 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Automated Vulnerability Detection Framework for Smart Contracts
Jan 20, 2023With the increase of the adoption of blockchain technology in providing decentralized solutions to various problems, smart contracts have become more popular to the point that billions of US Dollars are currently exchanged every day through such technology. Meanwhile, various vulnerabilities in smart contracts have been exploited by attackers to steal cryptocurrencies worth millions of dollars. The automatic detection of smart contract vulnerabilities therefore is an essential research problem. Existing solutions to this problem particularly rely on human experts to define features or different rules to detect vulnerabilities. However, this often causes many vulnerabilities to be ignored, and they are inefficient in detecting new vulnerabilities. In this study, to overcome such challenges, we propose a framework to automatically detect vulnerabilities in smart contracts on the blockchain. More specifically, first, we utilize novel feature vector generation techniques from bytecode of smart contract since the source code of smart contracts are rarely available in public. Next, the collected vectors are fed into our novel metric learning-based deep neural network(DNN) to get the detection result. We conduct comprehensive experiments on large-scale benchmarks, and the quantitative results demonstrate the effectiveness and efficiency of our approach.
PDFM: A Primal-Dual Fairness-Aware Framework for Meta-learning
Oct 05, 2020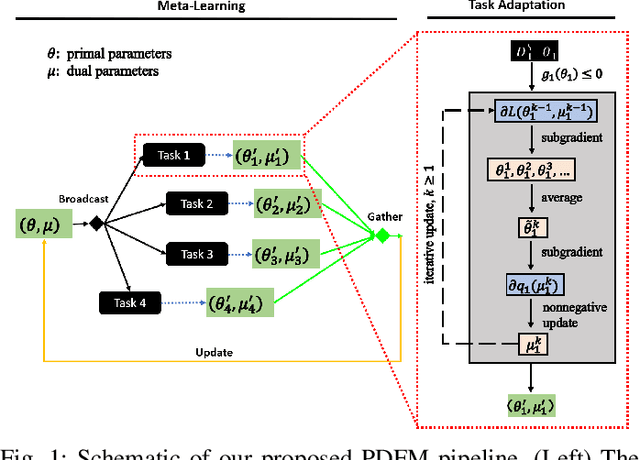
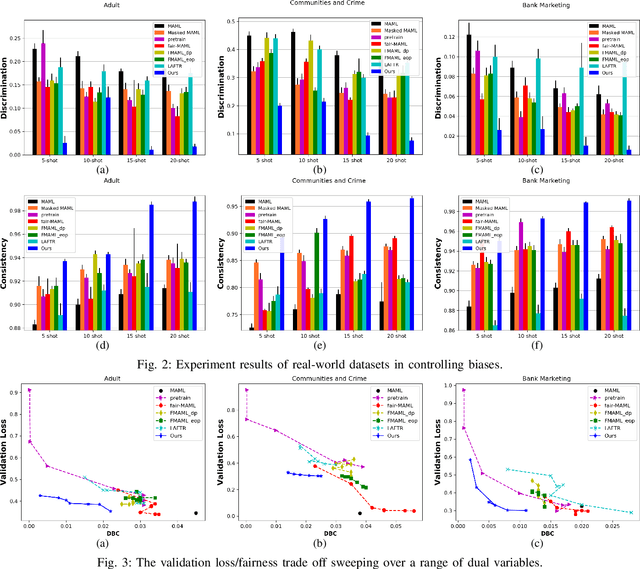
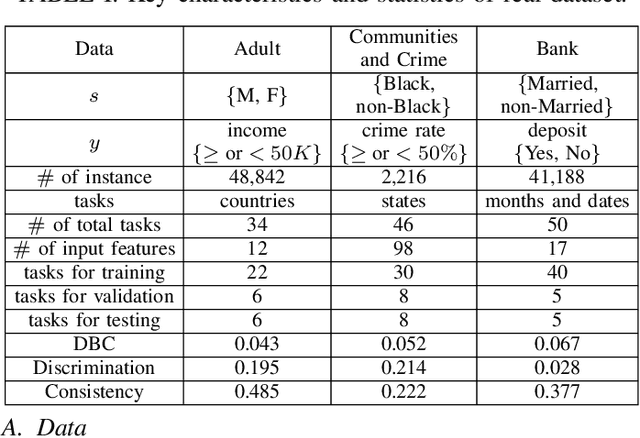

The problem of learning to generalize to unseen classes during training, known as few-shot classification, has attracted considerable attention. Initialization based methods, such as the gradient-based model agnostic meta-learning (MAML), tackle the few-shot learning problem by "learning to fine-tune". The goal of these approaches is to learn proper model initialization, so that the classifiers for new classes can be learned from a few labeled examples with a small number of gradient update steps. Few shot meta-learning is well-known with its fast-adapted capability and accuracy generalization onto unseen tasks. Learning fairly with unbiased outcomes is another significant hallmark of human intelligence, which is rarely touched in few-shot meta-learning. In this work, we propose