 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Similarity is a Spurious Measure of Comic Understanding: Lessons Learned from Hallucinations in a Benchmarking Experiment
Mar 02, 2026A system that enables blind or visually impaired users to access comics/manga would introduce a new medium of storytelling to this community. However, no such system currently exists. Generative vision-language models (VLMs) have shown promise in describing images and understanding comics, but most research on comic understanding is limited to panel-level analysis. To fully support blind and visually impaired users, greater attention must be paid to page-level understanding and interpretation. In this work, we present a preliminary benchmark of VLM performance on comic interpretation tasks. We identify and categorize hallucinations that emerge during this process, organizing them into generalized object-hallucination taxonomies. We conclude with guidance on future research, emphasizing hallucination mitigation and improved data curation for comic interpretation.
RISE: Interactive Visual Diagnosis of Fairness in Machine Learning Models
Feb 04, 2026Evaluating fairness under domain shift is challenging because scalar metrics often obscure exactly where and how disparities arise. We introduce \textit{RISE} (Residual Inspection through Sorted Evaluation), an interactive visualization tool that converts sorted residuals into interpretable patterns. By connecting residual curve structures to formal fairness notions, RISE enables localized disparity diagnosis, subgroup comparison across environments, and the detection of hidden fairness issues. Through post-hoc analysis, RISE exposes accuracy-fairness trade-offs that aggregate statistics miss, supporting more informed model selection.
Improving Indigenous Language Machine Translation with Synthetic Data and Language-Specific Preprocessing
Jan 06, 2026Low-resource indigenous languages often lack the parallel corpora required for effective neural machine translation (NMT). Synthetic data generation offers a practical strategy for mitigating this limitation in data-scarce settings. In this work, we augment curated parallel datasets for indigenous languages of the Americas with synthetic sentence pairs generated using a high-capacity multilingual translation model. We fine-tune a multilingual mBART model on curated-only and synthetically augmented data and evaluate translation quality using chrF++, the primary metric used in recent AmericasNLP shared tasks for agglutinative languages. We further apply language-specific preprocessing, including orthographic normalization and noise-aware filtering, to reduce corpus artifacts. Experiments on Guarani--Spanish and Quechua--Spanish translation show consistent chrF++ improvements from synthetic data augmentation, while diagnostic experiments on Aymara highlight the limitations of generic preprocessing for highly agglutinative languages.
MultiScript30k: Leveraging Multilingual Embeddings to Extend Cross Script Parallel Data
Dec 11, 2025Multi30k is frequently cited in the multimodal machine translation (MMT) literature, offering parallel text data for training and fine-tuning deep learning models. However, it is limited to four languages: Czech, English, French, and German. This restriction has led many researchers to focus their investigations only on these languages. As a result, MMT research on diverse languages has been stalled because the official Multi30k dataset only represents European languages in Latin scripts. Previous efforts to extend Multi30k exist, but the list of supported languages, represented language families, and scripts is still very short. To address these issues, we propose MultiScript30k, a new Multi30k dataset extension for global languages in various scripts, created by translating the English version of Multi30k (Multi30k-En) using NLLB200-3.3B. The dataset consists of over \(30000\) sentences and provides translations of all sentences in Multi30k-En into Ar, Es, Uk, Zh\_Hans and Zh\_Hant. Similarity analysis shows that Multi30k extension consistently achieves greater than \(0.8\) cosine similarity and symmetric KL divergence less than \(0.000251\) for all languages supported except Zh\_Hant which is comparable to the previous Multi30k extensions ArEnMulti30k and Multi30k-Uk. COMETKiwi scores reveal mixed assessments of MultiScript30k as a translation of Multi30k-En in comparison to the related work. ArEnMulti30k scores nearly equal MultiScript30k-Ar, but Multi30k-Uk scores $6.4\%$ greater than MultiScript30k-Uk per split.
