 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDFM: A Primal-Dual Fairness-Aware Framework for Meta-learning
Paper and Code
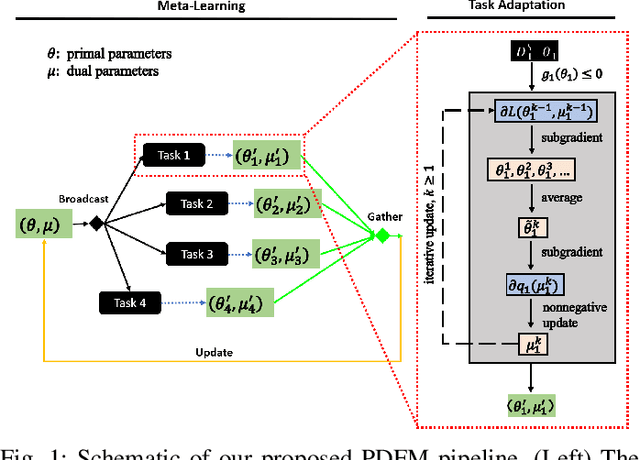
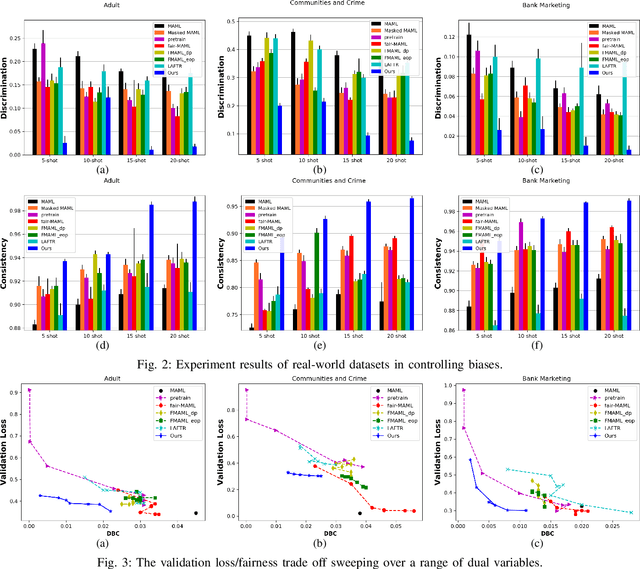
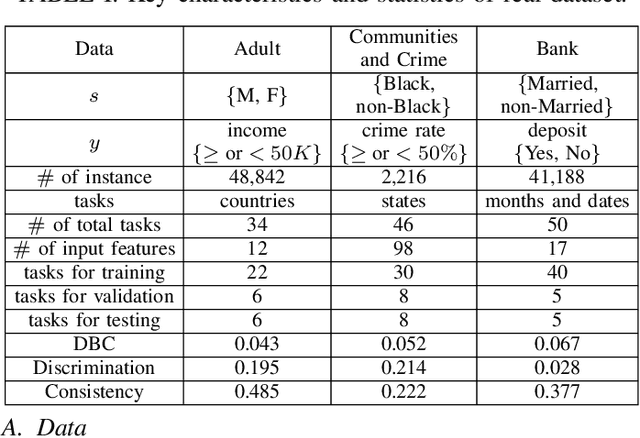

The problem of learning to generalize to unseen classes during training, known as few-shot classification, has attracted considerable attention. Initialization based methods, such as the gradient-based model agnostic meta-learning (MAML), tackle the few-shot learning problem by "learning to fine-tune". The goal of these approaches is to learn proper model initialization, so that the classifiers for new classes can be learned from a few labeled examples with a small number of gradient update steps. Few shot meta-learning is well-known with its fast-adapted capability and accuracy generalization onto unseen tasks. Learning fairly with unbiased outcomes is another significant hallmark of human intelligence, which is rarely touched in few-shot meta-learning. In this work, we propose a Primal-Dual Fair Meta-learning framework, namely PDFM, which learns to train fair machine learning models using only a few examples based on data from related tasks. The key idea is to learn a good initialization of a fair model's primal and dual parameters so that it can adapt to a new fair learning task via a few gradient update steps. Instead of manually tuning the dual parameters as hyperparameters via a grid search, PDFM optimizes the initialization of the primal and dual parameters jointly for fair meta-learning via a subgradient primal-dual approach. We further instantiate examples of bias controlling using mean difference and decision boundary covariance as fairness constraints to each task for supervised regression and classification, respectively. We demonstrate the versatility of our proposed approach by applying our approach to various real-world datasets. Our experiments show substantial improvements over the best prior work for this setting.