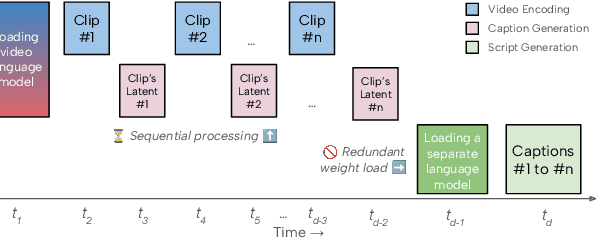
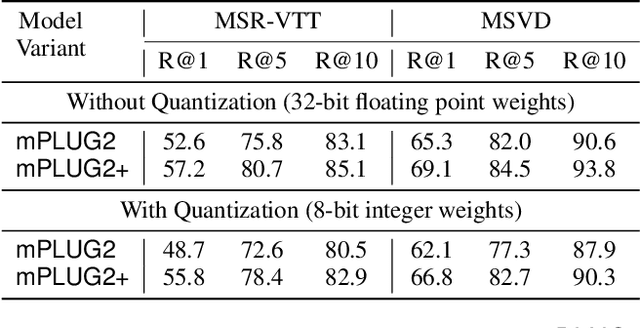
Recent advances in video-language models have enabled powerful applications like video retrieval, captioning, and assembly. However, executing such multi-stage pipelines efficiently on mobile devices remains challenging due to redundant model loads and fragmented execution. We introduce Atom, an on-device system that restructures video-language pipelines for fast and efficient execution. Atom decomposes a billion-parameter model into reusable modules, such as the visual encoder and language decoder, and reuses them across subtasks like captioning, reasoning, and indexing. This reuse-centric design eliminates repeated model loading and enables parallel execution, reducing end-to-end latency without sacrificing performance. On commodity smartphones, Atom achieves 27--33% faster execution compared to non-reuse baselines, with only marginal performance drop ($\leq$ 2.3 Recall@1 in retrieval, $\leq$ 1.5 CIDEr in captioning). These results position Atom as a practical, scalable approach for efficient video-language understanding on edge devices.
DistrAttention: An Efficient and Flexible Self-Attention Mechanism on Modern GPUs
Jul 23, 2025The Transformer architecture has revolutionized deep learning, delivering the state-of-the-art performance in areas such as natural language processing, computer vision, and time series prediction. However, its core component, self-attention, has the quadratic time complexity relative to input sequence length, which hinders the scalability of Transformers. The exsiting approaches on optimizing self-attention either discard full-contextual information or lack of flexibility. In this work, we design DistrAttention, an effcient and flexible self-attention mechanism with the full context. DistrAttention achieves this by grouping data on the embedding dimensionality, usually referred to as $d$. We realize DistrAttention with a lightweight sampling and fusion method that exploits locality-sensitive hashing to group similar data. A block-wise grouping framework is further designed to limit the errors introduced by locality sensitive hashing. By optimizing the selection of block sizes, DistrAttention could be easily integrated with FlashAttention-2, gaining high-performance on modern GPUs. We evaluate DistrAttention with extensive experiments. The results show that our method is 37% faster than FlashAttention-2 on calculating self-attention. In ViT inference, DistrAttention is the fastest and the most accurate among approximate self-attention mechanisms. In Llama3-1B, DistrAttention still achieves the lowest inference time with only 1% accuray loss.
Feature-Space Semantic Invariance: Enhanced OOD Detection for Open-Set Domain Generalization
Nov 11, 2024Open-set domain generalization addresses a real-world challenge: training a model to generalize across unseen domains (domain generalization) while also detecting samples from unknown classes not encountered during training (open-set recognition). However, most existing approaches tackle these issues separately, limiting their practical applicability. To overcome this limitation, we propose a unified framework for open-set domain generalization by introducing Feature-space Semantic Invariance (FSI). FSI maintains semantic consistency across different domains within the feature space, enabling more accurate detection of OOD instances in unseen domains. Additionally, we adopt a generative model to produce synthetic data with novel domain styles or class labels, enhancing model robustness. Initial experiments show that our method improves AUROC by 9.1% to 18.9% on ColoredMNIST, while also significantly increasing in-distribution classification accuracy.
FEED: Fairness-Enhanced Meta-Learning for Domain Generalization
Nov 02, 2024



