 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Entity Linking System for Tables in Scientific Literature
Jun 12, 2023



Entity linking is an important step towards constructing knowledge graphs that facilitate advanced question answering over scientific documents, including the retrieval of relevant information included in tables within these documents. This paper introduces a general-purpose system for linking entities to items in the Wikidata knowledge base. It describes how we adapt this system for linking domain-specific entities, especially for those entities embedded within tables drawn from COVID-19-related scientific literature. We describe the setup of an efficient offline instance of the system that enables our entity-linking approach to be more feasible in practice. As part of a broader approach to infer the semantic meaning of scientific tables, we leverage the structural and semantic characteristics of the tables to improve overall entity linking performance.
CAPD: A Context-Aware, Policy-Driven Framework for Secure and Resilient IoBT Operations
Aug 02, 2022The Internet of Battlefield Things (IoBT) will advance the operational effectiveness of infantry units. However, this requires autonomous assets such as sensors, drones, combat equipment, and uncrewed vehicles to collaborate, securely share information, and be resilient to adversary attacks in contested multi-domain operations. CAPD addresses this problem by providing a context-aware, policy-driven framework supporting data and knowledge exchange among autonomous entities in a battlespace. We propose an IoBT ontology that facilitates controlled information sharing to enable semantic interoperability between systems. Its key contributions include providing a knowledge graph with a shared semantic schema, integration with background knowledge, efficient mechanisms for enforcing data consistency and drawing inferences, and supporting attribute-based access control. The sensors in the IoBT provide data that create populated knowledge graphs based on the ontology. This paper describes using CAPD to detect and mitigate adversary actions. CAPD enables situational awareness using reasoning over the sensed data and SPARQL queries. For example, adversaries can cause sensor failure or hijacking and disrupt the tactical networks to degrade video surveillance. In such instances, CAPD uses an ontology-based reasoner to see how alternative approaches can still support the mission. Depending on bandwidth availability, the reasoner initiates the creation of a reduced frame rate grayscale video by active transcoding or transmits only still images. This ability to reason over the mission sensed environment and attack context permits the autonomous IoBT system to exhibit resilience in contested conditions.
Recognizing and Extracting Cybersecurtity-relevant Entities from Text
Aug 02, 2022

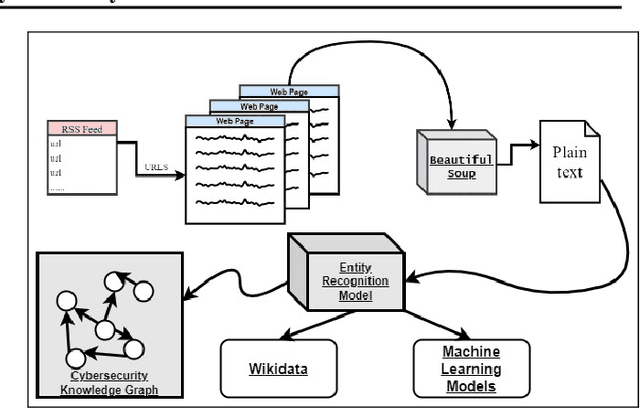
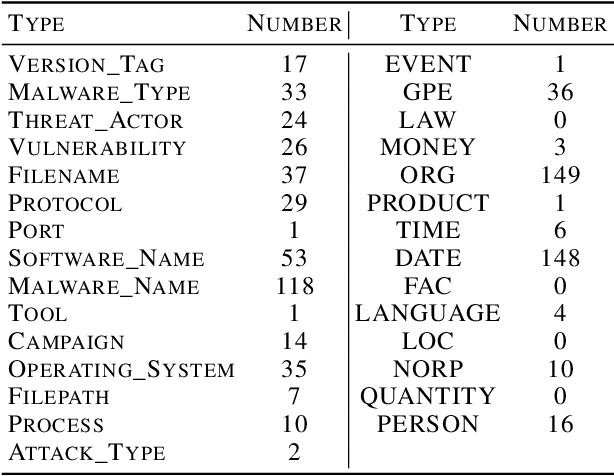
Cyber Threat Intelligence (CTI) is information describing threat vectors, vulnerabilities, and attacks and is often used as training data for AI-based cyber defense systems such as Cybersecurity Knowledge Graphs (CKG). There is a strong need to develop community-accessible datasets to train existing AI-based cybersecurity pipelines to efficiently and accurately extract meaningful insights from CTI. We have created an initial unstructured CTI corpus from a variety of open sources that we are using to train and test cybersecurity entity models using the spaCy framework and exploring self-learning methods to automatically recognize cybersecurity entities. We also describe methods to apply cybersecurity domain entity linking with existing world knowledge from Wikidata. Our future work will survey and test spaCy NLP tools and create methods for continuous integration of new information extracted from text.