M3: A Multi-Task Mixed-Objective Learning Framework for Open-Domain Multi-Hop Dense Sentence Retrieval
Mar 21, 2024In recent research, contrastive learning has proven to be a highly effective method for representation learning and is widely used for dense retrieval. However, we identify that relying solely on contrastive learning can lead to suboptimal retrieval performance. On the other hand, despite many retrieval datasets supporting various learning objectives beyond contrastive learning, combining them efficiently in multi-task learning scenarios can be challenging. In this paper, we introduce M3, an advanced recursive Multi-hop dense sentence retrieval system built upon a novel Multi-task Mixed-objective approach for dense text representation learning, addressing the aforementioned challenges. Our approach yields state-of-the-art performance on a large-scale open-domain fact verification benchmark dataset, FEVER. Code and data are available at: https://github.com/TonyBY/M3
Fairness-Aware Domain Generalization under Covariate and Dependence Shifts
Nov 23, 2023


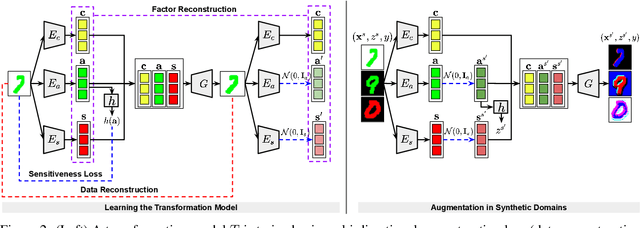
Achieving the generalization of an invariant classifier from source domains to shifted target domains while simultaneously considering model fairness is a substantial and complex challenge in machine learning. Existing domain generalization research typically attributes domain shifts to concept shift, which relates to alterations in class labels, and covariate shift, which pertains to variations in data styles. In this paper, by introducing another form of distribution shift, known as dependence shift, which involves variations in fair dependence patterns across domains, we propose a novel domain generalization approach that addresses domain shifts by considering both covariate and dependence shifts. We assert the existence of an underlying transformation model can transform data from one domain to another. By generating data in synthetic domains through the model, a fairness-aware invariant classifier is learned that enforces both model accuracy and fairness in unseen domains. Extensive empirical studies on four benchmark datasets demonstrate that our approach surpasses state-of-the-art methods.
Towards Fair Disentangled Online Learning for Changing Environments
May 31, 2023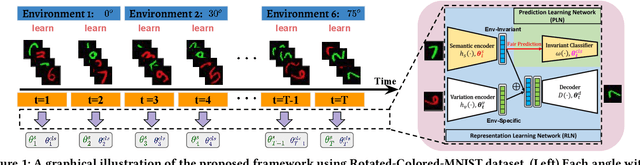
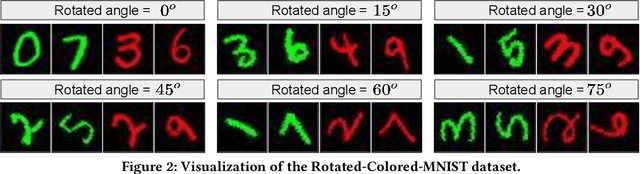

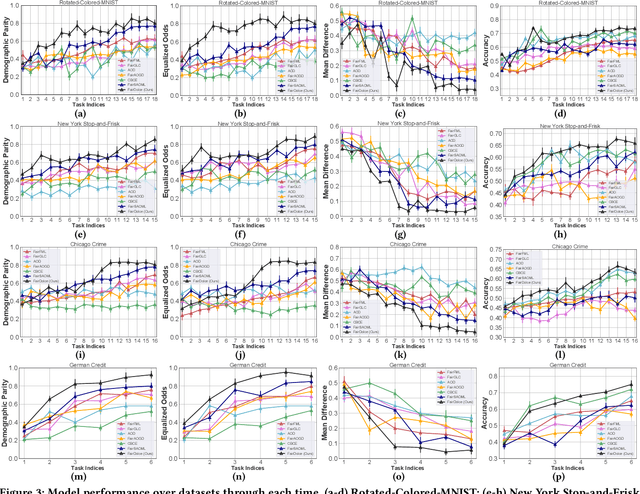
In the problem of online learning for changing environments, data are sequentially received one after another over time, and their distribution assumptions may vary frequently. Although existing methods demonstrate the effectiveness of their learning algorithms by providing a tight bound on either dynamic regret or adaptive regret, most of them completely ignore learning with model fairness, defined as the statistical parity across different sub-population (e.g., race and gender). Another drawback is that when adapting to a new environment, an online learner needs to update model parameters with a global change, which is costly and inefficient. Inspired by the sparse mechanism shift hypothesis, we claim that changing environments in online learning can be attributed to partial changes in learned parameters that are specific to environments and the rest remain invariant to changing environments. To this end, in this paper, we propose a novel algorithm under the assumption that data collected at each time can be disentangled with two representations, an environment-invariant semantic factor and an environment-specific variation factor. The semantic factor is further used for fair prediction under a group fairness constraint. To evaluate the sequence of model parameters generated by the learner, a novel regret is proposed in which it takes a mixed form of dynamic and static regret metrics followed by a fairness-aware long-term constraint. The detailed analysis provides theoretical guarantees for loss regret and violation of cumulative fairness constraints. Empirical evaluations on real-world datasets demonstrate our proposed method sequentially outperforms baseline methods in model accuracy and fairness.