Generalizing to out-of-distribution data while being aware of model fairness is a significant and challenging problem in meta-learning. The goal of this problem is to find a set of fairness-aware invariant parameters of classifier that is trained using data drawn from a family of related training domains with distribution shift on non-sensitive features as well as different levels of dependence between model predictions and sensitive features so that the classifier can achieve good generalization performance on unknown but distinct test domains. To tackle this challenge, existing state-of-the-art methods either address the domain generalization problem but completely ignore learning with fairness or solely specify shifted domains with various fairness levels. This paper introduces an approach to fairness-aware meta-learning that significantly enhances domain generalization capabilities. Our framework, Fairness-Enhanced Meta-Learning for Domain Generalization (FEED), disentangles latent data representations into content, style, and sensitive vectors. This disentanglement facilitates the robust generalization of machine learning models across diverse domains while adhering to fairness constraints. Unlike traditional methods that focus primarily on domain invariance or sensitivity to shifts, our model integrates a fairness-aware invariance criterion directly into the meta-learning process. This integration ensures that the learned parameters uphold fairness consistently, even when domain characteristics vary widely. We validate our approach through extensive experiments across multiple benchmarks, demonstrating not only superior performance in maintaining high accuracy and fairness but also significant improvements over existing state-of-the-art methods in domain generalization tasks.
MADOD: Generalizing OOD Detection to Unseen Domains via G-Invariance Meta-Learning
Nov 02, 2024Real-world machine learning applications often face simultaneous covariate and semantic shifts, challenging traditional domain generalization and out-of-distribution (OOD) detection methods. We introduce Meta-learned Across Domain Out-of-distribution Detection (MADOD), a novel framework designed to address both shifts concurrently. MADOD leverages meta-learning and G-invariance to enhance model generalizability and OOD detection in unseen domains. Our key innovation lies in task construction: we randomly designate in-distribution classes as pseudo-OODs within each meta-learning task, simulating OOD scenarios using existing data. This approach, combined with energy-based regularization, enables the learning of robust, domain-invariant features while calibrating decision boundaries for effective OOD detection. Operating in a test domain-agnostic setting, MADOD eliminates the need for adaptation during inference, making it suitable for scenarios where test data is unavailable. Extensive experiments on real-world and synthetic datasets demonstrate MADOD's superior performance in semantic OOD detection across unseen domains, achieving an AUPR improvement of 8.48% to 20.81%, while maintaining competitive in-distribution classification accuracy, representing a significant advancement in handling both covariate and semantic shifts.
Knowledge-Aware Query Expansion with Large Language Models for Textual and Relational Retrieval
Oct 17, 2024



Large language models (LLMs) have been used to generate query expansions augmenting original queries for improving information search. Recent studies also explore providing LLMs with initial retrieval results to generate query expansions more grounded to document corpus. However, these methods mostly focus on enhancing textual similarities between search queries and target documents, overlooking document relations. For queries like "Find me a highly rated camera for wildlife photography compatible with my Nikon F-Mount lenses", existing methods may generate expansions that are semantically similar but structurally unrelated to user intents. To handle such semi-structured queries with both textual and relational requirements, in this paper we propose a knowledge-aware query expansion framework, augmenting LLMs with structured document relations from knowledge graph (KG). To further address the limitation of entity-based scoring in existing KG-based methods, we leverage document texts as rich KG node representations and use document-based relation filtering for our Knowledge-Aware Retrieval (KAR). Extensive experiments on three datasets of diverse domains show the advantages of our method compared against state-of-the-art baselines on textual and relational semi-structured retrieval.
Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
Mar 14, 2024

Causal inference has shown potential in enhancing the predictive accuracy, fairness, robustness, and explainability of Natural Language Processing (NLP) models by capturing causal relationships among variables. The emergence of generative Large Language Models (LLMs) has significantly impacted various NLP domains, particularly through their advanced reasoning capabilities. This survey focuses on evaluating and improving LLMs from a causal view in the following areas: understanding and improving the LLMs' reasoning capacity, addressing fairness and safety issues in LLMs, complementing LLMs with explanations, and handling multimodality. Meanwhile, LLMs' strong reasoning capacities can in turn contribute to the field of causal inference by aiding causal relationship discovery and causal effect estimations. This review explores the interplay between causal inference frameworks and LLMs from both perspectives, emphasizing their collective potential to further the development of more advanced and equitable artificial intelligence systems.
VaQuitA: Enhancing Alignment in LLM-Assisted Video Understanding
Dec 04, 2023



Recent advancements in language-model-based video understanding have been progressing at a remarkable pace, spurred by the introduction of Large Language Models (LLMs). However, the focus of prior research has been predominantly on devising a projection layer that maps video features to tokens, an approach that is both rudimentary and inefficient. In our study, we introduce a cutting-edge framework, VaQuitA, designed to refine the synergy between video and textual information. At the data level, instead of sampling frames uniformly, we implement a sampling method guided by CLIP-score rankings, which enables a more aligned selection of frames with the given question. At the feature level, we integrate a trainable Video Perceiver alongside a Visual-Query Transformer (abbreviated as VQ-Former), which bolsters the interplay between the input question and the video features. We also discover that incorporating a simple prompt, "Please be critical", into the LLM input can substantially enhance its video comprehension capabilities. Our experimental results indicate that VaQuitA consistently sets a new benchmark for zero-shot video question-answering tasks and is adept at producing high-quality, multi-turn video dialogues with users.