a Primal-Dual Fair Meta-learning framework, namely PDFM, which learns to train fair machine learning models using only a few examples based on data from related tasks. The key idea is to learn a good initialization of a fair model's primal and dual parameters so that it can adapt to a new fair learning task via a few gradient update steps. Instead of manually tuning the dual parameters as hyperparameters via a grid search, PDFM optimizes the initialization of the primal and dual parameters jointly for fair meta-learning via a subgradient primal-dual approach. We further instantiate examples of bias controlling using mean difference and decision boundary covariance as fairness constraints to each task for supervised regression and classification, respectively. We demonstrate the versatility of our proposed approach by applying our approach to various real-world datasets. Our experiments show substantial improvements over the best prior work for this setting.
Co-Representation Learning For Classification and Novel Class Detection via Deep Networks
Nov 13, 2018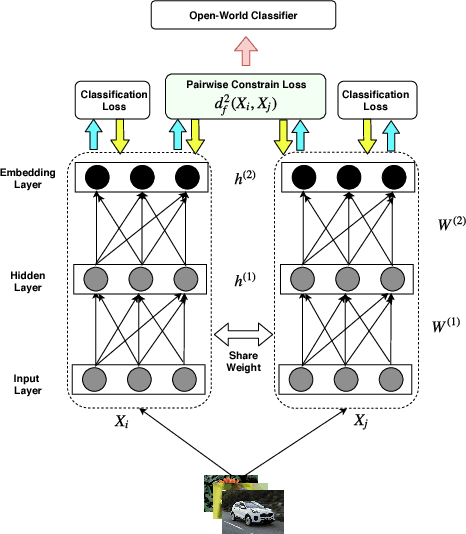
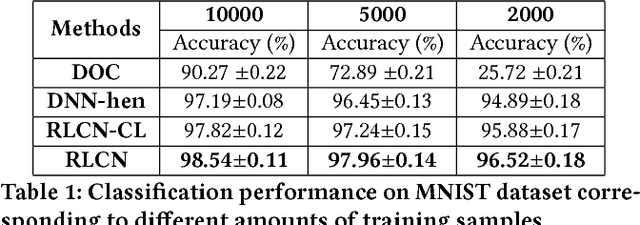
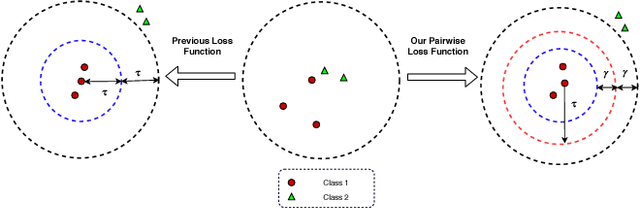
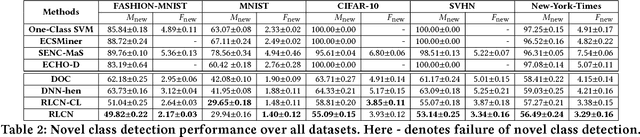
Deep Neural Network (DNN) has been largely demonstrated to be effective for closed-world classification problems where the total number of classes are known in advance. However, when the total number of classes that may occur during test time is unknown, DNNs notorious fail, i.e., DNN will make incorrect label prediction on instances from novel or unseen classes. This severely limits its utility in many real-world web applications, particularly when data occurs as a continuous stream. In this paper, we focus on addressing this key challenge by developing a two-channel DNN based co-representation learning framework that not only predicts instances from known classes, but also detects and adapts to the occurrence of novel class instances over time. Concretely, we propose a metric learning method using pairwise-constraint loss (PCL) function to learn a feature representation where intra-class compactness and inter-class separation is achieved. Moreover, we apply the temperature scaling scheme on the softmax function to replace traditional softmax output and design an open-world classifier. Our extensive empirical evaluation on benchmark datasets demonstrates the effectiveness of our framework compared to other competing techniques.