Generating Fake Cyber Threat Intelligence Using Transformer-Based Models
Feb 08, 2021
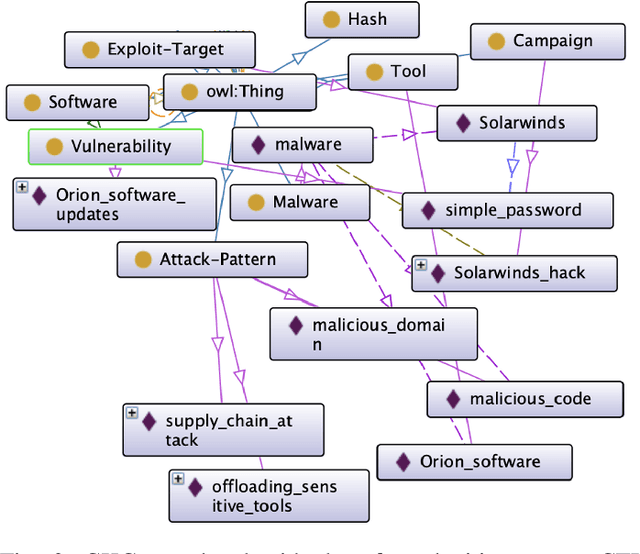


Cyber-defense systems are being developed to automatically ingest Cyber Threat Intelligence (CTI) that contains semi-structured data and/or text to populate knowledge graphs. A potential risk is that fake CTI can be generated and spread through Open-Source Intelligence (OSINT) communities or on the Web to effect a data poisoning attack on these systems. Adversaries can use fake CTI examples as training input to subvert cyber defense systems, forcing the model to learn incorrect inputs to serve their malicious needs. In this paper, we automatically generate fake CTI text descriptions using transformers. We show that given an initial prompt sentence, a public language model like GPT-2 with fine-tuning, can generate plausible CTI text with the ability of corrupting cyber-defense systems. We utilize the generated fake CTI text to perform a data poisoning attack on a Cybersecurity Knowledge Graph (CKG) and a cybersecurity corpus. The poisoning attack introduced adverse impacts such as returning incorrect reasoning outputs, representation poisoning, and corruption of other dependent AI-based cyber defense systems. We evaluate with traditional approaches and conduct a human evaluation study with cybersecurity professionals and threat hunters. Based on the study, professional threat hunters were equally likely to consider our fake generated CTI as true.
An Ensemble Approach for Compressive Sensing with Quantum
Jun 08, 2020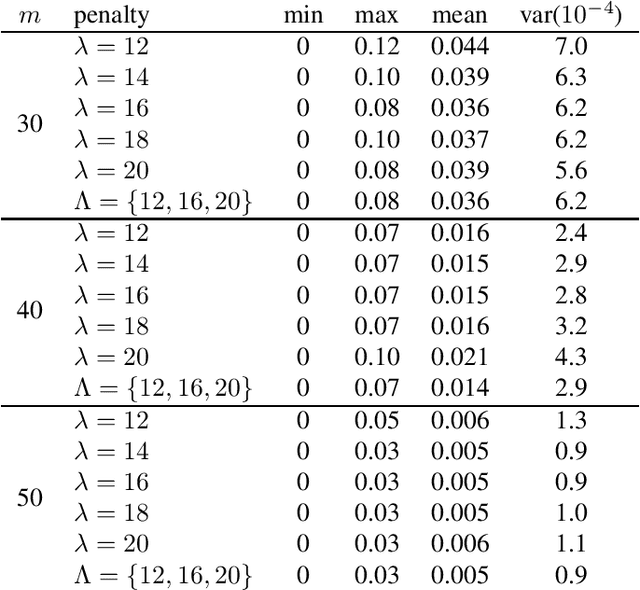
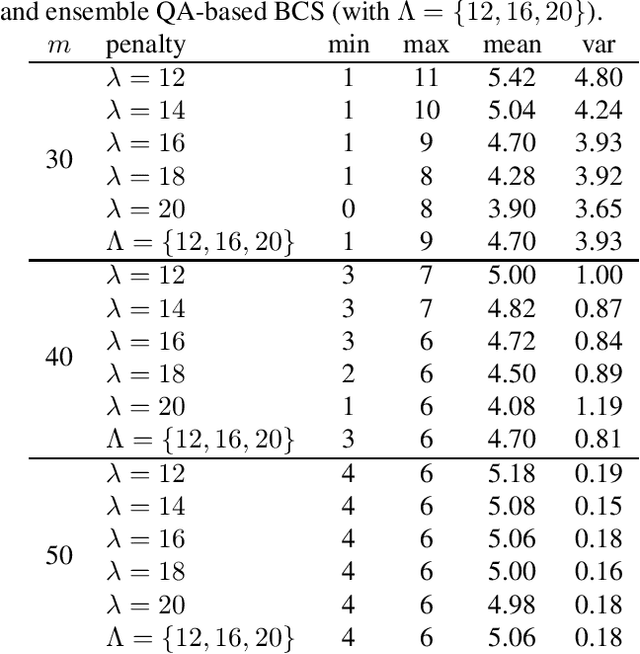
We leverage the idea of a statistical ensemble to improve the quality of quantum annealing based binary compressive sensing. Since executing quantum machine instructions on a quantum annealer can result in an excited state, rather than the ground state of the given Hamiltonian, we use different penalty parameters to generate multiple distinct quadratic unconstrained binary optimization (QUBO) functions whose ground state(s) represent a potential solution of the original problem. We then employ the attained samples from minimizing all corresponding (different) QUBOs to estimate the solution of the problem of binary compressive sensing. Our experiments, on a D-Wave 2000Q quantum processor, demonstrated that the proposed ensemble scheme is notably less sensitive to the calibration of the penalty parameter that controls the trade-off between the feasibility and sparsity of recoveries.
