 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPRINT: Semi-supervised Prototypical Representation for Few-Shot Class-Incremental Tabular Learning
Mar 04, 2026Real-world systems must continuously adapt to novel concepts from limited data without forgetting previously acquired knowledge. While Few-Shot Class-Incremental Learning (FSCIL) is established in computer vision, its application to tabular domains remains largely unexplored. Unlike images, tabular streams (e.g., logs, sensors) offer abundant unlabeled data, a scarcity of expert annotations and negligible storage costs, features ignored by existing vision-based methods that rely on restrictive buffers. We introduce SPRINT, the first FSCIL framework tailored for tabular distributions. SPRINT introduces a mixed episodic training strategy that leverages confidence-based pseudo-labeling to enrich novel class representations and exploits low storage costs to retain base class history. Extensive evaluation across six diverse benchmarks spanning cybersecurity, healthcare, and ecological domains, demonstrates SPRINT's cross-domain robustness. It achieves a state-of-the-art average accuracy of 77.37% (5-shot), outperforming the strongest incremental baseline by 4.45%.
Chasing Ghosts: A Simulation-to-Real Olfactory Navigation Stack with Optional Vision Augmentation
Feb 23, 2026Autonomous odor source localization remains a challenging problem for aerial robots due to turbulent airflow, sparse and delayed sensory signals, and strict payload and compute constraints. While prior unmanned aerial vehicle (UAV)-based olfaction systems have demonstrated gas distribution mapping or reactive plume tracing, they rely on predefined coverage patterns, external infrastructure, or extensive sensing and coordination. In this work, we present a complete, open-source UAV system for online odor source localization using a minimal sensor suite. The system integrates custom olfaction hardware, onboard sensing, and a learning-based navigation policy trained in simulation and deployed on a real quadrotor. Through our minimal framework, the UAV is able to navigate directly toward an odor source without constructing an explicit gas distribution map or relying on external positioning systems. Vision is incorporated as an optional complementary modality to accelerate navigation under certain conditions. We validate the proposed system through real-world flight experiments in a large indoor environment using an ethanol source, demonstrating consistent source-finding behavior under realistic airflow conditions. The primary contribution of this work is a reproducible system and methodological framework for UAV-based olfactory navigation and source finding under minimal sensing assumptions. We elaborate on our hardware design and open source our UAV firmware, simulation code, olfaction-vision dataset, and circuit board to the community. Code, data, and designs will be made available at https://github.com/KordelFranceTech/ChasingGhosts.
Vision Token Reduction via Attention-Driven Self-Compression for Efficient Multimodal Large Language Models
Feb 13, 2026Multimodal Large Language Models (MLLMs) incur significant computational cost from processing numerous vision tokens through all LLM layers. Prior pruning methods operate either before the LLM, limiting generality due to diverse encoder-projector designs or within the LLM using heuristics that are incompatible with FlashAttention. We take a different approach: rather than identifying unimportant tokens, we treat the LLM itself as the optimal guide for compression. Observing that deeper layers naturally transmit vision-to-text information, we introduce Attention-Driven Self-Compression (ADSC), a simple, broadly applicable method that progressively reduces vision tokens using only the LLM's attention mechanism. Our method applies uniform token downsampling at selected layers, forming bottlenecks that encourage the model to reorganize and compress information into the remaining tokens. It requires no score computation, auxiliary modules, or attention modification, and remains fully compatible with FlashAttention. Applied to LLaVA-1.5, ADSC reduces FLOPs by 53.7% and peak KV-cache memory by 56.7%, while preserving 98.2% of the original model performance. Across multiple benchmarks, it outperforms prior pruning approaches in both efficiency and accuracy. Crucially, under high compression ratios, our method remains robust while heuristic-based techniques degrade sharply.
