 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Re-ranking: Emerging Techniques, Limitations, and Opportunities
Mar 19, 2025Knowledge graphs have emerged to be promising datastore candidates for context augmentation during Retrieval Augmented Generation (RAG). As a result, techniques in graph representation learning have been simultaneously explored alongside principal neural information retrieval approaches, such as two-phased retrieval, also known as re-ranking. While Graph Neural Networks (GNNs) have been proposed to demonstrate proficiency in graph learning for re-ranking, there are ongoing limitations in modeling and evaluating input graph structures for training and evaluation for passage and document ranking tasks. In this survey, we review emerging GNN-based ranking model architectures along with their corresponding graph representation construction methodologies. We conclude by providing recommendations on future research based on community-wide challenges and opportunities.
FABULA: Intelligence Report Generation Using Retrieval-Augmented Narrative Construction
Oct 20, 2023
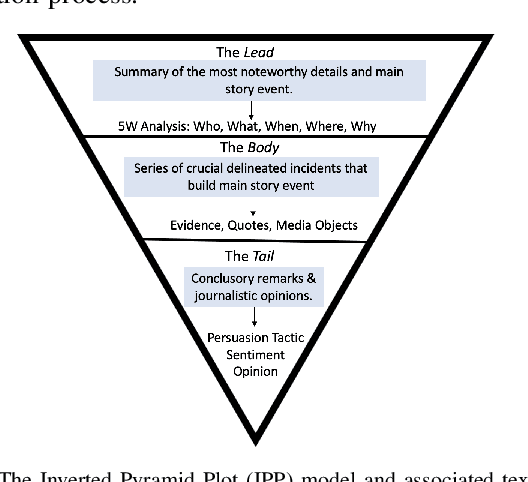


Narrative construction is the process of representing disparate event information into a logical plot structure that models an end to end story. Intelligence analysis is an example of a domain that can benefit tremendously from narrative construction techniques, particularly in aiding analysts during the largely manual and costly process of synthesizing event information into comprehensive intelligence reports. Manual intelligence report generation is often prone to challenges such as integrating dynamic event information, writing fine-grained queries, and closing information gaps. This motivates the development of a system that retrieves and represents critical aspects of events in a form that aids in automatic generation of intelligence reports. We introduce a Retrieval Augmented Generation (RAG) approach to augment prompting of an autoregressive decoder by retrieving structured information asserted in a knowledge graph to generate targeted information based on a narrative plot model. We apply our approach to the problem of neural intelligence report generation and introduce FABULA, framework to augment intelligence analysis workflows using RAG. An analyst can use FABULA to query an Event Plot Graph (EPG) to retrieve relevant event plot points, which can be used to augment prompting of a Large Language Model (LLM) during intelligence report generation. Our evaluation studies show that the plot points included in the generated intelligence reports have high semantic relevance, high coherency, and low data redundancy.
Scaling Studies for Efficient Parameter Search and Parallelism for Large Language Model Pre-training
Oct 11, 2023
AI accelerator processing capabilities and memory constraints largely dictate the scale in which machine learning workloads (e.g., training and inference) can be executed within a desirable time frame. Training a state of the art, transformer-based model today requires use of GPU-accelerated high performance computers with high-speed interconnects. As datasets and models continue to increase in size, computational requirements and memory demands for AI also continue to grow. These challenges have inspired the development of distributed algorithm and circuit-based optimization techniques that enable the ability to progressively scale models in multi-node environments, efficiently minimize neural network cost functions for faster convergence, and store more parameters into a set number of available resources. In our research project, we focus on parallel and distributed machine learning algorithm development, specifically for optimizing the data processing and pre-training of a set of 5 encoder-decoder LLMs, ranging from 580 million parameters to 13 billion parameters. We performed a fine-grained study to quantify the relationships between three ML parallelism methods, specifically exploring Microsoft DeepSpeed Zero Redundancy Optimizer (ZeRO) stages.
Recognizing and Extracting Cybersecurtity-relevant Entities from Text
Aug 02, 2022

