 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Entity Linking System for Tables in Scientific Literature
Jun 12, 2023



Entity linking is an important step towards constructing knowledge graphs that facilitate advanced question answering over scientific documents, including the retrieval of relevant information included in tables within these documents. This paper introduces a general-purpose system for linking entities to items in the Wikidata knowledge base. It describes how we adapt this system for linking domain-specific entities, especially for those entities embedded within tables drawn from COVID-19-related scientific literature. We describe the setup of an efficient offline instance of the system that enables our entity-linking approach to be more feasible in practice. As part of a broader approach to infer the semantic meaning of scientific tables, we leverage the structural and semantic characteristics of the tables to improve overall entity linking performance.
Extracting Semantics from Maintenance Records
Aug 11, 2021

Rapid progress in natural language processing has led to its utilization in a variety of industrial and enterprise settings, including in its use for information extraction, specifically named entity recognition and relation extraction, from documents such as engineering manuals and field maintenance reports. While named entity recognition is a well-studied problem, existing state-of-the-art approaches require large labelled datasets which are hard to acquire for sensitive data such as maintenance records. Further, industrial domain experts tend to distrust results from black box machine learning models, especially when the extracted information is used in downstream predictive maintenance analytics. We overcome these challenges by developing three approaches built on the foundation of domain expert knowledge captured in dictionaries and ontologies. We develop a syntactic and semantic rules-based approach and an approach leveraging a pre-trained language model, fine-tuned for a question-answering task on top of our base dictionary lookup to extract entities of interest from maintenance records. We also develop a preliminary ontology to represent and capture the semantics of maintenance records. Our evaluations on a real-world aviation maintenance records dataset show promising results and help identify challenges specific to named entity recognition in the context of noisy industrial data.
SemTK: An Ontology-first, Open Source Semantic Toolkit for Managing and Querying Knowledge Graphs
Jun 02, 2018


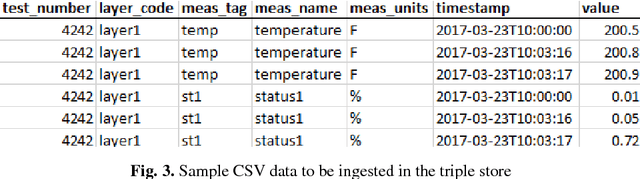
The relatively recent adoption of Knowledge Graphs as an enabling technology in multiple high-profile artificial intelligence and cognitive applications has led to growing interest in the Semantic Web technology stack. Many semantics-related tools, however, are focused on serving experts with a deep understanding of semantic technologies. For example, triplification of relational data is available but there is no open source tool that allows a user unfamiliar with OWL/RDF to import data into a semantic triple store in an intuitive manner. Further, many tools require users to have a working understanding of SPARQL to query data. Casual users interested in benefiting from the power of Knowledge Graphs have few tools available for exploring, querying, and managing semantic data. We present SemTK, the Semantics Toolkit, a user-friendly suite of tools that allow both expert and non-expert semantics users convenient ingestion of relational data, simplified query generation, and more. The exploration of ontologies and instance data is performed through SPARQLgraph, an intuitive web-based user interface in SemTK understandable and navigable by a lay user. The open source version of SemTK is available at http://semtk.research.ge.com