PPSEBM: An Energy-Based Model with Progressive Parameter Selection for Continual Learning
Dec 17, 2025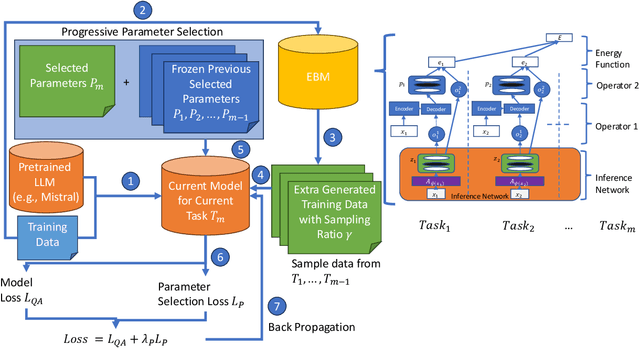
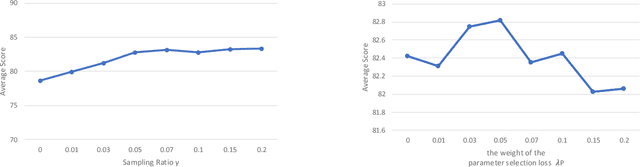
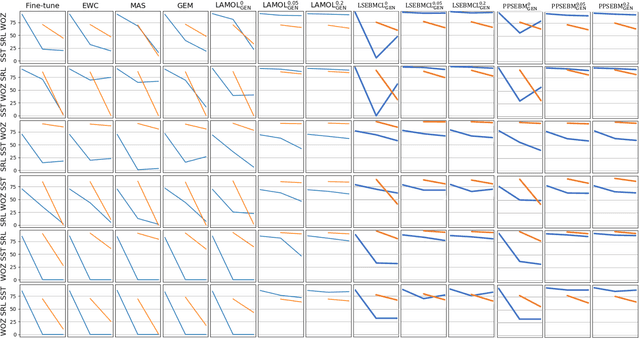
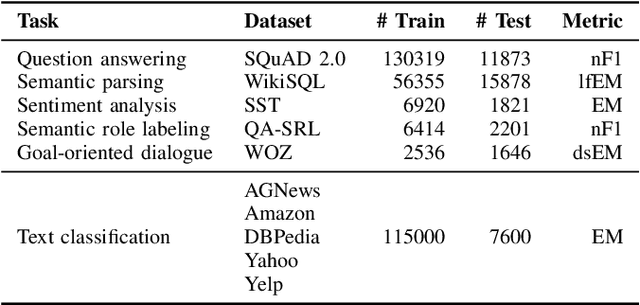
Continual learning remains a fundamental challenge in machine learning, requiring models to learn from a stream of tasks without forgetting previously acquired knowledge. A major obstacle in this setting is catastrophic forgetting, where performance on earlier tasks degrades as new tasks are learned. In this paper, we introduce PPSEBM, a novel framework that integrates an Energy-Based Model (EBM) with Progressive Parameter Selection (PPS) to effectively address catastrophic forgetting in continual learning for natural language processing tasks. In PPSEBM, progressive parameter selection allocates distinct, task-specific parameters for each new task, while the EBM generates representative pseudo-samples from prior tasks. These generated samples actively inform and guide the parameter selection process, enhancing the model's ability to retain past knowledge while adapting to new tasks. Experimental results on diverse NLP benchmarks demonstrate that PPSEBM outperforms state-of-the-art continual learning methods, offering a promising and robust solution to mitigate catastrophic forgetting.
Retrieval Augmented Generation-based Large Language Models for Bridging Transportation Cybersecurity Legal Knowledge Gaps
May 23, 2025As connected and automated transportation systems evolve, there is a growing need for federal and state authorities to revise existing laws and develop new statutes to address emerging cybersecurity and data privacy challenges. This study introduces a Retrieval-Augmented Generation (RAG) based Large Language Model (LLM) framework designed to support policymakers by extracting relevant legal content and generating accurate, inquiry-specific responses. The framework focuses on reducing hallucinations in LLMs by using a curated set of domain-specific questions to guide response generation. By incorporating retrieval mechanisms, the system enhances the factual grounding and specificity of its outputs. Our analysis shows that the proposed RAG-based LLM outperforms leading commercial LLMs across four evaluation metrics: AlignScore, ParaScore, BERTScore, and ROUGE, demonstrating its effectiveness in producing reliable and context-aware legal insights. This approach offers a scalable, AI-driven method for legislative analysis, supporting efforts to update legal frameworks in line with advancements in transportation technologies.
Graph-Based Re-ranking: Emerging Techniques, Limitations, and Opportunities
Mar 19, 2025Knowledge graphs have emerged to be promising datastore candidates for context augmentation during Retrieval Augmented Generation (RAG). As a result, techniques in graph representation learning have been simultaneously explored alongside principal neural information retrieval approaches, such as two-phased retrieval, also known as re-ranking. While Graph Neural Networks (GNNs) have been proposed to demonstrate proficiency in graph learning for re-ranking, there are ongoing limitations in modeling and evaluating input graph structures for training and evaluation for passage and document ranking tasks. In this survey, we review emerging GNN-based ranking model architectures along with their corresponding graph representation construction methodologies. We conclude by providing recommendations on future research based on community-wide challenges and opportunities.