Improving Neural Named Entity Recognition with Gazetteers
Mar 06, 2020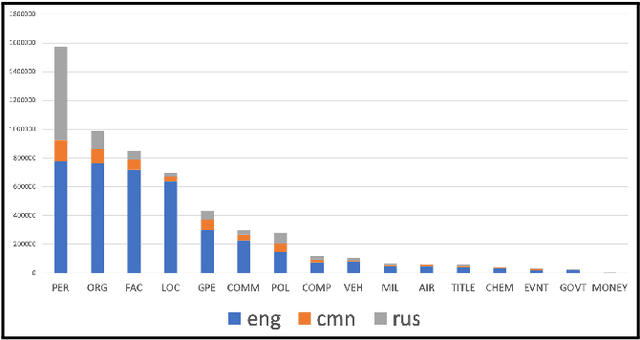
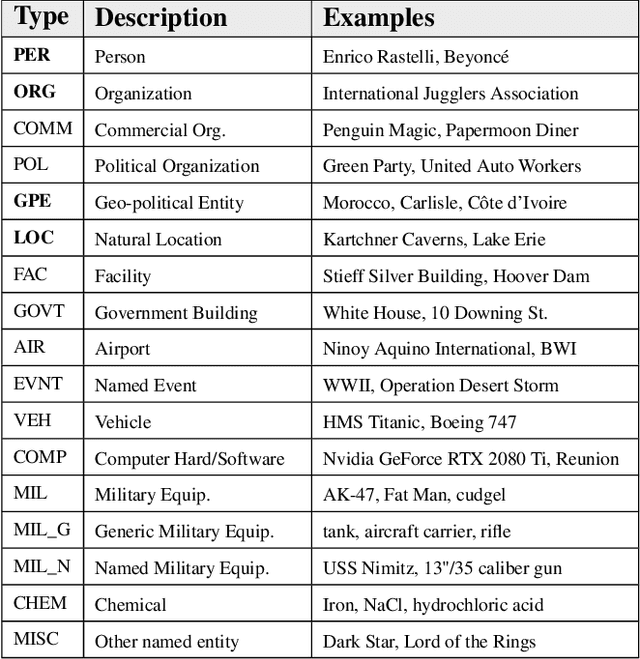
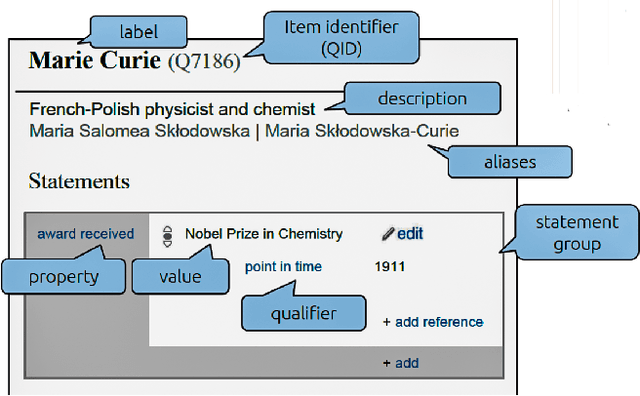
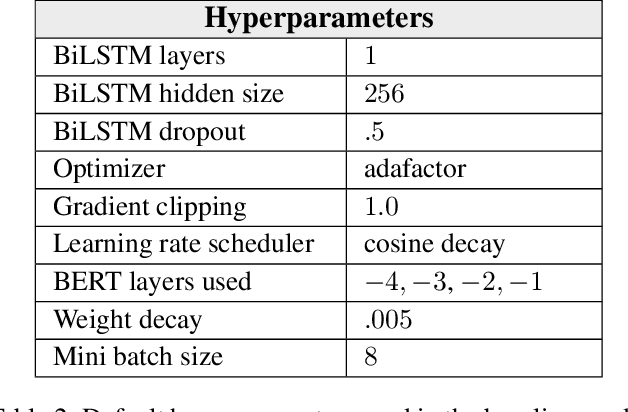
The goal of this work is to improve the performance of a neural named entity recognition system by adding input features that indicate a word is part of a name included in a gazetteer. This article describes how to generate gazetteers from the Wikidata knowledge graph as well as how to integrate the information into a neural NER system. Experiments reveal that the approach yields performance gains in two distinct languages: a high-resource, word-based language, English and a high-resource, character-based language, Chinese. Experiments were also performed in a low-resource language, Russian on a newly annotated Russian NER corpus from Reddit tagged with four core types and twelve extended types. This article reports a baseline score. It is a longer version of a paper in the 33rd FLAIRS conference (Song et al. 2020).
Reinforcement Quantum Annealing: A Quantum-Assisted Learning Automata Approach
Jan 01, 2020


We introduce the reinforcement quantum annealing (RQA) scheme in which an intelligent agent interacts with a quantum annealer that plays the stochastic environment role of learning automata and tries to iteratively find better Ising Hamiltonians for the given problem of interest. As a proof-of-concept, we propose a novel approach for reducing the NP-complete problem of Boolean satisfiability (SAT) to minimizing Ising Hamiltonians and show how to apply the RQA for increasing the probability of finding the global optimum. Our experimental results on two different benchmark SAT problems (namely factoring pseudo-prime numbers and random SAT with phase transitions), using a D-Wave 2000Q quantum processor, demonstrated that RQA finds notably better solutions with fewer samples, compared to state-of-the-art techniques in the realm of quantum annealing.