Adaptive Image Stream Classification via Convolutional Neural Network with Intrinsic Similarity Metrics
Sep 27, 2018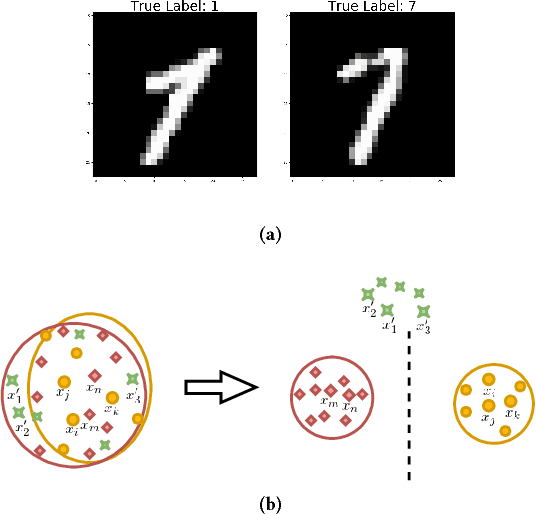

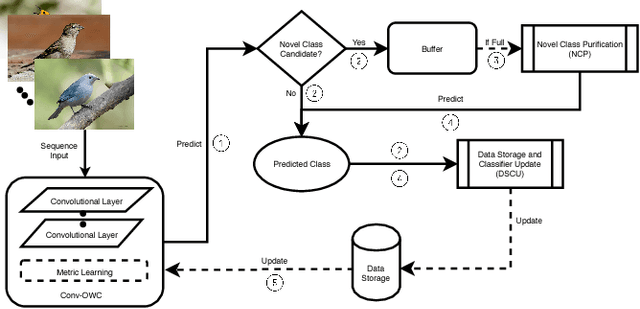
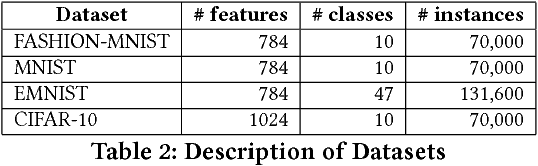
When performing data classification over a stream of continuously occurring instances, a key challenge is to develop an open-world classifier that anticipates instances from an unknown class. Studies addressing this problem, typically called novel class detection, have considered classification methods that reactively adapt to such changes along the stream. Importantly, they rely on the property of cohesion and separation among instances in feature space. Instances belonging to the same class are assumed to be closer to each other (cohesion) than those belonging to different classes (separation). Unfortunately, this assumption may not have large support when dealing with high dimensional data such as images. In this paper, we address this key challenge by proposing a semisupervised multi-task learning framework called CSIM which aims to intrinsically search for a latent space suitable for detecting labels of instances from both known and unknown classes. Particularly, we utilize a convolution neural network layer that aids in the learning of a latent feature space suitable for novel class detection. We empirically measure the performance of CSIM over multiple realworld image datasets and demonstrate its superiority by comparing its performance with existing semi-supervised methods.