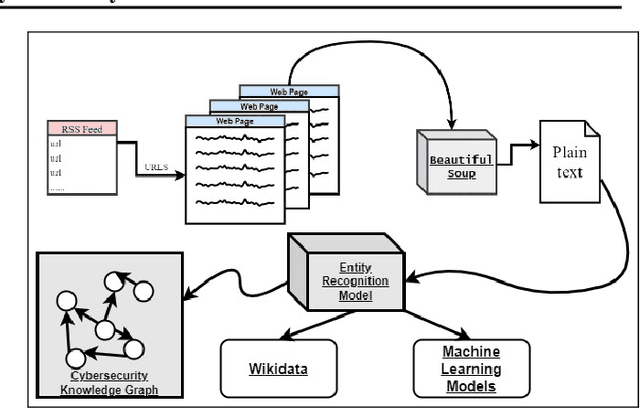
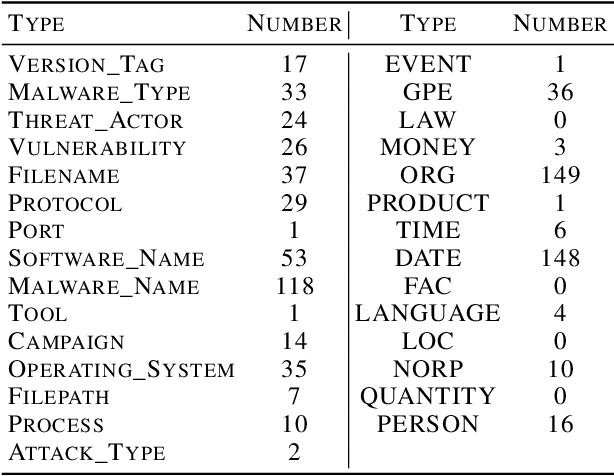
Cyber Threat Intelligence (CTI) is information describing threat vectors, vulnerabilities, and attacks and is often used as training data for AI-based cyber defense systems such as Cybersecurity Knowledge Graphs (CKG). There is a strong need to develop community-accessible datasets to train existing AI-based cybersecurity pipelines to efficiently and accurately extract meaningful insights from CTI. We have created an initial unstructured CTI corpus from a variety of open sources that we are using to train and test cybersecurity entity models using the spaCy framework and exploring self-learning methods to automatically recognize cybersecurity entities. We also describe methods to apply cybersecurity domain entity linking with existing world knowledge from Wikidata. Our future work will survey and test spaCy NLP tools and create methods for continuous integration of new information extracted from text.
Generating Fake Cyber Threat Intelligence Using Transformer-Based Models
Feb 08, 2021
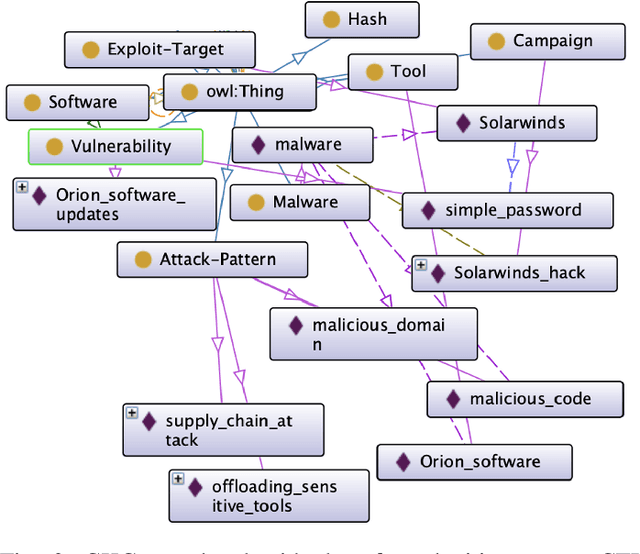


Cyber-defense systems are being developed to automatically ingest Cyber Threat Intelligence (CTI) that contains semi-structured data and/or text to populate knowledge graphs. A potential risk is that fake CTI can be generated and spread through Open-Source Intelligence (OSINT) communities or on the Web to effect a data poisoning attack on these systems. Adversaries can use fake CTI examples as training input to subvert cyber defense systems, forcing the model to learn incorrect inputs to serve their malicious needs. In this paper, we automatically generate fake CTI text descriptions using transformers. We show that given an initial prompt sentence, a public language model like GPT-2 with fine-tuning, can generate plausible CTI text with the ability of corrupting cyber-defense systems. We utilize the generated fake CTI text to perform a data poisoning attack on a Cybersecurity Knowledge Graph (CKG) and a cybersecurity corpus. The poisoning attack introduced adverse impacts such as returning incorrect reasoning outputs, representation poisoning, and corruption of other dependent AI-based cyber defense systems. We evaluate with traditional approaches and conduct a human evaluation study with cybersecurity professionals and threat hunters. Based on the study, professional threat hunters were equally likely to consider our fake generated CTI as true.
Using Deep Neural Networks to Translate Multi-lingual Threat Intelligence
Jul 19, 2018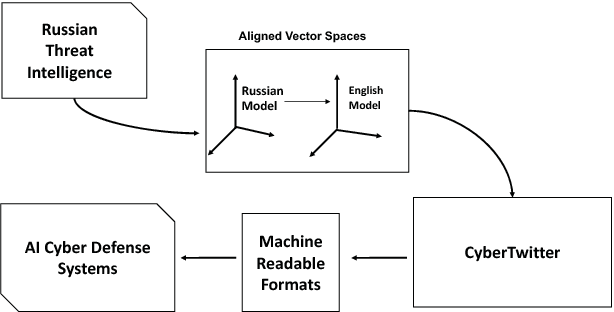



The multilingual nature of the Internet increases complications in the cybersecurity community's ongoing efforts to strategically mine threat intelligence from OSINT data on the web. OSINT sources such as social media, blogs, and dark web vulnerability markets exist in diverse languages and hinder security analysts, who are unable to draw conclusions from intelligence in languages they don't understand. Although third party translation engines are growing stronger, they are unsuited for private security environments. First, sensitive intelligence is not a permitted input to third party engines due to privacy and confidentiality policies. In addition, third party engines produce generalized translations that tend to lack exclusive cybersecurity terminology. In this paper, we address these issues and describe our system that enables threat intelligence understanding across unfamiliar languages. We create a neural network based system that takes in cybersecurity data in a different language and outputs the respective English translation. The English translation can then be understood by an analyst, and can also serve as input to an AI based cyber-defense system that can take mitigative action. As a proof of concept, we have created a pipeline which takes Russian threats and generates its corresponding English, RDF, and vectorized representations. Our network optimizes translations on specifically, cybersecurity data.