Unfolding the Structure of a Document using Deep Learning
Sep 29, 2019


Understanding and extracting of information from large documents, such as business opportunities, academic articles, medical documents and technical reports, poses challenges not present in short documents. Such large documents may be multi-themed, complex, noisy and cover diverse topics. We describe a framework that can analyze large documents and help people and computer systems locate desired information in them. We aim to automatically identify and classify different sections of documents and understand their purpose within the document. A key contribution of our research is modeling and extracting the logical and semantic structure of electronic documents using deep learning techniques. We evaluate the effectiveness and robustness of our framework through extensive experiments on two collections: more than one million scholarly articles from arXiv and a collection of requests for proposal documents from government sources.
Cyber-All-Intel: An AI for Security related Threat Intelligence
May 07, 2019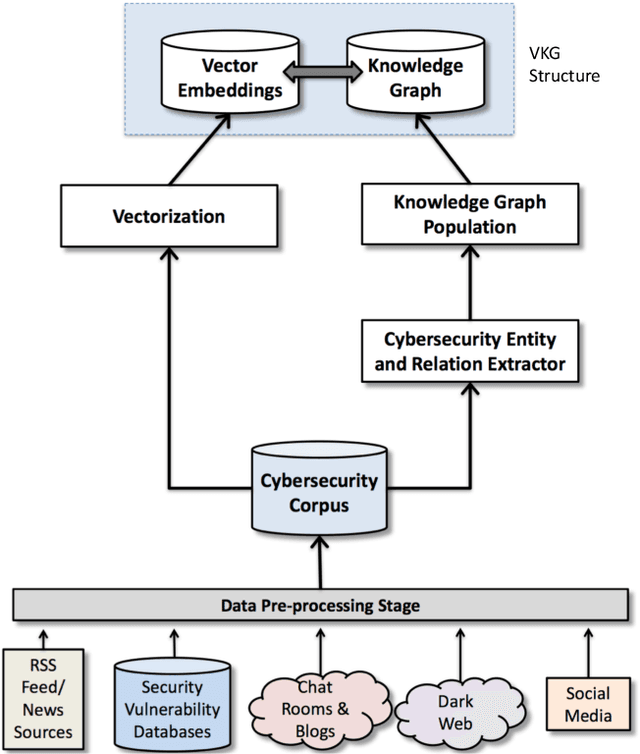


Keeping up with threat intelligence is a must for a security analyst today. There is a volume of information present in `the wild' that affects an organization. We need to develop an artificial intelligence system that scours the intelligence sources, to keep the analyst updated about various threats that pose a risk to her organization. A security analyst who is better `tapped in' can be more effective. In this paper we present, Cyber-All-Intel an artificial intelligence system to aid a security analyst. It is a system for knowledge extraction, representation and analytics in an end-to-end pipeline grounded in the cybersecurity informatics domain. It uses multiple knowledge representations like, vector spaces and knowledge graphs in a 'VKG structure' to store incoming intelligence. The system also uses neural network models to pro-actively improve its knowledge. We have also created a query engine and an alert system that can be used by an analyst to find actionable cybersecurity insights.