LSEBMCL: A Latent Space Energy-Based Model for Continual Learning
Jan 09, 2025
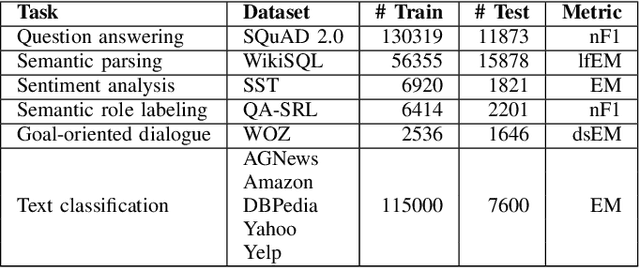
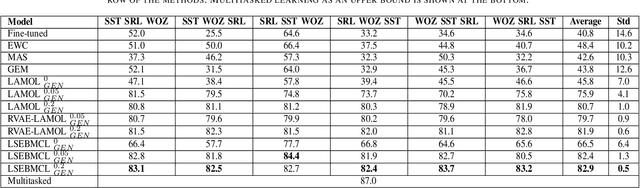

Continual learning has become essential in many practical applications such as online news summaries and product classification. The primary challenge is known as catastrophic forgetting, a phenomenon where a model inadvertently discards previously learned knowledge when it is trained on new tasks. Existing solutions involve storing exemplars from previous classes, regularizing parameters during the fine-tuning process, or assigning different model parameters to each task. The proposed solution LSEBMCL (Latent Space Energy-Based Model for Continual Learning) in this work is to use energy-based models (EBMs) to prevent catastrophic forgetting by sampling data points from previous tasks when training on new ones. The EBM is a machine learning model that associates an energy value with each input data point. The proposed method uses an EBM layer as an outer-generator in the continual learning framework for NLP tasks. The study demonstrates the efficacy of EBM in NLP tasks, achieving state-of-the-art results in all experiments.
ConfliBERT: A Language Model for Political Conflict
Dec 19, 2024



Conflict scholars have used rule-based approaches to extract information about political violence from news reports and texts. Recent Natural Language Processing developments move beyond rigid rule-based approaches. We review our recent ConfliBERT language model (Hu et al. 2022) to process political and violence related texts. The model can be used to extract actor and action classifications from texts about political conflict. When fine-tuned, results show that ConfliBERT has superior performance in accuracy, precision and recall over other large language models (LLM) like Google's Gemma 2 (9B), Meta's Llama 3.1 (7B), and Alibaba's Qwen 2.5 (14B) within its relevant domains. It is also hundreds of times faster than these more generalist LLMs. These results are illustrated using texts from the BBC, re3d, and the Global Terrorism Dataset (GTD).
Dynamic Environment Responsive Online Meta-Learning with Fairness Awareness
Feb 19, 2024



The fairness-aware online learning framework has emerged as a potent tool within the context of continuous lifelong learning. In this scenario, the learner's objective is to progressively acquire new tasks as they arrive over time, while also guaranteeing statistical parity among various protected sub-populations, such as race and gender, when it comes to the newly introduced tasks. A significant limitation of current approaches lies in their heavy reliance on the i.i.d (independent and identically distributed) assumption concerning data, leading to a static regret analysis of the framework. Nevertheless, it's crucial to note that achieving low static regret does not necessarily translate to strong performance in dynamic environments characterized by tasks sampled from diverse distributions. In this paper, to tackle the fairness-aware online learning challenge in evolving settings, we introduce a unique regret measure, FairSAR, by incorporating long-term fairness constraints into a strongly adapted loss regret framework. Moreover, to determine an optimal model parameter at each time step, we introduce an innovative adaptive fairness-aware online meta-learning algorithm, referred to as FairSAOML. This algorithm possesses the ability to adjust to dynamic environments by effectively managing bias control and model accuracy. The problem is framed as a bi-level convex-concave optimization, considering both the model's primal and dual parameters, which pertain to its accuracy and fairness attributes, respectively. Theoretical analysis yields sub-linear upper bounds for both loss regret and the cumulative violation of fairness constraints. Our experimental evaluation on various real-world datasets in dynamic environments demonstrates that our proposed FairSAOML algorithm consistently outperforms alternative approaches rooted in the most advanced prior online learning methods.
Fairness-Aware Domain Generalization under Covariate and Dependence Shifts
Nov 23, 2023


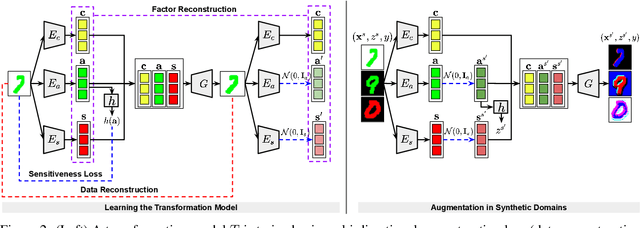
Achieving the generalization of an invariant classifier from source domains to shifted target domains while simultaneously considering model fairness is a substantial and complex challenge in machine learning. Existing domain generalization research typically attributes domain shifts to concept shift, which relates to alterations in class labels, and covariate shift, which pertains to variations in data styles. In this paper, by introducing another form of distribution shift, known as dependence shift, which involves variations in fair dependence patterns across domains, we propose a novel domain generalization approach that addresses domain shifts by considering both covariate and dependence shifts. We assert the existence of an underlying transformation model can transform data from one domain to another. By generating data in synthetic domains through the model, a fairness-aware invariant classifier is learned that enforces both model accuracy and fairness in unseen domains. Extensive empirical studies on four benchmark datasets demonstrate that our approach surpasses state-of-the-art methods.