Proposing an Interactive Audit Pipeline for Visual Privacy Research
Nov 24, 2021



In an ideal world, deployed machine learning models will enhance our society. We hope that those models will provide unbiased and ethical decisions that will benefit everyone. However, this is not always the case; issues arise during the data preparation process throughout the steps leading to the models' deployment. The continued use of biased datasets and processes will adversely damage communities and increase the cost of fixing the problem later. In this work, we walk through the decision-making process that a researcher should consider before, during, and after a system deployment to understand the broader impacts of their research in the community. Throughout this paper, we discuss fairness, privacy, and ownership issues in the machine learning pipeline; we assert the need for a responsible human-over-the-loop methodology to bring accountability into the machine learning pipeline, and finally, reflect on the need to explore research agendas that have harmful societal impacts. We examine visual privacy research and draw lessons that can apply broadly to artificial intelligence. Our goal is to systematically analyze the machine learning pipeline for visual privacy and bias issues. We hope to raise stakeholder (e.g., researchers, modelers, corporations) awareness as these issues propagate in this pipeline's various machine learning phases.
AdaTag: Multi-Attribute Value Extraction from Product Profiles with Adaptive Decoding
Jun 04, 2021

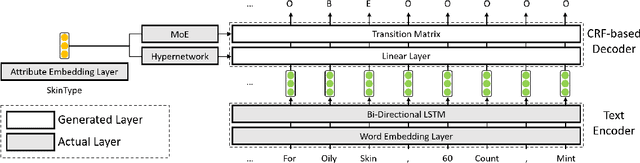
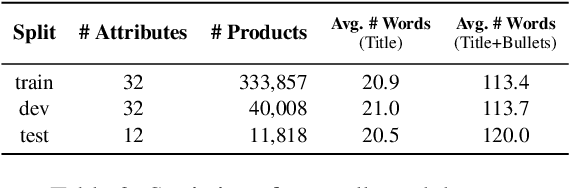
Automatic extraction of product attribute values is an important enabling technology in e-Commerce platforms. This task is usually modeled using sequence labeling architectures, with several extensions to handle multi-attribute extraction. One line of previous work constructs attribute-specific models, through separate decoders or entirely separate models. However, this approach constrains knowledge sharing across different attributes. Other contributions use a single multi-attribute model, with different techniques to embed attribute information. But sharing the entire network parameters across all attributes can limit the model's capacity to capture attribute-specific characteristics. In this paper we present AdaTag, which uses adaptive decoding to handle extraction. We parameterize the decoder with pretrained attribute embeddings, through a hypernetwork and a Mixture-of-Experts (MoE) module. This allows for separate, but semantically correlated, decoders to be generated on the fly for different attributes. This approach facilitates knowledge sharing, while maintaining the specificity of each attribute. Our experiments on a real-world e-Commerce dataset show marked improvements over previous methods.