Knowledge Graph Fact Prediction via Knowledge-Enriched Tensor Factorization
Feb 08, 2019
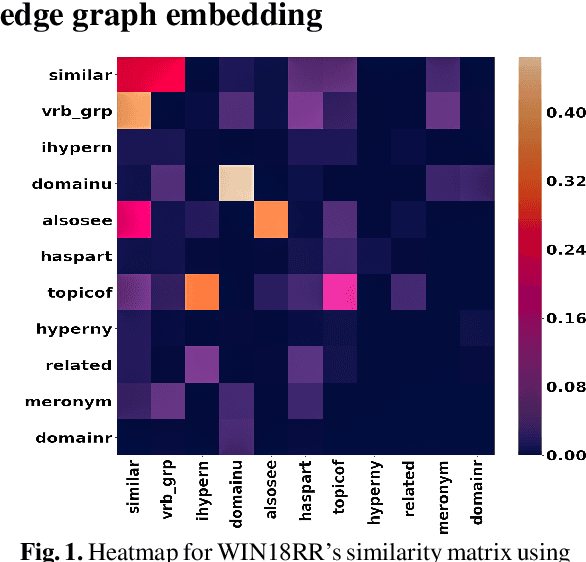
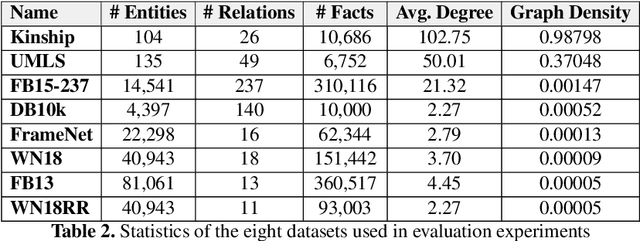
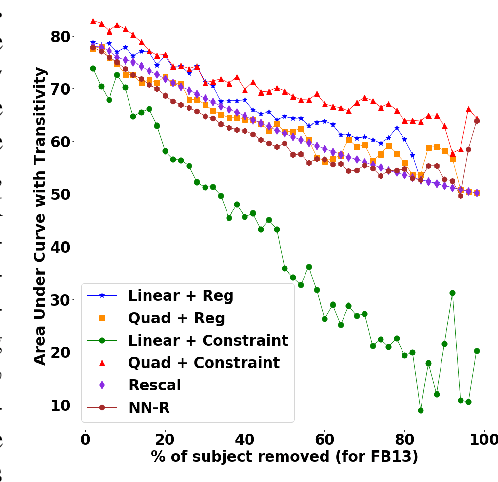
We present a family of novel methods for embedding knowledge graphs into real-valued tensors. These tensor-based embeddings capture the ordered relations that are typical in the knowledge graphs represented by semantic web languages like RDF. Unlike many previous models, our methods can easily use prior background knowledge provided by users or extracted automatically from existing knowledge graphs. In addition to providing more robust methods for knowledge graph embedding, we provide a provably-convergent, linear tensor factorization algorithm. We demonstrate the efficacy of our models for the task of predicting new facts across eight different knowledge graphs, achieving between 5% and 50% relative improvement over existing state-of-the-art knowledge graph embedding techniques. Our empirical evaluation shows that all of the tensor decomposition models perform well when the average degree of an entity in a graph is high, with constraint-based models doing better on graphs with a small number of highly similar relations and regularization-based models dominating for graphs with relations of varying degrees of similarity.